oracle在进行跨库访问时,采用dblink实现
首先了解下环境:在tnsnames.ora中配置两个数据库别名:test1/test1@11orcl1、tets2/tets2@12orlc2,在orcl1中创建database link来访问orcl2
#测试数据库1
11orcl1 =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.0.11)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = orcl)
)
)
#测试数据库2
12orcl2 =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.0.12)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = orcl)
)
)
第一步:赋予权限
在创建database link之前,我们需要判断,登陆的用户是否具备创建database link 的权限,所以我们执行以下的语句(用test1用户登陆11orcl1):
-- 查看test1用户是否具备创建database link 权限
select * from user_sys_privs where privilege like upper('%DATABASE LINK%') AND USERNAME='test1';
如果查询有返回行,则表示具备创建database link权限,否则,则需要使用sys登陆orcl为test1用户赋予创建权限
-- 给wangyong用户授予创建dblink的权限
grant create public database link to test1;
此时,再执行上面查看是否具备权限的sql语句,会发现有返回行,表示,test1这个用户已经具备创建database link的权限
第二步;创建database link
我所了解到的创建方式有两种:1)通过pl/sql developer图形化创建、2)通过sqlplus中的sql语句创建,依次来看
1)pl/sql developer 图形化创建
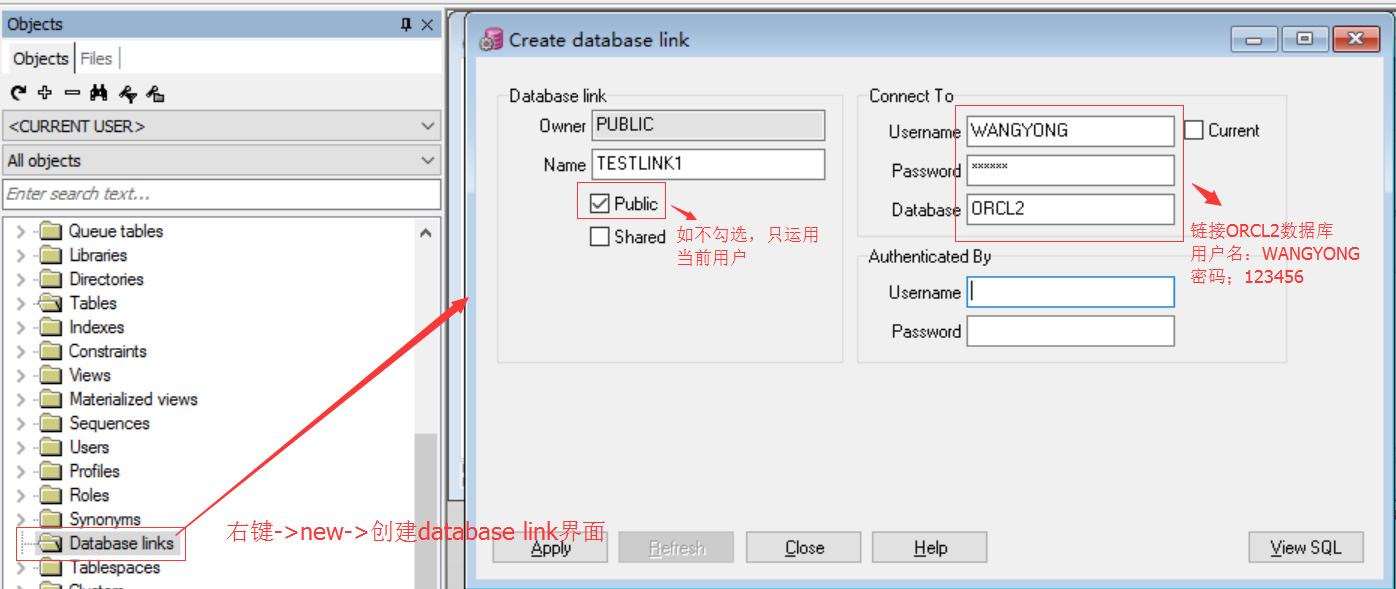
2)sql语句创建
-- 注意一点,如果密码是数字开头,用“”括起来
create public database link TESTLINK2 connect to test2 identified by "test2" USING '12ORCL2'
这样,就完成了简单database简单的创。
SELECT * FROM TESTSYNONYM@TESTLINK2 order by id
至此,简单的dblink操作就可以了,对于上面的链接字符串,还可以创建同义词代替,会稍微省点事
-- 创建同义词
create synonym TESTSYNONYM FOR company@TESTLINK2;
那么上面的查询、插入、修改、删除中可直接用WYSYNONYM代替company@TESTLINK1即可,例如查询语句可改成如下方式(插入,修改,删除类似):
-- 查询12ORCL2中test2用户的表COMPANY
SELECT * FROM TESTSYNONYM order by id
oracle在进行跨库访问时,采用dblink实现的更多相关文章
- Oracle跨库访问数据表-DBLINK
1:创建DBLINK(USING后面的连接字符串就是要访问的那个数据库的连接字符串) CREATE DATABASE LINK linkName CONNECT TO userName IDENTIF ...
- Postgresql ODBC驱动,用sqlserver添加dblink跨库访问postgresql数据库
在同样是SQLserver数据库跨库访问时,只需要以下方法 declare @rowcount int set @rowcount =(select COUNT(*) from sys.servers ...
- postgresql 模式与用户,及跨库访问
1 控制台命令\h:查看SQL命令的解释,比如\h select.\?:查看psql命令列表.\l:列出所有数据库.\c [database_name]:连接其他数据库.\d:列出当前数据库的所有表格 ...
- SqlServer 跨库访问
同实例跨库 只需要 库名.dbo.表 dbo可省略 如: use Test select * from rdrecords select * from oa.dbo.UserInfo 不同实例与不同i ...
- oracle 跨库访问
创建DBLINK的方法: 1. create public database link dblink connect to totalplant identified by totalplant us ...
- 针对数据量较大的表,需要进行跨库复制,采用navcat 实现sqlite数据库跨数据库的数据表迁移 [转载]
2014年12月13日 14:36 新浪博客 (转自http://www.cnblogs.com/nmj1986/archive/2012/09/17/2688827.html) 需求: 有两个不同的 ...
- Oracle如何实现跨库查询
实现结果:在一个数据库中某个用户下编写一个存储过程,在存储过程中使用DBLINK连接另一个数据库,从此数据库中的一个用户下取数,然后插入当前的数据库中的一个表中. 二. 实现方法步骤: 1. 创建存储 ...
- 两个java项目,跨域访问时,浏览器不能正确解析数据问题
@Controller@RequestMapping(value = "api/item/cat")public class ApiItemCatController { @Aut ...
- Oracle 跨库 查询 复制表数据
在目前绝大部分数据库有分布式查询的需要.下面简单的介绍如何在oracle中配置实现跨库访问. 比如现在有2个数据库服务器,安装了2个数据库.数据库server A和B.现在来实现在A库中访问B的数据库 ...
随机推荐
- m_Orchestrate learning system---三十五、php数据和js数据的解耦:php数据(php代码)不要放到js代码中
m_Orchestrate learning system---三十五.php数据和js数据的解耦:php数据(php代码)不要放到js代码中 一.总结 一句话总结:也就是以html为中介,用html ...
- spring-cloud: eureka之:ribbon负载均衡配置(一)
spring-cloud: eureka之:ribbon负载均衡配置(一) 比如我有: 一个eureka服务:8761 两个user用户服务: 7900/7901端口 一个movie服务:8010 1 ...
- GetTitleAndUrl
Sub GetTitleAndUrl() Dim strText As String Dim i As Long Dim OneA Dim IsContent As Boolean Dim PageI ...
- antd-pro1.0使用jest对react组件进行单元测试
前言 基于React+Ant Design(以下用Antd表示)的项目,在对于自己封装的,或者基于Antd封装的公共组件的自动化测试技术的选型和实践. 背景 随着前端项目越来越大,业务逻辑日益繁杂,协 ...
- Hibernate---运行原理
Hibernate---运行原理
- spark RDD底层原理
RDD底层实现原理 RDD是一个分布式数据集,顾名思义,其数据应该分部存储于多台机器上.事实上,每个RDD的数据都以Block的形式存储于多台机器上,下图是Spark的RDD存储架构图,其中每个Exe ...
- plsql导入excel文件
plsql导入excel文件 CREATE TABLE DWSB_GRMX1 ( XH VARCHAR2(40), SFZH VARCHAR2(40 ...
- for each...in,for...in, for...of
一.for each ...in explanation: 该语句在对象属性的所有值上迭代指定的变量.对于每个不同的属性,执行指定的语句. 句法: for each (variable in obj ...
- hdu6153
题解: EX_KMP 先计算出ex数组 然后ans统计前缀 然后乘一下就好了 代码: #include<cstdio> #include<cmath> #include< ...
- Java——String类
body, table{font-family: 微软雅黑; font-size: 10pt} table{border-collapse: collapse; border: solid gray; ...