hadoop学习笔记(一):NameNade持久化和DataNode概念

其中的fsimage 称为时点备份,又叫磁盘镜像快照,这个是NameNode的一个
持久化的方式之一:缺点,在内存数据序列化的时候比较慢
具体的过程:因为我们所知道的NameNode一般是存储在内存中的,并没有和磁盘进行交互,这和redis这类的非关系型数据库差不多,但是内存中的数据总是没有持久化的,那么怎么去持久化呢?就比如我们的NameNode结点数据的持久化过程:先将内存中的数据序列化为二进制字节流,之后将其通过IO的形式存入到计算机的文件系统中,就完成了持久化的过程,具体的如果NameNode需要数据的过程的时候,需要将外存中的字节码文件,反序列化,之后加载到内存中,就可以供NameNode使用了
注意点:时点快照:只会按规定的间隔一段时间之后再去持久化到外存中,如13点,15点,17点。。。。而不是每一秒都在进行持久化,因为这样的话又会频繁的和外存也就是磁盘进行交互,这样数据的获取的时间就会很长了

持久化的方式之二:缺点,在数据存入外存的过程不慢,但是当存外存恢复到内存的时候比较慢
edits记录对metadata的操作日志。。。>Redis
即日志编辑方式:1)数据存入外村会将客户端对服务器中的任何的一条指令都写入到操作日志log这个文件当中 2)数据从外存加载到内存中:直接再执行一遍log中的指令即可。
此方式也是时隔一段规定的时间才回去持久化,而不是实时的
********Hadoop集群中NameNode的信息一般的是将这两个结合起来持久化的
下面是具体的持久化 的过程:
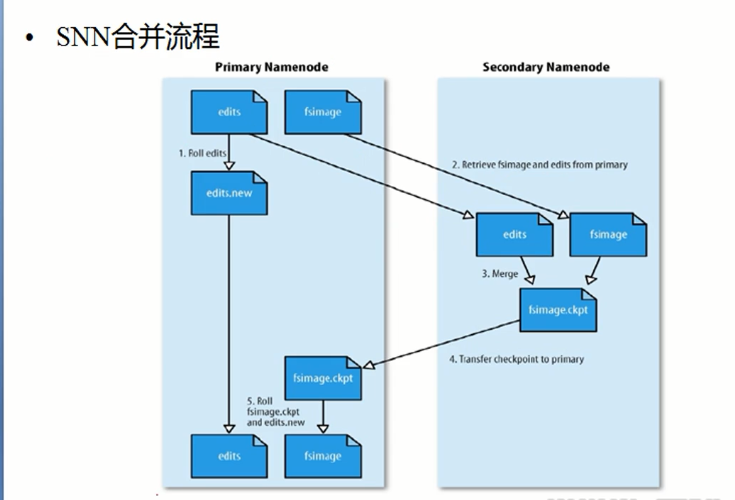
但是怎么去将这两种方式结合起来使用呢?首先先要理解fsimage文件和edits文件的产生的时候,对于fsimage文件是产生于搭建hadoop集群系统的时候,此时产生的文件是空的。edits的产生时机:集群启动的时候,会产生一个edits log文件,此时的文件也是空的,之后启动完毕之后,log文件会和fsimage文件进行合并,之后log一直会增大,因为集群启动之后,客户端会不断的通过NameNode实时的向集群发送指令,这都会记录到log文件中,这个时候 所带来的问题:log文件一直会增大,所以此时更不能通过edits进行恢复数据了,时间会很长,所以hadoop会通过SecondNameNode有时对edits和fsimage文件进行合并
SecondaryNameNode概念:并不是nameNode的备份,而仅仅是为了合并fsimage文件和log文件出现的这个

具体的合并过程
刚刚集群搭建完毕之后:生成了一个空的fsimage,之后启动了系统之后,就会产生一个fsimage文件,之后客户端对NameNode进行发送指令记录在edits中,所以edits会变大,但是通过第二主节点的检查,当edits达到一定的大小之后,便不会让他继续的去记录指令了,NameNode就会将所在结点(也就是主结点)edits传输至第二主节点进行合并处理,同时主结点的edits会清空,为了以后再次接受指令记录的时候仍然从0的大小开始增长。合并之后会发送给NameNode,将原有的主结点中的fsimage进行替代,之后主结点中的那个edits会从新的开始记录客户端发送的指令,之后整个此过程重复即可。但是这个是hadoop1.0时候的持久化的NameNode数据处理机制。在2.x版本之后,这个SecondaryNameNode就消失了
DataNode学习理解

hadoop学习笔记(一):NameNade持久化和DataNode概念的更多相关文章
- hadoop学习笔记(四):HDFS文件权限,安全模式,以及整体注意点总结
本文原创,转载注明作者和原文链接! 一:总结注意点: 到现在为止学习到的角色:三个NameNode.SecondaryNameNode.DataNode 1.存储的是每一个文件分割存储之后的元数据信息 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(2) ——解读Hello World
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(1) ——菜鸟入门
Hadoop学习笔记(1) ——菜鸟入门 Hadoop是什么?先问一下百度吧: [百度百科]一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序. ...
- Hadoop学习笔记(1)(转)
Hadoop学习笔记(1) ——菜鸟入门 Hadoop是什么?先问一下百度吧: [百度百科]一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序. ...
- Hadoop学习笔记(10) ——搭建源码学习环境
Hadoop学习笔记(10) ——搭建源码学习环境 上一章中,我们对整个hadoop的目录及源码目录有了一个初步的了解,接下来计划深入学习一下这头神象作品了.但是看代码用什么,难不成gedit?,单步 ...
- Hadoop学习笔记(9) ——源码初窥
Hadoop学习笔记(9) ——源码初窥 之前我们把Hadoop算是入了门,下载的源码,写了HelloWorld,简要分析了其编程要点,然后也编了个较复杂的示例.接下来其实就有两条路可走了,一条是继续 ...
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
随机推荐
- redis缓存处理机制
1.redis缓存处理机制:先从缓存里面取,取不到去数据库里面取,然后丢入缓存中 例如:系统参数处理工具类 package com.ztesoft.iotcmp.utils; import com.e ...
- DFT测试-OCC电路介绍
https://www.jianshu.com/p/f7a2bcaefb2e SCAN技术,也就是ATPG技术-- 测试std-logic, 主要实现工具是: 产生ATPG使用Mentor的 Test ...
- 经常犯的错误之递归写不全return
在写递归函数的时候,只在最后一层写return,中间的过程没有return,导致结果的丢失. 举个例子 LL query(LL i, LL k) { if (sum[i] < k) { ; } ...
- 浏览器的主要构成High Level Structure
浏览器的主要组件包括: 1. 用户界面- 包括地址栏.后退/前进按钮.书签目录等,也就是你所看到的除了用来显示你所请求页面的主窗口之外的其他部分 2. 浏览器引擎- 用来查询及操作渲染 ...
- 【Python】计算圆的面积
代码: r=29 area = 3.1415*r*r print(area) print("{:.2f}".format(area)) 结果:
- command failed: npm install --loglevel error --registry=https://registry.npm 用vue-cli 4.0 新建项目总是报错
昨天新买的本本,今天布环境,一安装vue-cli发现都4.0+的版本了,没管太多,就开始新建个项目感受哈,一切运行顺利,输入 "vue create app" 的时候,一切貌似进展 ...
- window10配置远程虚拟机window7上的mysql5.7数据源
原文链接:http://www.xitongcheng.com/jiaocheng/win10_article_18644.html windows10系统用户想要在电脑中设置ODBC数据源,于是手动 ...
- docker互联机制实现便捷互访
何为容器互联 & 为何需要容器互联 容器的互联是一种让多个容器中应用进行快速交互的方式,它会在源和接收容器之间创建连接关系,接收容器可以通过容器名快速访问到源容器,而不用指定具体的 ip 地址 ...
- MyBatis(6)——分页的实现
分页的实现 a)通过mysql的分页查询语句: 说明:sql的分页语句格式为select * from aaa limit #{startIndex},#{pageSize} //---------- ...
- opencv:二值图像的概念
灰度图像与二值图像 二值分割 #include <opencv2/opencv.hpp> #include <iostream> using namespace cv; usi ...