【大数据系列】Hadoop DataNode读写流程
DataNode的写操作流程
DataNode的写操作流程可以分为两部分,第一部分是写操作之前的准备工作,包括与NameNode的通信等;第二部分是真正的写操作。
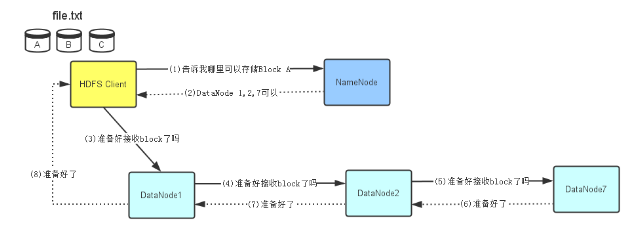
一、准备工作
1、首先,HDFS client会去询问NameNoed,看哪些DataNode可以存储Block A,file.txt文件的拆分是在HDFS client中完成的,拆分成了3个Block(A B C).因为NameNode存储着整个文件系统的元数据,它知道哪个DataNode上有空间可以存储这个Block A.
2、NameNode通过查看它的元数据信息,发现DataNode1、2、7上有空间可以存储Block A,预示将此信息高速HDFS Client.
3、HDFS Client接到NameNode返回的DataNode列表信息后,它会直接联系第一个DataNode-DataNode 1,让它准备接收Block A--实际上就是建立彼此之间的TCP连接。然后将Block A和NameNode返回的所有关于DataNode的元数据一并传给DataNode1.
4、在DataNode1与HDFS Client建立好TCP连接后,它会把HDFS Client要写Block A的请求顺序传给DataNode2(在与HDFS Client建立好TCP连接后从HDFS Client获得的DataNode信息),要求DataNode2也准备好接收Block A(建立DataNode2到DataNode1的TCP连接)。
5、同上,建立DataNode2到DataNode7的TCP连接
6、当DataNode7准备好之后,它会通知DataNode2,表示可以开始接收Block A
7、同理,当DataNode2准备好之后,他会通知DataNode1,表明可以开始接收Block A
8、当HDFS Client接收到DataNode1的成功反馈信息后,说明这3个DataNode都已经准备好了,HDFS Client就会开始往这三个DataNode写入Block A
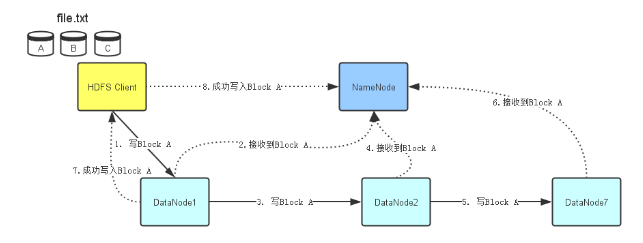
二、流程
在DataNode1 2 7都准备好接收数据后,HDFS Client开始往DataNode1写入Block A数据。同准备工作一样,当DataNode1接受完A数据后,它会顺序将Block A数据传输给DataNode2,然后DataNode2再传输给DataNode7.每个DataNode在接受完Block A 数据后,会发消息给NameNode,告诉他Block数据已经接收完毕,NameNode同时会根据它接收到的小心更新它保存的文件系统元数据信息。当Block A成功写入3个DataNode之后,DataNode1会发送一个成功消息给HDFS Client,同时HDFS Client也会发一个Block A成功写入的信息给NameNode,之后HDFS Client才能开始继续处理下一个Block:Block B。
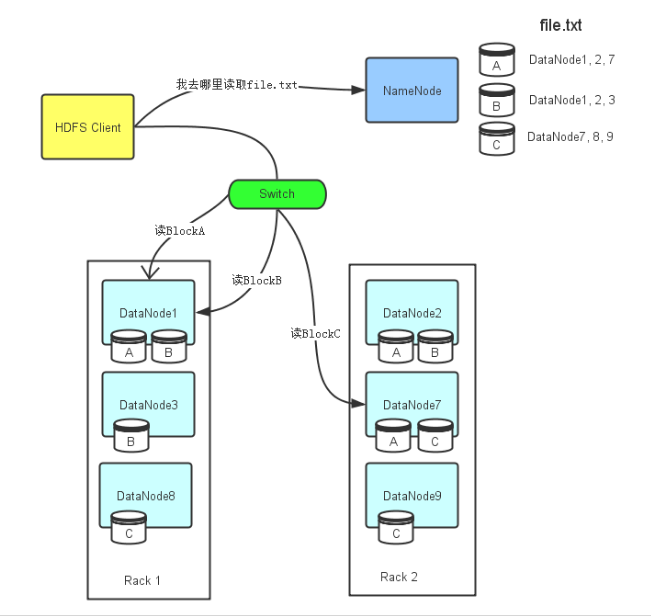
DataNode的读操作流程:
首先,HDFS Client会先去联系NameNode,询问file.txt总共分为几个Block ,而且这些Block分别存放在哪些DataNode上。由于每个Block都会存在几个副本,所以NameNode会把file.txt文件组成的Block对应的所有DataNode列表都返回给HDFS Client.然后HDFS Client会选择DataNode列表里的第一个DataNode去读取对应的Block,比如Block A存储在DataNode 1 2 7,那么HDFS Client会到DataNode1去读取Block A,Block c存储在DataNode7 8 9那么HDFS Client就回到DataNode7去读取Block C.
【大数据系列】Hadoop DataNode读写流程的更多相关文章
- 大数据系列(3)——Hadoop集群完全分布式坏境搭建
前言 上一篇我们讲解了Hadoop单节点的安装,并且已经通过VMware安装了一台CentOS 6.8的Linux系统,咱们本篇的目标就是要配置一个真正的完全分布式的Hadoop集群,闲言少叙,进入本 ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- 大数据系列2:Hdfs的读写操作
在前文大数据系列1:一文初识Hdfs中,我们对Hdfs有了简单的认识. 在本文中,我们将会简单的介绍一下Hdfs文件的读写流程,为后续追踪读写流程的源码做准备. Hdfs 架构 首先来个Hdfs的架构 ...
- 大数据系列(5)——Hadoop集群MYSQL的安装
前言 有一段时间没写文章了,最近事情挺多的,现在咱们回归正题,经过前面四篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,相关的两款软件VSFTP和SecureCRT也已经正常安装了. ...
- 大数据系列(4)——Hadoop集群VSFTP和SecureCRT安装配置
前言 经过前三篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,当然,我相信安装的过程肯定遇到或多或少的问题,这些都需要自己解决,解决的过程就是学习的过程,本篇的来介绍几个Hadoop环 ...
- 大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍
Technorati 标记: hadoop,生态圈,ecosystem,yarn,spark,入门 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用 ...
- 大数据系列之并行计算引擎Spark介绍
相关博文:大数据系列之并行计算引擎Spark部署及应用 Spark: Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎. Spark是UC Berkeley AMP lab ( ...
- 大数据系列4:Yarn以及MapReduce 2
系列文章: 大数据系列:一文初识Hdfs 大数据系列2:Hdfs的读写操作 大数据谢列3:Hdfs的HA实现 通过前文,我们对Hdfs的已经有了一定的了解,本文将继续之前的内容,介绍Yarn与Yarn ...
- 大数据:Hadoop入门
大数据:Hadoop入门 一:什么是大数据 什么是大数据: (1.)大数据是指在一定时间内无法用常规软件对其内容进行抓取,管理和处理的数据集合,简而言之就是数据量非常大,大到无法用常规工具进行处理,如 ...
随机推荐
- 嵌入式开发值zynq---zynq中tlv320aic23b spi的驱动移植
http://blog.csdn.net/djason43/article/details/52876742 http://blog.csdn.net/lxmky/article/details/68 ...
- CI框架 -- 核心文件 之 Benchmark.php
Benchmark.php文件中定义的CI_Benchmark类可以让你标记点,并计算它们之间的时间差.还可以显示内存消耗. Benchmarking类库,它是被系统自动被加载的,不需要手工加载 cl ...
- FusionCancer-人类癌症相关的融合基因的数据库
RNA-seq 测序可以用于融合基因的发现,在过去的十几年里,RNA-seq 测序数据不断增加,发现的融合基因的数据也不断增加: FusionCancer 是一个人类癌症相关的融合基因的数据库,利用N ...
- HTML5 Canvas火焰效果 像火球发射一样
Canvas是HTML5中非常重要而且有用的东西,我们可以在Canvas上绘制任意的元素,就像你制作Flash一样.今天我们就在Canvas上来制作一款火焰发射的效果.就像古代的火球炮一样,而且可以在 ...
- 全新升级的WiFi无线上网短信认证系统,适用于咖啡厅、足浴等公共场所,提高门门店营业收入
WiFi无线上网短信认证系统经历从1.0到1.88的升级,都是用户在使用过程中,提出宝贵的意见,一直修复至今,有着非常稳定的版本. 这个软件有什么作用?WiFi为什么要认证呢? 其实这个只是获取用户联 ...
- unity3d 调用Start 注意
在unity3d中,同一个脚本被绑定到多个物体上的时候,只有active的物体才会调用void Start () 方法, 如果物体是NO Active 的状态,则不会调用Start,Awake也不会 ...
- Junit结合Spring对Dao层进行单元测试
关于单元测试,上一次就简单的概念和Mock基础做了,参考:http://60.174.249.204:8888/in/modules/article/view.article.php/74 实际开发过 ...
- [SQLite3]connection string的连接池参数引发的错误
最近在.net中使用Sqlite数据库,发现.net的驱动做得不错,而且实现了加密功能.于是想给自己的数据库加上口令,结果,多次实验都以失败告终: 链接数据库,然后ChangePassword都成功执 ...
- 【DL】物体识别与定位
https://cloud.tencent.com/community/article/414833
- Mongodb安全认证
Mongodb安全认证在单实例和副本集两种情况下不太一样,单实例相对简单,只要在启动时加上 --auth参数即可,但副本集则需要keyfile. 一.单实例 1.启动服务(先不要加auth参数) 2. ...