Merge:解析on子句和when not match子句的陷阱
在细节上,体现编程的修养。每一位大师,master,其基础必定夯实。废话不多说,直接上干货,Merge子句用于对两个数据表执行数据同步,On子句指定匹配(when matched)条件,When子句指定额外的过滤条件和数据更新逻辑。源表(Source Table)和靶表(Targe Table)的数据行能够匹配成功,这意味着on子句和when match条件都被满足,进入到when matched子句定义的更新代码中,执行数据同步操作;如果不满足on子句,那么必须深入理解不匹配(when not matched)子句的条件,否则,很容易出错。首先查看MSDN对On子句的定义:
ON <merge_search_condition> Specifies the conditions on which source_table_ is joined with target_table to determine where they match.
也就是说,如果两个数据行满足on子句条件,那么数据处理程序跳转到when matched子句;如果两个数据行不满足on子句,那么数据处理程序跳转到when not matched子句。如果在on子句中只指定源表列和靶表列之间的匹配关系,那么同步操作一般不会出现“意外"的问题,意外是指符合设计者的预期。一旦在on子句中试图过滤靶表或源表的数据行,那么,再执行数据同步可能出现异常结果,出现不符合设计者预期的行为。实际上,MSDN已经明确给出提示,不要忽略这个提示,不然,你很可能已经挖了坑而不自知:
It is important to specify only the columns from the target table that are used for matching purposes. That is, specify columns from the target table that are compared to the corresponding column of the source table. Do not attempt to improve query performance by filtering out rows in the target table in the ON clause, such as by specifying AND NOT target_table.column_x = value. Doing so may return unexpected and incorrect results.
在开始测试when not matched子句的陷进之前,使用以下脚本创建示例数据:
create table dbo.dt_source
(
ID int,
Code int
)
go
create table dbo.dt_target
(
ID int,
Code int
)
go
insert into dbo.dt_source
(
ID,
Code
)
values(1,1),(2,1),(3,2),(4,2),(5,0)
GO
insert into dbo.dt_target
(
ID,
Code
)
values(1,1),(6,4)
GO
一,在on子句中过滤源表
1,在Merge的On子句中,使用额外的筛选条件(s.Code>0)对SourceTable进行过滤
对源表进行过滤,初衷是为了将SourceTable中Code>0的数据作为数据源同步到TargetTable,但是,在Merge命令的On子句中,s.Code>0只是一个匹配条件,用于when matched子句;然而,对于when not matched子句,是指不满足on条件:t.id=s.id and s.Code>0 ,这意味着when not matched匹配的查询条件是: t.id<>s.id or s.ID<=0,表达的逻辑是:s.id 和任意一个 t.id 都不相等, 或 s.ID<=0,这使得源表dbo.dt_source中Code<=0的数据行都满足when not matched子句的条件,被插入到dbo.dt_target中。
;merge dbo.dt_target as t
using dbo.dt_source as s
on t.id=s.id and s.Code>0
when matched
then update
set t.code=s.code
when not matched
then insert
(
ID,
Code
)
values
(
s.ID,
s.Code
);
查看TargetTable,Code=0的数据被插入到TargeTable表中,靶表的数据如下:

2,正确的写法:不要试图在on子句中过滤源表
在使用Merge命令同步数据时, 如果要过滤源表,正确的做法是把筛选条件放在所有的when子句中,包括When matched子句和when not matched子句。对on子句添加对源表的过滤条件,在when matched子句中,正常过滤源表,而在when not matched子句,会出现异常。
;merge dbo.dt_target as t
using dbo.dt_source as s
on t.id=s.id
when matched and s.Code>0
then update
set t.code=s.code
when not matched and s.Code>0
then insert
(
ID,
Code
)
values
(
s.ID,
s.Code
);
二,在on子句中过滤靶表(Target Table)
清空测试数据表,插入测试数据
insert into dbo.dt_source
(
ID,
Code
)
values(1,-1),(2,1),(3,2),(4,2),(5,0),(6,7)
GO
insert into dbo.dt_target
(
ID,
Code
)
values(1,1),(6,4)
GO
1,在on子句中对靶表进行过滤
在on子句中指定匹配条件:on t.id=s.id and t.Code<4,指定的时when matched的匹配条件,对于when not matched子句,匹配条件是:t.id<>s.id or t.Code>=4,对于源表数据行Row(6,7),不满足t.id<>s.id,因为存在TargetTableRow(6,4),但是满足 or 的另外一个条件 t.Code>=4, 所以,when not matched语句逻辑结果是true,执行insert语句。
;merge dbo.dt_target as t
using dbo.dt_source as s
on t.id=s.id and t.Code<4
when matched
then update
set t.code=s.code
when not matched
then insert
(
ID,
Code
)
values
(
s.ID,
s.Code
);
TargetTable的结果集如下图,包括(6,7)
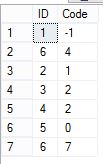
2,分析陷进
这或许是你想要的结果,或许,你的本意是不希望 t.Code>=4的数据行插入到靶表中,如果merge子句要实现的业务逻辑是后者,那么数据同步将出现异常,所以一定要深刻理解when not matched子句的匹配条件,推荐的做法是:不要试图在on子句中过滤源表或靶表,如果必须要过滤数据行,那么请在每个when子句(when matched和when not matched)中,添加额外的and 过滤条件。
Merge:解析on子句和when not match子句的陷阱的更多相关文章
- 1. 安装Oracle,配置环境 2. 实现查询From子句 3. 实现查询where子句 4. 实现查询order by子句
一.环境安装1. 登录:以管理员身份登录 sqlplus 登录名/密码 管理员身份登录:sqlplus system/1234562. 登录后,导入案例.下载scott.sql文件,执行下面一行的命令 ...
- 《读书报告 -- Elasticsearch入门 》--简单使用(2)
<读书报告 – Elasticsearch入门 > ' 第四章 分布式文件存储 这章的主要内容是理解数据如何在分布式系统中存储. 4.1 路由文档到分片 创建一个新文档时,它是如何确定应该 ...
- Neo4j使用Cypher查询图形数据
Neo4j使用Cypher查询图形数据,Cypher是描述性的图形查询语言,语法简单,功能强大,由于Neo4j在图形数据库家族中处于绝对领先的地位,拥有众多的用户基数,使得Cypher成为图形查询语言 ...
- Neo4j 第三篇:Cypher查询入门
本文转载自:https://www.cnblogs.com/ljhdo/p/5516793.html Neo4j使用Cypher查询图形数据,Cypher是描述性的图形查询语言,语法简单,功能强大,由 ...
- Cypher 语句实战
Cypher 语句实战 下载和安装 Neo4j windows 桌面版- 环境设置 https://www.w3cschool.cn/neo4j/neo4j_exe_environment_setup ...
- ElasticSearch 5学习(10)——结构化查询(包括新特性)
之前我们所有的查询都属于命令行查询,但是不利于复杂的查询,而且一般在项目开发中不使用命令行查询方式,只有在调试测试时使用简单命令行查询,但是,如果想要善用搜索,我们必须使用请求体查询(request ...
- ElasticSearch(6)-结构化查询
引用:ElasticSearch权威指南 一.请求体查询 请求体查询 简单查询语句(lite)是一种有效的命令行_adhoc_查询.但是,如果你想要善用搜索,你必须使用请求体查询(request bo ...
- ElasticSearch权威指南学习(结构化查询)
请求体查询 简单查询语句(lite)是一种有效的命令行adhoc查询.但是,如果你想要善用搜索,你必须使用请求体查询(request body search)API. 空查询 我们以最简单的 sear ...
- ES相关信息
漫画版原理介绍 搜索引擎的核心:倒排索引 elasticsearch 基于Lucene的,封装成一个restful的api,通过api就可进行操作(Lucene是一个apache开放源代码的全文检索引 ...
随机推荐
- CSS| position定位和float浮动
对基础知识再度做个巩固和梳理. 一.position定位 (一):position的属性 1.absolute:生成绝对定位的元素,相对于最近一级定位不是static的父元素来进行定位: 2.rela ...
- 单点登录SSO的实现原理 (转)
单点登录SSO(Single Sign On)说得简单点就是在一个多系统共存的环境下,用户在一处登录后,就不用在其他系统中登录,也就是用户的一次登录能得到其他所有系统的信任.单点登录在大型网站里使用得 ...
- 转:Web 开发中很实用的10个效果【附源码下载】
原文地址:http://www.cnblogs.com/lhb25/p/10-useful-web-effect.html 在工作中,我们可能会用到各种交互效果.而这些效果在平常翻看文章的时候碰到很多 ...
- Huawei vlan 配置及vlan 间通讯
Huawei Vlan配置及vlan 间通讯实例 组网需求:汇聚层交换机做为 PC 电脑的网关, PC3直连 SW2 属于 vlan 2,网关为 vlanif 2 接口地址192.168.2.1/24 ...
- 团队作业7——第二次项目冲刺(Beta版本)day1
项目成员: 曾海明(组长):201421122036 于波(组员):201421122058 蓝朝浩(组员):201421122048 王珏 (组员):201421122057 叶赐红(组员):20 ...
- 基于Java反射的map自动装配JavaBean工具类设计
我们平时在用Myabtis时不是常常需要用map来传递参数,大体是如下的步骤: public List<Role> findRoles(Map<String,Object> p ...
- [python] 私有变量和私有方法
1.在Python中要想定义的方法或者变量只在类内部使用不被外部调用,可以在方法和变量前面加 两个 下划线 #-*- coding:utf-8 -*- class A(object): name = ...
- 打开Excel时提示“向程序发送命令时出现问题”
Excel界面中点击“文件”,选择“选项”,在弹出的“Excel选项”对话框中依次点击“高级”-“常规”,然后取消勾选”忽略使用动态数据交换(DDE)的其他应用程序”:
- mapreduce设置setMapOutputKeyClass与setMapOutputValueClass原因
一般的mapreduce的wordcount程序如下: public class WcMapper extends Mapper<LongWritable, Text, Text, LongWr ...
- 8、JVM--虚拟机字节码执行引擎
8.1.概述 执行引擎是Java虚拟机最核心的组成部分之一.“虚拟机”是一个相对于“物理机”的概念,这两种机器都有代码执行能力,其区别是物理机的执行引擎是直接建立在处理器.硬件.指令集和操作系统层面上 ...