cloudera learning5:Hadoop集群高级配置
HDFS-NameNode Tuning:
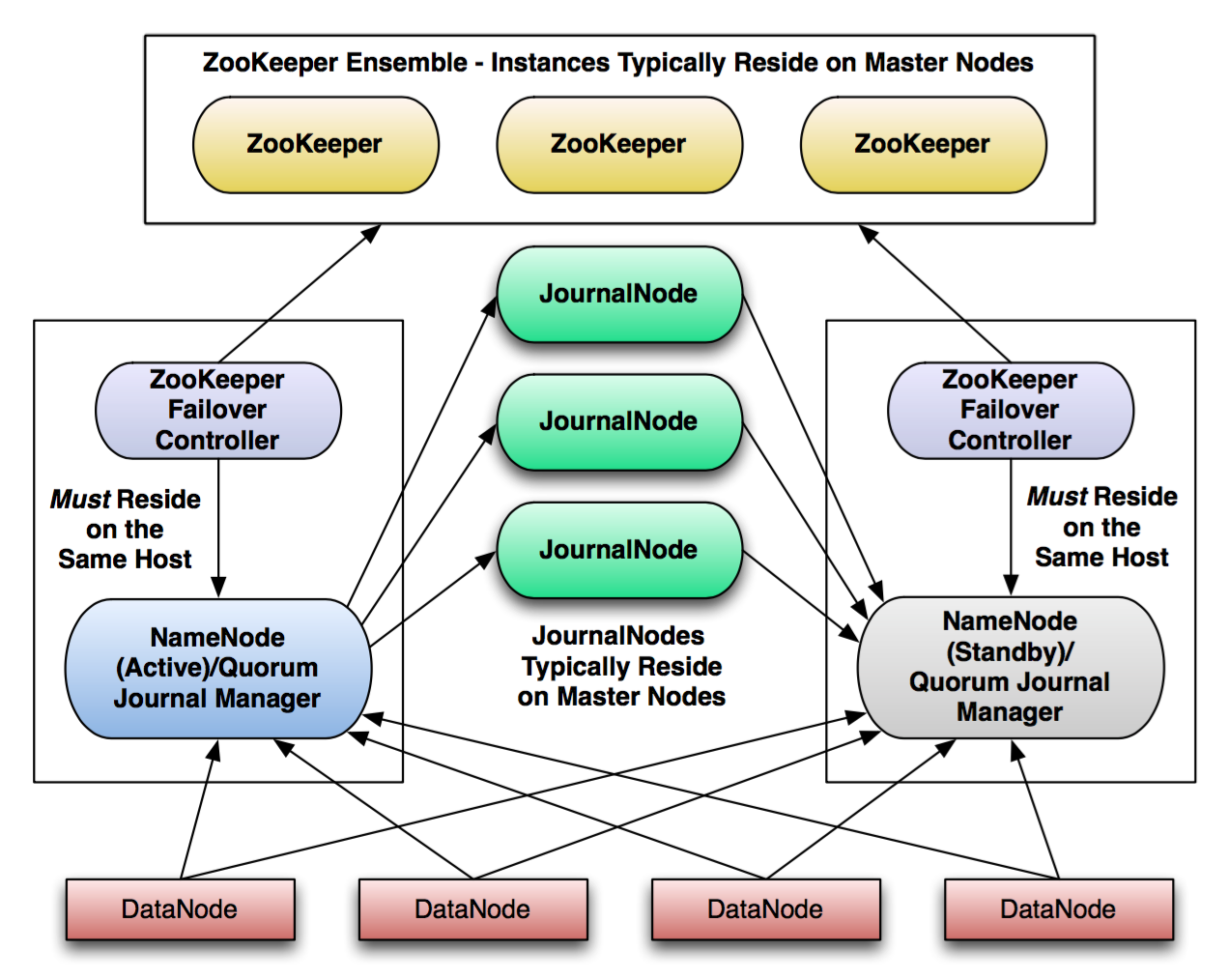
cloudera learning5:Hadoop集群高级配置的更多相关文章
- 【Big Data】HADOOP集群的配置(一)
Hadoop集群的配置(一) 摘要: hadoop集群配置系列文档,是笔者在实验室真机环境实验后整理而得.以便随后工作所需,做以知识整理,另则与博客园朋友分享实验成果,因为笔者在学习初期,也遇到不少问 ...
- 【Big Data】HADOOP集群的配置(二)
Hadoop集群的配置(二) 摘要: hadoop集群配置系列文档,是笔者在实验室真机环境实验后整理而得.以便随后工作所需,做以知识整理,另则与博客园朋友分享实验成果,因为笔者在学习初期,也遇到不少问 ...
- Hadoop的学习前奏(二)——Hadoop集群的配置
前言: Hadoop集群的配置即全然分布式Hadoop配置. 笔者的环境: Linux: CentOS 6.6(Final) x64 JDK: java version "1.7 ...
- Hadoop集群的配置(一)
摘要: hadoop集群配置系列文档,是笔者在实验室真机环境实验后整理而得.以便随后工作所需,做以知识整理,另则与博客园朋友分享实验成果,因为笔者在学习初期,也遇到不少问题.但是网上一些文档大多互相抄 ...
- cloudera learning4:Hadoop集群规划
涉及到一些关于硬件的东西,我也不是很懂,记录下来有待以后学习. Hadoop集群一般都是由小到大,刚开始可能只有4到6个节点,随着存储数据的增加,计算量的增大,内存需求的增加,集群慢慢变大. 比如按照 ...
- hadoop 集群的配置
在经过几天折腾,终于将hadoop环境搭建成功,整个过程中遇到各种坑,反复了很多遍,光虚拟机就重新安装了4.5次,接下来就把搭建的过程详细叙述一下 0.相关工具: 1,系统环境说明: 我这边给出我的集 ...
- hadoop集群默认配置和常用配置【转】
转自http://www.cnblogs.com/ggjucheng/archive/2012/04/17/2454590.html 获取默认配置 配置hadoop,主要是配置core-site.xm ...
- Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS
摘自:http://www.powerxing.com/install-hadoop-cluster/ 本教程讲述如何配置 Hadoop 集群,默认读者已经掌握了 Hadoop 的单机伪分布式配置,否 ...
- hadoop集群默认配置和常用配置
http://www.cnblogs.com/ggjucheng/archive/2012/04/17/2454590.html 获取默认配置 配置hadoop,主要是配置core-site.xml, ...
随机推荐
- Indy FTP 警告:Only one TIdAntiFreeze can be active in an application
> Should I use a AntiFreeze component on every form I have a TIdTCPClient > component? Or is ...
- 如何从零基础学习VR
转载请声明转载地址:http://www.cnblogs.com/Rodolfo/,违者必究. 近期很多搞技术的朋友问我,如何步入VR的圈子?如何从零基础系统性的学习VR技术? 本人将于2017年1月 ...
- JAVA实现 springMVC方式的微信接入、实现消息自动回复
前段时间小忙了一阵,微信公众号的开发,从零开始看文档,踩了不少坑,也算是熬过来了,最近考虑做一些总结,方便以后再开发的时候回顾,也给正在做相关项目的同学做个参考. 思路 微信接入:用户消息和开发者需要 ...
- 查看cpu的信息cat /proc/cpuinfo
cat /proc/cpuinfo processor : vendor_id : GenuineIntel cpu family : model : model name : Intel(R) Co ...
- Tensorflow mlp二分类
只是简单demo, 可以看出tensorflow非常简洁,适合快速实验 import tensorflow as tf import numpy as np import melt_datas ...
- PCA数据降维
Principal Component Analysis 算法优缺点: 优点:降低数据复杂性,识别最重要的多个特征 缺点:不一定需要,且可能损失有用的信息 适用数据类型:数值型数据 算法思想: 降维的 ...
- 弹性布局flex-兼容问题
这里弹性布局的用法就不说了 用过的都知道很方便 虽然现在弹性布局已经实现标准了 但是还是存在一些兼容问题 旧版本 (一些低版本的浏览器) display:-webkit-box; 新版本(目前的标准版 ...
- Delphi基本类型--枚举 子界 集合 数组
[plain] view plain copy <strong>根据枚举定义集合 </strong> TMyColor = (mcBlue, mcRed); TMyColorS ...
- Java 常用方法
java 图片上传from表单必加属性:enctype="multipart/form-data" 1.获取字符串的长度 : length() 2 .判断字符串的前缀或后缀与已知字 ...
- CF #374 (Div. 2) D. 贪心,优先队列或set
1.CF #374 (Div. 2) D. Maxim and Array 2.总结:按绝对值最小贪心下去即可 3.题意:对n个数进行+x或-x的k次操作,要使操作之后的n个数乘积最小. (1)优 ...