【机器学习】K-means聚类算法与EM算法
初始目的
将样本分成K个类,其实说白了就是求一个样本例的隐含类别y,然后利用隐含类别将x归类。由于我们事先不知道类别y,那么我们首先可以对每个样例假定一个y吧,但是怎么知道假定的对不对呢?怎样评价假定的好不好呢?
我们使用样本的极大似然估计来度量,这里就是x和y的联合分布P(x,y)了。如果找到的y能够使P(x,y)最大,那么我们找到的y就是样例x的最佳类别了,x顺手就聚类了。但是我们第一次指定的y不一定会让P(x,y)最大,而且P(x,y)还依赖于其他未知参数,当然在给定y的情况下,我们可以调整其他参数让P(x,y)最大。但是调整完参数后,我们发现有更好的y可以指定,那么我们重新指定y,然后再计算P(x,y)最大时的参数,反复迭代直至没有更好的y可以指定。
这个过程有几个难点:
第一怎么假定y?是每个样例硬指派一个y还是不同的y有不同的概率,概率如何度量。
第二如何估计P(x,y),P(x,y)还可能依赖很多其他参数,如何调整里面的参数让P(x,y)最大。
EM算法的思想:
E步就是估计隐含类别y的期望值,M步调整其他参数使得在给定类别y的情况下,极大似然估计P(x,y)能够达到极大值。然后在其他参数确定的情况下,重新估计y,周而复始,直至收敛。
从K-means里我们可以看出它其实就是EM的体现,E步是确定隐含类别变量 ,M步更新其他参数
,M步更新其他参数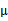 来使J最小化。这里的隐含类别变量指定方法比较特殊,属于硬指定,从k个类别中硬选出一个给样例,而不是对每个类别赋予不同的概率。总体思想还是一个迭代优化过程,有目标函数,也有参数变量,只是多了个隐含变量,确定其他参数估计隐含变量,再确定隐含变量估计其他参数,直至目标函数最优。
来使J最小化。这里的隐含类别变量指定方法比较特殊,属于硬指定,从k个类别中硬选出一个给样例,而不是对每个类别赋予不同的概率。总体思想还是一个迭代优化过程,有目标函数,也有参数变量,只是多了个隐含变量,确定其他参数估计隐含变量,再确定隐含变量估计其他参数,直至目标函数最优。
EM算法就是这样,假设我们想估计知道A和B两个参数,在开始状态下二者都是未知的,但如果知道了A的信息就可以得到B的信息,反过来知道了B也就得到了A。可以考虑首先赋予A某种初值,以此得到B的估计值,然后从B的当前值出发,重新估计A的取值,这个过程一直持续到收敛为止。
EM的意思是“Expectation Maximization”在我们上面这个问题里面,我们是先随便猜一下男生(身高)的正态分布的参数:如均值和方差是多少。例如男生的均值是1米7,方差是0.1米(当然了,刚开始肯定没那么准),然后计算出每个人更可能属于第一个还是第二个正态分布中的(例如,这个人的身高是1米8,那很明显,他最大可能属于男生的那个分布),这个是属于Expectation一步。有了每个人的归属,或者说我们已经大概地按上面的方法将这200个人分为男生和女生两部分,我们就可以根据之前说的最大似然那样,通过这些被大概分为男生的n个人来重新估计第一个分布的参数,女生的那个分布同样方法重新估计。这个是Maximization。然后,当我们更新了这两个分布的时候,每一个属于这两个分布的概率又变了,那么我们就再需要调整E步……如此往复,直到参数基本不再发生变化为止。
http://blog.csdn.net/zouxy09/article/details/8537620
【机器学习】K-means聚类算法与EM算法的更多相关文章
- 机器学习优化算法之EM算法
EM算法简介 EM算法其实是一类算法的总称.EM算法分为E-Step和M-Step两步.EM算法的应用范围很广,基本机器学习需要迭代优化参数的模型在优化时都可以使用EM算法. EM算法的思想和过程 E ...
- MM 算法与 EM算法概述
1.MM 算法: MM算法是一种迭代优化方法,利用函数的凸性来寻找它们的最大值或最小值. MM表示 “majorize-minimize MM 算法” 或“minorize maximize MM 算 ...
- 猪猪的机器学习笔记(十四)EM算法
EM算法 作者:樱花猪 摘要: 本文为七月算法(julyedu.com)12月机器学习第十次次课在线笔记.EM算法全称为Expectation Maximization Algorithm,既最大 ...
- K-means聚类算法与EM算法
K-means聚类算法 K-means聚类算法也是聚类算法中最简单的一种了,但是里面包含的思想却不一般. 聚类属于无监督学习.在聚类问题中,给我们的训练样本是,每个,没有了y. K-means算法是将 ...
- Python实现机器学习算法:EM算法
''' 数据集:伪造数据集(两个高斯分布混合) 数据集长度:1000 ------------------------------ 运行结果: ---------------------------- ...
- 机器学习十大算法之EM算法
此文已由作者赵斌授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 由于目前论坛的Markdown不支持Mathjax,数学公式没法正常识别,文章只能用截图上传了... ...
- 吴裕雄 python 机器学习——K均值聚类KMeans模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 聚类之K均值聚类和EM算法
这篇博客整理K均值聚类的内容,包括: 1.K均值聚类的原理: 2.初始类中心的选择和类别数K的确定: 3.K均值聚类和EM算法.高斯混合模型的关系. 一.K均值聚类的原理 K均值聚类(K-means) ...
- 【机器学习】机器学习入门08 - 聚类与聚类算法K-Means
时间过得很快,这篇文章已经是机器学习入门系列的最后一篇了.短短八周的时间里,虽然对机器学习并没有太多应用和熟悉的机会,但对于机器学习一些基本概念已经差不多有了一个提纲挈领的了解,如分类和回归,损失函数 ...
随机推荐
- ipsec协议(转)
from:http://lulu1101.blog.51cto.com/4455468/816875 ipsec协议 2012-03-25 23:40:28 标签:休闲 ipsec协议 职场 IPSe ...
- Ant scp upload文件至linux server(用java调用Ant api)
1.要准备的jar包:ant.jar,ant-jsch.jar code: package com.test.utils; import org.apache.tools.ant.Project; i ...
- 在Hadoop1.2.1上运行第一个Hadoop程序FileSystemCat
- WebService出错 Maximum message size quota for incoming messages (65536) has been exceeded.已超过传入消息(65536)的最大消息大小配额
WebService应用中如果收到的信息非常大时出错. 1:Maximum message size quota for incoming messages (65536) has been exce ...
- 高并发分布式系统中生成全局唯一(订单号)Id js返回上一页并刷新、返回上一页、自动刷新页面 父页面操作嵌套iframe子页面的HTML标签元素 .net判断System.Data.DataRow中是否包含某列 .Net使用system.Security.Cryptography.RNGCryptoServiceProvider类与System.Random类生成随机数
高并发分布式系统中生成全局唯一(订单号)Id 1.GUID数据因毫无规律可言造成索引效率低下,影响了系统的性能,那么通过组合的方式,保留GUID的10个字节,用另6个字节表示GUID生成的时间(D ...
- mysql join left join区别
mysql默认的join是inner join,inner join 和 left join的区别看图:
- MySQL -- 外键创建失败
使用show engine innodb status\G 查看数据库状态的时候,发现以下报错信息: ------------------------ LATEST FOREIGN KEY ERROR ...
- C++ STL vector(向量容器)的使用(附完整程序代码)
一.简单介绍 Vectors 包括着一系列连续存储的元素,其行为和数组类似. 訪问Vector中的随意元素或从末尾加入元素都能够在O(1)内完毕,而查找特定值的元素所处的位置或是在Vector中插入元 ...
- Eclipse安装PlantUML插件
新技术的诞生和更新,新工具的发现和使用是两件让人开心的事情. 还记得Visio下苦苦的画流程图的时光吗,现在一切都变得so easy,因为有PlantUML! 官网:http://plantuml.c ...
- SQL触发器 常用语句
一.创建一个简单的触发器 CREATE TRIGGER 触发器名称 ON 表名 FOR INSERT.UPDATE 或 DELETE AS T-SQL 语句 注意:触发器名称是不加引号的. ...