笔记 Bioinformatics Algorithms Chapter1
Chapter1 WHERE IN THE GENOME DOES DNA REPLICATION BEGIN

一、
·聚合酶启动结构域会结合上游序列的一些位点,这些位点有多个,且特异,并且分布在两条链上。通过计算,找到出现频率最高的k-mer可能为为聚合酶结合位点:dnaA BOX。
但是如何定位Ori的大概位置呢?
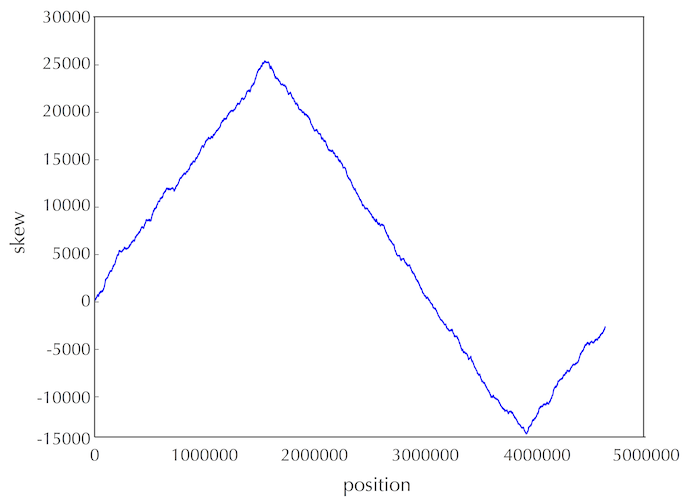
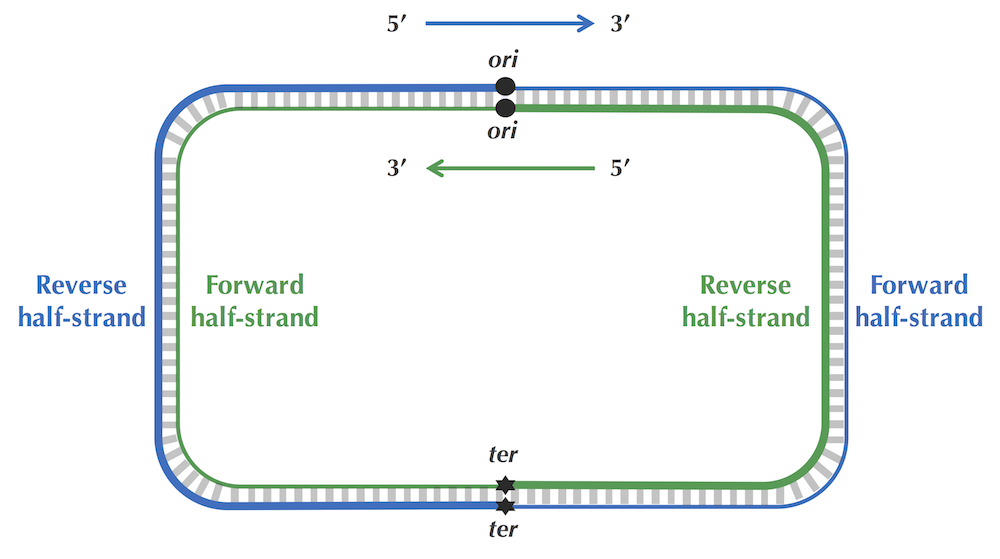
·DNA链复制的不对称性,其导致突变速率的不对称,使得有(forward链C->T,脱氨基)的趋势。由此,依据skew增的处于forward链,skew减的处于reverse链。(skew = G - C ,逢G+1 逢C-1)图中最低点代表Ori区域。
由此可以大致推测出ori的位置,然后在此位置内(100bp),寻找出现频率大的pattern,作为可能的dnaA box。
·由于k-mer之间,会有碱基的若干差异,故应使用能容错的计数方法。
二、
提出问题:The Clump Finding Problem
Find every k-mer that forms a clump in the genome.
ComputingFrequencies(Text, k) #一种遍历一次计算频率的‘桶’方法
for i ← 0 to 4k − 1
FrequencyArray(i) ← 0
for i ← 0 to |Text| − k
Pattern ← Text(i, k)
j ← PatternToNumber(Pattern) #hash
FrequencyArray(j) ← FrequencyArray(j) + 1
return FrequencyArray
ComputingFrequencies(Text, k)这是一种计算kmer频率的方法
FindingFrequentWordsBySorting(Text , k) #排序法
FrequentPatterns ← an empty set
for i ← 0 to |Text| − k
Pattern ← Text(i, k)
Index(i) ← PatternToNumber(Pattern)
Count(i) ← 1
SortedIndex ← Sort(Index)
for i ← 1 to |Text| − k
if SortedIndex(i) = SortedIndex(i − 1)
Count(i) = Count(i − 1) + 1
maxCount ← maximum value in the array Count
for i ← 0 to |Text| − k
if Count(i) = maxCount
Pattern ← NumberToPattern(SortedIndex(i), k)
add Pattern to the set FrequentPatterns
return FrequentPatterns
FindingFrequentWordsBySorting(Text , k)这是另一种计算kmer频率的方法
ClumpFinding(Genome, k, L, t)
FrequentPatterns ← an empty set
for i ← 0 to 4k − 1
Clump(i) ← 0
for i ← 0 to |Genome| − L
Text ← the string of length L starting at position i in Genome
FrequencyArray ← ComputingFrequencies(Text, k)
for index ← 0 to 4k − 1
if FrequencyArray(index) ≥ t
Clump(index) ← 1
for i ← 0 to 4k − 1
if Clump(i) = 1
Pattern ← NumberToPattern(i, k)
add Pattern to the set FrequentPatterns
return FrequentPatterns
我们不用每次挪动一位搜寻窗就重新计算kmer频率,搜寻窗每挪一位,原来的第一个kmer将少一个,结尾后一个kmer将多一个
BetterClumpFinding(Genome, k, t, L)
FrequentPatterns ← an empty set
for i ← 0 to 4k − 1
Clump(i) ← 0
Text ← Genome(0, L)
FrequencyArray ← ComputingFrequencies(Text, k)
for i ← 0 to 4k − 1
if FrequencyArray(i) ≥ t
Clump(i) ← 1
for i ← 1 to |Genome| − L
FirstPattern ← Genome(i − 1, k)
index ← PatternToNumber(FirstPattern)
FrequencyArray(index) ← FrequencyArray(index) − 1
LastPattern ← Genome(i + L − k, k)
index ← PatternToNumber(LastPattern)
FrequencyArray(index) ← FrequencyArray(index) + 1
if FrequencyArray(index) ≥ t
Clump(index) ← 1
for i ← 0 to 4k − 1
if Clump(i) = 1
Pattern ← NumberToPattern(i, k)
add Pattern to the set FrequentPatterns
return FrequentPatterns
笔记 Bioinformatics Algorithms Chapter1的更多相关文章
- 读书笔记 Bioinformatics Algorithms Chapter5
Chapter5 HOW DO WE COMPARE DNA SEQUENCES Bioinformatics Algorithms-An_Active Learning Approach htt ...
- 笔记 Bioinformatics Algorithms Chapter7
一.Lloyd算法 算法1 Lloyd Algorithm k_mean clustering * Centers to Clusters: After centers have been selec ...
- 笔记 Bioinformatics Algorithms Chapter2
Chapter2 WHICH DNA PATTERNS PLAY THE ROLE OF MOLECULAR CLOCKS 寻找模序 一. 转录因子会结合基因上游的特定序列,调控基因的转录表达,但是在 ...
- How do I learn machine learning?
https://www.quora.com/How-do-I-learn-machine-learning-1?redirected_qid=6578644 How Can I Learn X? ...
- Protocol Informatics (PI项目)【基于网络轨迹的协议逆向工程文献学习】
Protocol Informatics[基于网络轨迹的协议逆向工程文献学习]by tsy 声明: 1)本报告由博客园bitpeach撰写,版权所有,免费转载,请注明出处,并请勿作商业用途.恕作者著作 ...
- 《Algorithms算法》笔记:元素排序(4)——凸包问题
<Algorithms算法>笔记:元素排序(4)——凸包问题 Algorithms算法笔记元素排序4凸包问题 凸包问题 凸包问题的应用 凸包的几何性质 Graham 扫描算法 代码 凸包问 ...
- 《Algorithms算法》笔记:元素排序(3)——洗牌算法
<Algorithms算法>笔记:元素排序(3)——洗牌算法 Algorithms算法笔记元素排序3洗牌算法 洗牌算法 排序洗牌 Knuth洗牌 Knuth洗牌代码 洗牌算法 洗牌的思想很 ...
- 《深入PHP与jQuery开发》读书笔记——Chapter1
由于去实习过后,发现真正的后台也要懂前端啊,感觉javascript不懂,但是之前用过jQuery感觉不错,很方便,省去了一些内部函数的实现. 看了这一本<深入PHP与jQuery开发>, ...
- 《Algorithms 4th Edition》读书笔记——3.1 符号表(Elementary Symbol Tables)-Ⅳ
3.1.4 无序链表中的顺序查找 符号表中使用的数据结构的一个简单选择是链表,每个结点存储一个键值对,如以下代码所示.get()的实现即为遍历链表,用equals()方法比较需被查找的键和每个节点中的 ...
随机推荐
- JFinal文件上传时直接使用getPara()去接受表单的数据接收到的数据一直是null?
解决方案: 在文件上传页面form 标签中使用: enctype="multipart/form-data" 在controller类中先调用getFile系列方法才能使getPa ...
- maven构建ssh工程
1.1 需求 在web工程的基础上实现ssh工程的创建,规范依赖管理. 1.2 数据库环境 使用之前学习hibernate创建的数据库: 1.3 创建父工程 选择创建Maven Project ...
- Memcached使用与纠错(附代码和相关dll)
今天没事研究一下,谁想到遇到了几个dll找不到,网上也不好找到,索性功夫不负有心人.贴出代码和相关的dll Memcached代码:(网上都是的,很多人都保存了这个代码) using Memcache ...
- Vue Create 创建一个新项目 命令行创建和视图创建
Vue Create 创建一个新项目 命令行创建和视图创建 开始之前 你可以先 >>:cd desktop[将安装目录切换到桌面] >>:vue -V :Vue CLI 3.0 ...
- python3.6.5 路径处理与规范化
在Linux和Mac平台上,该函数会原样返回path,在windows平台上会将路径中所有字符转换为小写,并将所有斜杠转换为饭斜杠. >>> os.path.normcase('c: ...
- Android开发之自定义Dialog简单实现
本文着重研究了自定义对话框,通过一下步骤即可清晰的理解原理,通过更改界面设置和style类型,可以应用在各种各样适合自己的App中. 首先来看一下效果图: 首先是activity的界面 点击了上述图片 ...
- 如何在Fragment中获取context
文章转载自http://blog.csdn.net/demonliuhui/article/details/51511136 这里仅供自己学习参考: Context,中文直译为“上下文”,SDK中对其 ...
- 4A - 排序
输入一行数字,如果我们把这行数字中的‘5’都看成空格,那么就得到一行用空格分割的若干非负整数(可能有些整数以‘0’开头,这些头部的‘0’应该被忽略掉,除非这个整数就是由若干个‘0’组成的,这时这个整数 ...
- 快速掌握Ajax-Ajax基础实例(Ajax返回Json在Java中的实现)
(转)实例二:Ajax返回Json在Java中的实现 转自http://www.cnblogs.com/lsnproj/archive/2012/02/09/2341524.html#2995114 ...
- XStream将XML转javaben,出现多余的tag,导致出错
今天在测试银联无卡快捷支付的案例时,多了一个多tag兼容性测试,它是指银联的XML报文中会出现多余的tag,如果我们用XStream解析的时候,没有Javabean的字段可以对应上,就会报错!提示: ...