cloudera learning5:Hadoop集群高级配置
HDFS-NameNode Tuning:
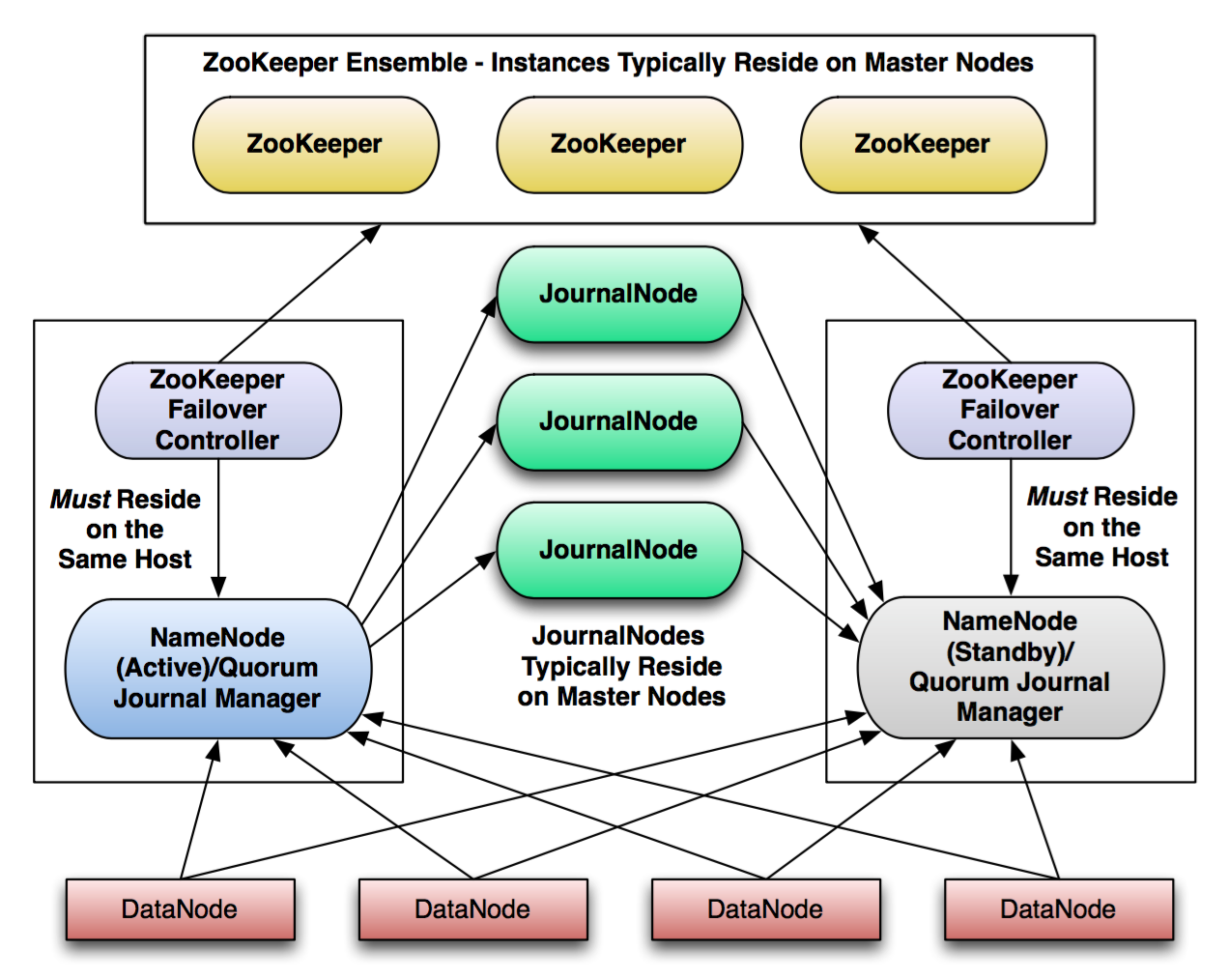
cloudera learning5:Hadoop集群高级配置的更多相关文章
- 【Big Data】HADOOP集群的配置(一)
Hadoop集群的配置(一) 摘要: hadoop集群配置系列文档,是笔者在实验室真机环境实验后整理而得.以便随后工作所需,做以知识整理,另则与博客园朋友分享实验成果,因为笔者在学习初期,也遇到不少问 ...
- 【Big Data】HADOOP集群的配置(二)
Hadoop集群的配置(二) 摘要: hadoop集群配置系列文档,是笔者在实验室真机环境实验后整理而得.以便随后工作所需,做以知识整理,另则与博客园朋友分享实验成果,因为笔者在学习初期,也遇到不少问 ...
- Hadoop的学习前奏(二)——Hadoop集群的配置
前言: Hadoop集群的配置即全然分布式Hadoop配置. 笔者的环境: Linux: CentOS 6.6(Final) x64 JDK: java version "1.7 ...
- Hadoop集群的配置(一)
摘要: hadoop集群配置系列文档,是笔者在实验室真机环境实验后整理而得.以便随后工作所需,做以知识整理,另则与博客园朋友分享实验成果,因为笔者在学习初期,也遇到不少问题.但是网上一些文档大多互相抄 ...
- cloudera learning4:Hadoop集群规划
涉及到一些关于硬件的东西,我也不是很懂,记录下来有待以后学习. Hadoop集群一般都是由小到大,刚开始可能只有4到6个节点,随着存储数据的增加,计算量的增大,内存需求的增加,集群慢慢变大. 比如按照 ...
- hadoop 集群的配置
在经过几天折腾,终于将hadoop环境搭建成功,整个过程中遇到各种坑,反复了很多遍,光虚拟机就重新安装了4.5次,接下来就把搭建的过程详细叙述一下 0.相关工具: 1,系统环境说明: 我这边给出我的集 ...
- hadoop集群默认配置和常用配置【转】
转自http://www.cnblogs.com/ggjucheng/archive/2012/04/17/2454590.html 获取默认配置 配置hadoop,主要是配置core-site.xm ...
- Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS
摘自:http://www.powerxing.com/install-hadoop-cluster/ 本教程讲述如何配置 Hadoop 集群,默认读者已经掌握了 Hadoop 的单机伪分布式配置,否 ...
- hadoop集群默认配置和常用配置
http://www.cnblogs.com/ggjucheng/archive/2012/04/17/2454590.html 获取默认配置 配置hadoop,主要是配置core-site.xml, ...
随机推荐
- Win32中TreeView控件的使用方法,类似于资源管理器中文件树形显示方式
首先是头文件,内容如下: #include <tchar.h> #include "..\CommonFiles\CmnHdr.h" #include <Wind ...
- JAVA实现 springMVC方式的微信接入、实现消息自动回复
前段时间小忙了一阵,微信公众号的开发,从零开始看文档,踩了不少坑,也算是熬过来了,最近考虑做一些总结,方便以后再开发的时候回顾,也给正在做相关项目的同学做个参考. 思路 微信接入:用户消息和开发者需要 ...
- java基础之——DecimalFormat格式化数字
DecimalFormat可以用来格式化数字,例如用来设定保留多少位小数.设定数字分隔符等. 说方法之前,先介绍一下其常用的几个模式占位符: 0 一个数字# 一个数字,不包括 0. 小数的分隔符的占位 ...
- LeetCode——Best Time to Buy and Sell Stock III (股票买卖时机问题3)
问题: Say you have an array for which the ith element is the price of a given stock on day i. Design a ...
- 三言两语之js事件、事件流以及target、currentTarget、this那些事
厉害了我的哥--你是如此简单我却将你给遗忘 放假前再看某文档,里边提到两个我既熟悉又陌生的概念target.currentTarget,说他熟悉我曾经看到过这两个事件对象的异同处,说他陌生吧?很不 ...
- cve-2015-5199漏洞分析
继续之前hackteam的flash漏洞,这次的对象为cve-2015-5199,遂做一下记录. 首先,在该exp中TryExpl函数为漏洞的触发函数,该函数也为本次调试的主要对象,函数的开始首先创建 ...
- Java日期处理
日常工作中经常遇到关于日期的处理,下面把自个写好的Java代码段分享一下,也当做自个的一个备份,同时也欢迎交流,如若分享请注明出处,谢谢. 1.返回两个时间段之间的月份: /** * 返回任意两个月份 ...
- Web前端:11个让你代码整洁的原则
写Web页面就像我们建设房子一样,地基牢固,房子才不会倒.同样的,我们制作Web页面也一样,一个良好的HTML结构是制作一个美丽的网站的开始,同样的,良好的CSS只存在同样良好的HTML中,所以一个干 ...
- YUM源设置
1挂载光盘 先创建一个文件 /aaa 然后挂载mount /dev/cdrom /aaa 进入 /aaa ls 查看是否挂载OK 2进入yum文件夹.将除Media以外的所有文件名改为XXXXXX ...
- android4.4源码下载简介
1. $sudo apt-get install git-core curl2. mkdir ~/bin PATH=~/bin:$PATH3. curl http://commondatastorag ...