【大数据系列】Hadoop DataNode读写流程
DataNode的写操作流程
DataNode的写操作流程可以分为两部分,第一部分是写操作之前的准备工作,包括与NameNode的通信等;第二部分是真正的写操作。
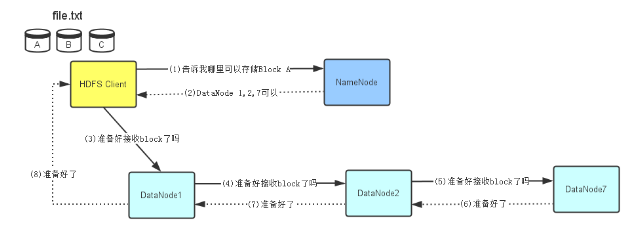
一、准备工作
1、首先,HDFS client会去询问NameNoed,看哪些DataNode可以存储Block A,file.txt文件的拆分是在HDFS client中完成的,拆分成了3个Block(A B C).因为NameNode存储着整个文件系统的元数据,它知道哪个DataNode上有空间可以存储这个Block A.
2、NameNode通过查看它的元数据信息,发现DataNode1、2、7上有空间可以存储Block A,预示将此信息高速HDFS Client.
3、HDFS Client接到NameNode返回的DataNode列表信息后,它会直接联系第一个DataNode-DataNode 1,让它准备接收Block A--实际上就是建立彼此之间的TCP连接。然后将Block A和NameNode返回的所有关于DataNode的元数据一并传给DataNode1.
4、在DataNode1与HDFS Client建立好TCP连接后,它会把HDFS Client要写Block A的请求顺序传给DataNode2(在与HDFS Client建立好TCP连接后从HDFS Client获得的DataNode信息),要求DataNode2也准备好接收Block A(建立DataNode2到DataNode1的TCP连接)。
5、同上,建立DataNode2到DataNode7的TCP连接
6、当DataNode7准备好之后,它会通知DataNode2,表示可以开始接收Block A
7、同理,当DataNode2准备好之后,他会通知DataNode1,表明可以开始接收Block A
8、当HDFS Client接收到DataNode1的成功反馈信息后,说明这3个DataNode都已经准备好了,HDFS Client就会开始往这三个DataNode写入Block A
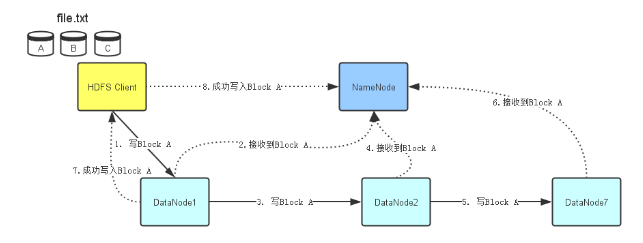
二、流程
在DataNode1 2 7都准备好接收数据后,HDFS Client开始往DataNode1写入Block A数据。同准备工作一样,当DataNode1接受完A数据后,它会顺序将Block A数据传输给DataNode2,然后DataNode2再传输给DataNode7.每个DataNode在接受完Block A 数据后,会发消息给NameNode,告诉他Block数据已经接收完毕,NameNode同时会根据它接收到的小心更新它保存的文件系统元数据信息。当Block A成功写入3个DataNode之后,DataNode1会发送一个成功消息给HDFS Client,同时HDFS Client也会发一个Block A成功写入的信息给NameNode,之后HDFS Client才能开始继续处理下一个Block:Block B。
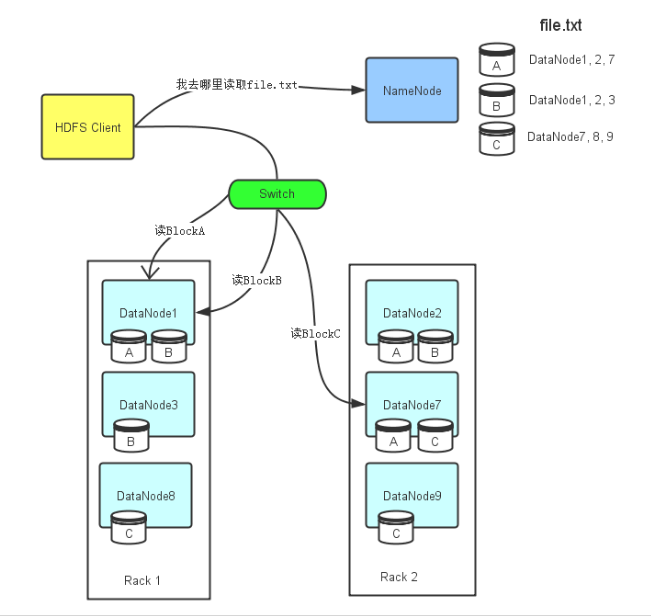
DataNode的读操作流程:
首先,HDFS Client会先去联系NameNode,询问file.txt总共分为几个Block ,而且这些Block分别存放在哪些DataNode上。由于每个Block都会存在几个副本,所以NameNode会把file.txt文件组成的Block对应的所有DataNode列表都返回给HDFS Client.然后HDFS Client会选择DataNode列表里的第一个DataNode去读取对应的Block,比如Block A存储在DataNode 1 2 7,那么HDFS Client会到DataNode1去读取Block A,Block c存储在DataNode7 8 9那么HDFS Client就回到DataNode7去读取Block C.
【大数据系列】Hadoop DataNode读写流程的更多相关文章
- 大数据系列(3)——Hadoop集群完全分布式坏境搭建
前言 上一篇我们讲解了Hadoop单节点的安装,并且已经通过VMware安装了一台CentOS 6.8的Linux系统,咱们本篇的目标就是要配置一个真正的完全分布式的Hadoop集群,闲言少叙,进入本 ...
- 大数据系列(2)——Hadoop集群坏境CentOS安装
前言 前面我们主要分析了搭建Hadoop集群所需要准备的内容和一些提前规划好的项,本篇我们主要来分析如何安装CentOS操作系统,以及一些基础的设置,闲言少叙,我们进入本篇的正题. 技术准备 VMwa ...
- 大数据系列2:Hdfs的读写操作
在前文大数据系列1:一文初识Hdfs中,我们对Hdfs有了简单的认识. 在本文中,我们将会简单的介绍一下Hdfs文件的读写流程,为后续追踪读写流程的源码做准备. Hdfs 架构 首先来个Hdfs的架构 ...
- 大数据系列(5)——Hadoop集群MYSQL的安装
前言 有一段时间没写文章了,最近事情挺多的,现在咱们回归正题,经过前面四篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,相关的两款软件VSFTP和SecureCRT也已经正常安装了. ...
- 大数据系列(4)——Hadoop集群VSFTP和SecureCRT安装配置
前言 经过前三篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,当然,我相信安装的过程肯定遇到或多或少的问题,这些都需要自己解决,解决的过程就是学习的过程,本篇的来介绍几个Hadoop环 ...
- 大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍
Technorati 标记: hadoop,生态圈,ecosystem,yarn,spark,入门 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用 ...
- 大数据系列之并行计算引擎Spark介绍
相关博文:大数据系列之并行计算引擎Spark部署及应用 Spark: Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎. Spark是UC Berkeley AMP lab ( ...
- 大数据系列4:Yarn以及MapReduce 2
系列文章: 大数据系列:一文初识Hdfs 大数据系列2:Hdfs的读写操作 大数据谢列3:Hdfs的HA实现 通过前文,我们对Hdfs的已经有了一定的了解,本文将继续之前的内容,介绍Yarn与Yarn ...
- 大数据:Hadoop入门
大数据:Hadoop入门 一:什么是大数据 什么是大数据: (1.)大数据是指在一定时间内无法用常规软件对其内容进行抓取,管理和处理的数据集合,简而言之就是数据量非常大,大到无法用常规工具进行处理,如 ...
随机推荐
- perl 模块的创建以及制定perl 模块的路径
1) perl 模块的创建 perl 模块的后缀名为.pm, 其中的内容和一般的perl脚本相同, perl模块中通常放置可重用的函数以及变量, 比如创建一个fasta.pm,里面包含一个统计fast ...
- 使用 mysql_use_result 还是使用 mysql_store_result?
From: http://my.oschina.net/moooofly/blog/186456 本文整理了关于“使用 mysql_use_result 还是 mysql_store_result”的 ...
- 各大引擎矩阵的矩阵存储方式 ----行矩阵 or 列矩阵
OpenGL 里面的矩阵 float m[16]; OpenGL中的矩阵是这样的 m[0] m[4] m[8] m[12] m[1] m[5] m[9] m[13] m[2] m[6] m[10] ...
- lvm讲解/磁盘故障小案例
4.10/4.11/4.12 lvm讲解 4.13 磁盘故障小案例 lvm讲解 磁盘故障小案例
- 简单理解AOP(面向切面编程)
AOP为Aspect Oriented Programming的缩写,意为:面向切面编程,通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术. AOP与OOP是面向不同领域的两种设计思想. ...
- windows下卸载oracle11g
oracle11g卸载 oracle11g卸载 卸载oracle: 1.开始--控制面板--性能和维护--管理工具--服务 停止所有的oracle服务. 2.开始--程序--oracle-- ...
- Canvas控件之CanvasGroup
Canvas Group可以用来控制一组不需要个别控制的UI元素的某些方面,CanvasGroup的属性会影响他所有children的GameObject 其中有四个选项: -Alpha:这个选项很多 ...
- 【百度地图API】制作多途经点的线路导航——路线坐标规划
一.创建地图 首先要告诉大家的是,API1.2版本取消密钥,取消服务设置,大家可以采用更加简短的方式引用API的JS啦~ <script type="text/javascript&q ...
- WebGL Matrix4(4*4矩阵库)
Matrix4是由<<WebGL编程指南>>作者写的提供WebGL的4*4矩阵操作的方法库,简化我们编写的代码.源代码共享地址,点击链接:Matrix4源代码. 下面罗列了Ma ...
- python concurrent.futures包使用,捕获异常
concurrent.futures的ThreadPoolExecutor类暴露的api很好用,threading模块抹油提供官方的线程池.和另外一个第三方threadpool包相比,这个可以非阻塞的 ...