图解kubernetes scheduler基于map/reduce无锁设计的优选计算
优选阶段通过分离计算对象来实现多个node和多种算法的并行计算,并且通过基于二级索引来设计最终的存储结果,从而达到整个计算过程中的无锁设计,同时为了保证分配的随机性,针对同等优先级的采用了随机的方式来进行最终节点的分配,如果大家后续有类似的需求,不妨可以借鉴借鉴
1. 设计基础
1.1 两阶段: 单点与聚合
在进行优选的时候,除了最后一次计算,在进行针对单个算法的计算的时候,会分为两个阶段:单点和聚合
在单点阶段,会根据当前算法针对单个node计算
在聚合阶段,则会根据当前单点阶段计算完成后,来进行聚合
1.2 并行: 节点与算法
单点和聚合两阶段在计算的时候,都是并行的,但是对象则不同,其中单点阶段并行是针对单个node的计算,而聚合阶段则是针对算法级别的计算,通过这种设计分离计算,从而避免多goroutine之间数据竞争,无锁加速优选的计算
1.3 map与reduce
而map与reduce则是针对一个上面并行的两种具体实现,其中map中负责单node打分,而reduce则是针对map阶段的打分进行聚合后,根据汇总的结果进行二次打分计算
1.4 weight
map/reduce阶段都是通过算法计算,如果我们要进行自定义的调整,针对单个算法,我们可以调整其在预选流程中的权重,从而进行定制自己的预选流程
1.5 随机分布
当进行优先级判断的时候,肯定会出现多个node优先级相同的情况,在优选节点的时候,会进行随机计算,从而决定是否用当前优先级相同的node替换之前的最合适的node
2. 源码分析
优选的核心流程主要是在PrioritizeNodes中,这里只介绍其关键的核心数据结构设计
2.1 无锁计算结果保存
无锁计算结果的保存主要是通过下面的二维数组实现, 如果要存储一个算法针对某个node的结果,其实只需要通过两个索引即可:算法索引和节点索引,同理如果我吧针对单个node的索引分配给一个goroutine,则其去其他的goroutine则就可以并行计算
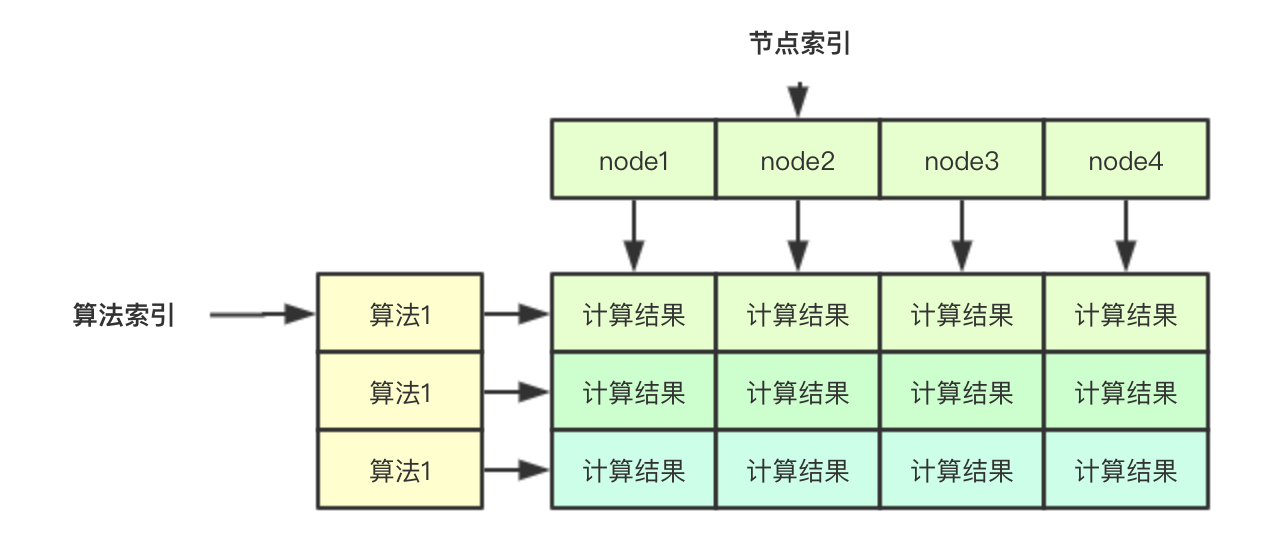
// 在计算的时候,会传入nodes []*v1.Node的数组,存储所有的节点,节点索引主要是指的该部分
results := make([]schedulerapi.HostPriorityList, len(priorityConfigs), len(priorityConfigs))2.2 基于节点索引的Map计算
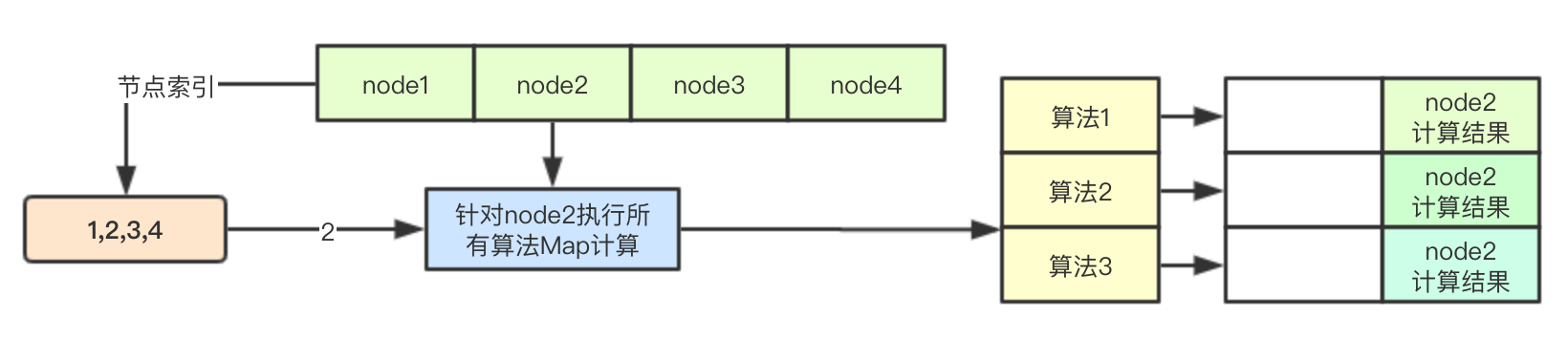
之前在预选阶段介绍过ParallelizeUntil函数的实现,其根据传入的数量来生成计算索引,放入chan中,后续多个goroutine从chan中取出数据直接进行计算即可
workqueue.ParallelizeUntil(context.TODO(), 16, len(nodes), func(index int) {
// 根据节点和配置的算法进行计算
nodeInfo := nodeNameToInfo[nodes[index].Name]
// 获取算法的索引
for i := range priorityConfigs {
if priorityConfigs[i].Function != nil {
continue
}
var err error
// 通过节点索引,来进行针对单个node的计算结果的保存
results[i][index], err = priorityConfigs[i].Map(pod, meta, nodeInfo)
if err != nil {
appendError(err)
results[i][index].Host = nodes[index].Name
}
}
})2.3 基于算法索引的Reduce计算
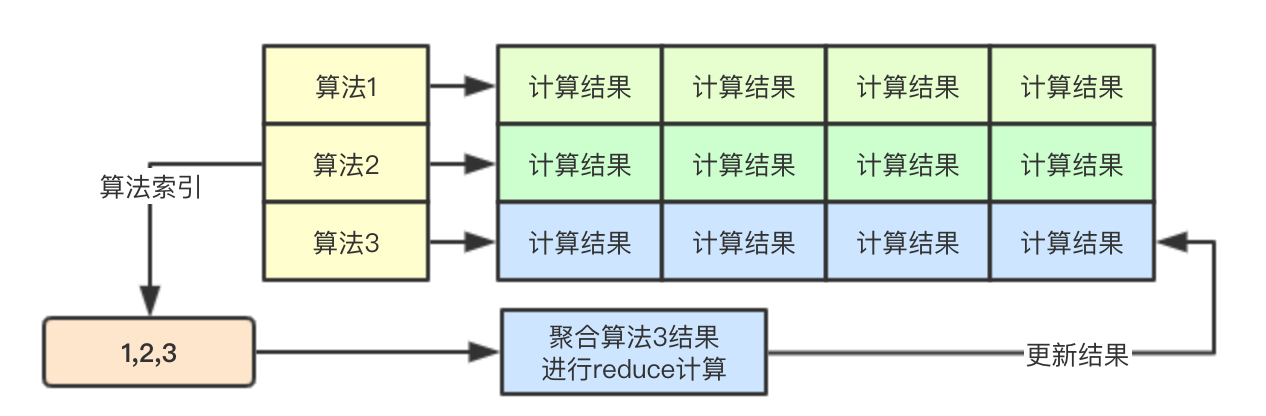
基于算法的并行,则是为每个算法的计算都启动一个goroutine,每个goroutine通过算法索引来进行该算法的所有map阶段的结果的读取,并进行计算,后续结果仍然存储在对应的位置
// 计算策略的分值
for i := range priorityConfigs {
if priorityConfigs[i].Reduce == nil {
continue
}
wg.Add(1)
go func(index int) {
defer wg.Done()
if err := priorityConfigs[index].Reduce(pod, meta, nodeNameToInfo, results[index]); err != nil {
appendError(err)
}
if klog.V(10) {
for _, hostPriority := range results[index] {
klog.Infof("%v -> %v: %v, Score: (%d)", util.GetPodFullName(pod), hostPriority.Host, priorityConfigs[index].Name, hostPriority.Score)
}
}
}(i)
}
// Wait for all computations to be finished.
wg.Wait()2.4 优先级打分结果统计
根据之前的map/reduce阶段,接下来就是将针对所有node的所有算法计算结果进行累加即可
// Summarize all scores.
result := make(schedulerapi.HostPriorityList, 0, len(nodes))
for i := range nodes {
result = append(result, schedulerapi.HostPriority{Host: nodes[i].Name, Score: 0})
// 便利所有的算法配置
for j := range priorityConfigs {
result[i].Score += results[j][i].Score * priorityConfigs[j].Weight
}
for j := range scoresMap {
result[i].Score += scoresMap[j][i].Score
}
}2.5 根据优先级随机筛选host
这里的随机筛选是指的当多个host优先级相同的时候,会有一定的概率用当前的node替换之前的优先级相等的node(到目前为止的优先级最高的node), 其主要通过cntOfMaxScore和rand.Intn(cntOfMaxScore)来进行实现
func (g *genericScheduler) selectHost(priorityList schedulerapi.HostPriorityList) (string, error) {
if len(priorityList) == 0 {
return "", fmt.Errorf("empty priorityList")
}
maxScore := priorityList[0].Score
selected := priorityList[0].Host
cntOfMaxScore := 1
for _, hp := range priorityList[1:] {
if hp.Score > maxScore {
maxScore = hp.Score
selected = hp.Host
cntOfMaxScore = 1
} else if hp.Score == maxScore {
cntOfMaxScore++
if rand.Intn(cntOfMaxScore) == 0 {
// Replace the candidate with probability of 1/cntOfMaxScore
selected = hp.Host
}
}
}
return selected, nil
}3. 设计总结
优选阶段通过分离计算对象来实现多个node和多种算法的并行计算,并且通过基于二级索引来设计最终的存储结果,从而达到整个计算过程中的无锁设计,同时为了保证分配的随机性,针对同等优先级的采用了随机的方式来进行最终节点的分配,如果大家后续有类似的需求,不妨可以借鉴借鉴
本系列纯属个人臆测仅供参考,如果有看出错误的大佬欢迎指正
微信号:baxiaoshi2020
关注公告号阅读更多源码分析文章
更多文章关注 www.sreguide.com
本文由博客一文多发平台 OpenWrite 发布


图解kubernetes scheduler基于map/reduce无锁设计的优选计算的更多相关文章
- 图解kubernetes scheduler基于map/reduce模式实现优选阶段
优选阶段通过分map/reduce模式来实现多个node和多种算法的并行计算,并且通过基于二级索引来设计最终的存储结果,从而达到整个计算过程中的无锁设计,同时为了保证分配的随机性,针对同等优先级的采用 ...
- 基于Redis的分布式锁设计
前言 基于Redis的分布式锁实现,原理很简单嘛:检测一下Key是否存在,不存在则Set Key,加锁成功,存在则加锁失败.对吗?这么简单吗? 如果你真这么想,那么你真的需要好好听我讲一下了.接下来, ...
- 图解 kubernetes scheduler 架构设计系列-初步了解
资源调度基础 scheudler是kubernetes中的核心组件,负责为用户声明的pod资源选择合适的node,同时保证集群资源的最大化利用,这里先介绍下资源调度系统设计里面的一些基础概念 基础任务 ...
- 聊聊高并发(三十二)实现一个基于链表的无锁Set集合
Set表示一种没有反复元素的集合类,在JDK里面有HashSet的实现,底层是基于HashMap来实现的.这里实现一个简化版本号的Set,有下面约束: 1. 基于链表实现.链表节点依照对象的hashC ...
- 基于CAS实现无锁结构
杨乾成 2017310500302 一.题目要求 基于CAS(Compare and Swap)实现一个无锁结构,可考虑queue,stack,hashmap,freelist等. 能够支持多个线程同 ...
- 图解kubernetes调度器抢占流程与算法设计
抢占调度是分布式调度中一种常见的设计,其核心目标是当不能为高优先级的任务分配资源的时候,会通过抢占低优先级的任务来进行高优先级的调度,本文主要学习k8s的抢占调度以及里面的一些有趣的算法 1. 抢占调 ...
- 分布式基础学习(2)分布式计算系统(Map/Reduce)
二. 分布式计算(Map/Reduce) 分 布式式计算,同样是一个宽泛的概念,在这里,它狭义的指代,按Google Map/Reduce框架所设计的分布式框架.在Hadoop中,分布式文件 系统,很 ...
- 分布式基础学习【二】 —— 分布式计算系统(Map/Reduce)
二. 分布式计算(Map/Reduce) 分布式式计算,同样是一个宽泛的概念,在这里,它狭义的指代,按Google Map/Reduce框架所设计的分布式框架.在Hadoop中,分布式文件系统,很大程 ...
- Map Reduce和流处理
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由@从流域到海域翻译,发表于腾讯云+社区 map()和reduce()是在集群式设备上用来做大规模数据处理的方法,用户定义一个特定的映射 ...
随机推荐
- 关于后台动态模板添加内容的总结 Builder使用
1.后台控制器中ArticleController中加载 formBuilder,listBuilder类: 2.实例化FormBuilder对象,调用类中的方法: 3.初始化时加载Builder/f ...
- mysql导入文件出现Data truncated for column 'xxx' at row 1的原因
mysql导入文件的时候很容易出现"Data truncated for column 'xxx' at row x",其中字符串里的xxx和x是指具体的列和行数. 有时候,这是因 ...
- java 代理的概念与作用
1.引入: 为已存在的多个具有相同接口的目标类的各个方法增加一些系统功能,例如,异常处理.日志.计算方法的运行时间.事务管理.等等,你准备如何做? 编写一个与目标类具有相同接口的代理类,代理类的每个方 ...
- linux 内核定时器
无论何时你需要调度一个动作以后发生, 而不阻塞当前进程直到到时, 内核定时器是给你 的工具. 这些定时器用来调度一个函数在将来一个特定的时间执行, 基于时钟嘀哒, 并且 可用作各类任务; 例如, 当硬 ...
- javascript中的深拷贝与浅拷贝
javascript中的深拷贝与浅拷贝 基础概念 在了解深拷贝与浅拷贝的时候需要先了解一些基础知识 核心知识点之 堆与栈 栈(stack)为自动分配的内存空间,它由系统自动释放: 堆(heap)则是动 ...
- vue-learning:34 - component - 内置组件 - 缓存组件keep-alive
vue内置缓存组件keep-alive <keep-alive>标签内包裹的组件切换时会缓存组件实例,而不是销毁它们.避免多次加载相应的组件,减少性能消耗.并且当组件在 <keep- ...
- CSS---cursor 鼠标指针光标样式(形状)
url 需使用的自定义光标的 URL. 注释:请在此列表的末端始终定义一种普通的光标,以防没有由 URL 定义的可用光标. default 默认光标(通常是一个箭头) auto 默认.浏览器设置的光标 ...
- Educational Codeforces Round 64部分题解
Educational Codeforces Round 64部分题解 A 题目大意:给定三角形(高等于低的等腰),正方形,圆,在满足其高,边长,半径最大(保证在上一个图形的内部)的前提下. 判断交点 ...
- koa2入门--09.art-template高速模板引擎的使用
首先在项目文件夹下使用 cmd,输入:npm install --save art-template koa-template art-template语法参考:http://aui.github.i ...
- oracle 查询含clob 字段慢
项目中使用Oracle 查询表数据感觉特别慢,一秒只能查询十条记录. 刚开始以为是全表扫描的问题,加上索引 生效后,查询还是很慢. 表中只有三个字段,其中一个是clob,于是推测,是不是查询字段的原因 ...