写一个简单的C词法分析器
写一个简单的C词法分析器
在写本文过程中,我参考了《词法分析器的实现》中的一些内容。这里我们主要讨论写一个C语言的词法分析器。
一、关键字
首先,C语言中关键字有:
auto、break、case、char、const、continue、default、do、double、else、enum、extern、float、for、goto、if、int、long、register、return、short、signed、sizeof、static、struct、switch、typedef、unsigned、union、void、volatile、while等共32个关键字。
二、运算符
C语言中的运算符有:
(、)、[、]、->、.、!、~、++、--、-、()、*、&、*、/、%、+、-、<<、>>、<、<=、>、>=、==、!=、&、^、|、&&、||、?:、=、+=、-=、*=、/=、%=、&=、^=、|=、<<=、>>=、,、等共45个运算符。
说明:-减号与-负号在词法阶段无法判别,需要在语法或予以阶段判别;同理*乘号与*指针操作符也是这样的。
三、界符
另外C语言还有以下界符:
;、{、}、:
四、标示符
C语言中标示符的定义为:开头可以是下划线或字母,后面可以是下划线、字母或数字。
五、常数
整形数和浮点数
六、空白符
C语言中的空白符有:空格符、制表符、换行符,这些空白符在词法分析阶段可以被忽略。
七、注释
C语言中的注释形式为:/*…*/,可以多行注释。
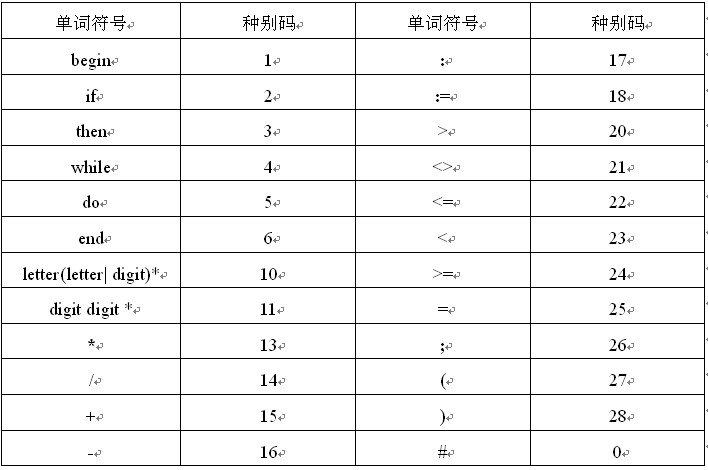
下面我们给出C程序中token和其对应的种别码:
|
单词符号 |
种别码 |
单词符号 |
种别码 |
单词符号 |
种别码 |
|
auto |
1 |
union |
28 |
[ |
55 |
|
break |
2 |
unsigned |
29 |
] |
56 |
|
case |
3 |
void |
30 |
^ |
57 |
|
char |
4 |
volatile |
31 |
^= |
58 |
|
const |
5 |
while |
32 |
{ |
59 |
|
continue |
6 |
- |
33 |
| |
60 |
|
default |
7 |
-- |
34 |
|| |
61 |
|
do |
8 |
-= |
35 |
|= |
62 |
|
double |
9 |
-> |
36 |
} |
63 |
|
else |
10 |
! |
37 |
~ |
64 |
|
enum |
11 |
!= |
38 |
+ |
65 |
|
extern |
12 |
% |
39 |
++ |
66 |
|
float |
13 |
%= |
40 |
+= |
67 |
|
for |
14 |
& |
41 |
< |
68 |
|
goto |
15 |
&& |
42 |
<< |
69 |
|
if |
16 |
&= |
43 |
<<= |
70 |
|
int |
17 |
( |
44 |
<= |
71 |
|
long |
18 |
) |
45 |
= |
72 |
|
register |
19 |
* |
46 |
== |
73 |
|
return |
20 |
*= |
47 |
> |
74 |
|
short |
21 |
, |
48 |
>= |
75 |
|
signed |
22 |
. |
49 |
>> |
76 |
|
sizeof |
23 |
/ |
50 |
>>= |
77 |
|
static |
24 |
/= |
51 |
" |
78 |
|
struct |
25 |
: |
52 |
/*注释*/ |
79 |
|
switch |
26 |
; |
53 |
常数 |
80 |
|
typedef |
27 |
? |
54 |
标识符 |
81 |
我们的词法分析程序根据所给的源代码程序,输出的是二元组:<单词符号, 种别码>。对于常数的形式,我们也是直接以字符串的形式表达。
以上token存放在c_keys.txt文件中
// token
auto
break
case
char
const
continue
default
do
double
else
enum
extern
float
for
goto
if
int
long
register
return
short
signed
sizeof
static
struct
switch
typedef
union
unsigned
void
volatile
while
-
--
-=
->
!
!=
%
%=
&
&&
&=
(
)
*
*=
,
.
/
/=
:
;
?
[
]
^
^=
{
|
||
|=
}
~
+
++
+=
<
<<
<<=
<=
=
==
>
>=
>>
>>=
"
/*注释*/
常数
标识符
C 词法分析器程序如下:
// C语言词法分析器
#include <cstdio>
#include <cstring>
#include <iostream>
#include <map>
#include <string>
#include <fstream>
#include <sstream>
#include <vector>
using namespace std; struct _2tup
{
string token;
int id;
}; bool is_blank(char ch)
{
return ch == ' ' || ch == ' ';
} bool adv(string& token, char& ch, string::size_type& pos, const string& prog)
{
token += ch;
++pos;
if (pos >= prog.size())
{
return false;
}
else
{
ch = prog[pos];
return true;
}
} bool gofor(char& ch, string::size_type& pos, const string& prog)
{
++pos;
if (pos >= prog.size())
{
return false;
}
else
{
ch = prog[pos];
return true;
}
} _2tup scanner(const string& prog, string::size_type& pos, const map<string, int>& keys, int& row)
{
/*
if
标示符
else if
数字
else
符号
*/
_2tup ret;
string token;
int id = ; char ch;
ch = prog[pos]; while(is_blank(ch))
{
++pos;
ch = prog[pos];
}
// 判断标示符、关键字
if ((ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z') || ch == '_')
{
while((ch >= '' && ch <= '') || (ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z') || ch == '_')
{
token += ch;
if (!gofor(ch, pos, prog))
{
break;
}
//++pos;
//ch = prog[pos];
}
// 这里先看做都是其他标示符
id = keys.size(); // 验证是否是关键字
map<string, int>::const_iterator cit = keys.find(token);
if (cit != keys.end())
{
id = cit->second;
}
}
// 识别常数
else if ((ch >= '' && ch <= '') || ch == '.')
{
while (ch >= '' && ch <= '' || ch == '.')
{
token += ch;
if (!gofor(ch, pos, prog))
{
break;
}
//++pos;
//ch = prog[pos];
}
id = keys.size() - ;
int dot_num = ;
for (string::size_type i = ; i != token.size(); ++i)
{
if (token[i] == '.')
{
++dot_num;
}
}
if (dot_num > )
{
id = -;
}
}
else
{
map<string, int>::const_iterator cit;
switch (ch)
{
case '-': // - 操作符
token += ch;
if (gofor(ch, pos, prog))
//++pos;
//ch = prog[pos];
{
if (ch == '-' || ch == '=' || ch == '>') // -- 操作符
{
token += ch;
gofor(ch, pos, prog);
//++pos;
//ch = prog[pos];
}
}
cit = keys.find(token);
if (cit != keys.end())
{
id = cit->second;
}
break; case '!': // ! 操作符
case '%': // % 操作符
case '*':
case '^':
case '=':
token += ch;
if (gofor(ch, pos, prog))
//++pos;
//ch = prog[pos];
{
if (ch == '=') // !% %= 操作符
{
token += ch;
gofor(ch, pos, prog);
//++pos;
//ch = prog[pos];
}
}
cit = keys.find(token);
if (cit != keys.end())
{
id = cit->second;
}
break; case '/': // / 操作符
token += ch;
if (gofor(ch, pos, prog))
//++pos;
//ch = prog[pos];
{
if (ch == '=') // /= 操作符
{
token += ch;
gofor(ch, pos, prog);
//++pos;
//ch = prog[pos];
}
else if (ch == '/') // 单行注释
{
token += ch;
++pos;
while (pos < prog.size())
{
ch = prog[pos];
if (ch == '\n')
{
break;
}
token += ch;
++pos;
}
if (pos >= prog.size())
{
;
}
else
{
;
}
id = keys.size() - ;
break;
}
else if (ch == '*') // 注释
{
// 实现方式1
//string::size_type p1 = pos - 1;
//
//string::size_type p2 = prog.find("*/", p1);
//if (p2 != string::npos)
//{
// token = prog.substr(p1, p2 - p1 + 2); // pos = p2 + 2;
// ch = prog[pos]; // id = keys.size() - 2;
//}
//else
//{
// id = -1;
//}
//break; // 注释的另一种实现,为了得到出错行号
token += ch;
//++pos;
if (!gofor(ch, pos, prog))
{
token += "\n!!!注释错误!!!";
id = -;
break;
}
//ch = prog[pos];
if (pos + >= prog.size())
{
token += ch;
token += "\n!!!注释错误!!!";
id = -;
break;
}
char xh = prog[pos + ];
while (ch != '*' || xh != '/')
{
token += ch;
if (ch == '\n')
{
++row;
}
//++pos;
if (!gofor(ch, pos, prog))
{
token += "\n!!!注释错误!!!";
id = -;
ret.token = token;
ret.id = id;
return ret;
}
//ch = prog[pos];
if (pos + >= prog.size())
{
token += ch;
token += "\n!!!注释错误!!!";
id = -;
ret.token = token;
ret.id = id;
return ret;
}
xh = prog[pos + ];
}
token += ch;
token += xh;
pos += ;
ch = prog[pos];
id = keys.size() - ;
break;
}
}
cit = keys.find(token);
if (cit != keys.end())
{
id = cit->second;
}
break; case '&':
token += ch;
if (gofor(ch, pos, prog))
//++pos;
//ch = prog[pos];
{
if (ch == '&' || ch == '=')
{
token += ch;
gofor(ch, pos, prog);
//++pos;
//ch = prog[pos];
}
}
cit = keys.find(token);
if (cit != keys.end())
{
id = cit->second;
}
break; case '|':
token += ch;
if (gofor(ch, pos, prog))
//++pos;
//ch = prog[pos];
{
if (ch == '|' || ch == '=')
{
token += ch;
gofor(ch, pos, prog);
//++pos;
//ch = prog[pos];
}
}
cit = keys.find(token);
if (cit != keys.end())
{
id = cit->second;
}
break; case '+':
token += ch;
if (gofor(ch, pos, prog))
//++pos;
//ch = prog[pos];
{
if (ch == '+' || ch == '=')
{
token += ch;
gofor(ch, pos, prog);
//++pos;
//ch = prog[pos];
}
}
cit = keys.find(token);
if (cit != keys.end())
{
id = cit->second;
}
break; case '<':
token += ch;
if (gofor(ch, pos, prog))
//++pos;
//ch = prog[pos];
{
if (ch == '<')
{
token += ch;
if (gofor(ch, pos, prog))
//++pos;
//ch = prog[pos];
{
if (ch == '=')
{
token += ch;
gofor(ch, pos, prog);
//++pos;
//ch = prog[pos];
}
}
}
else if (ch == '=')
{
token += ch;
gofor(ch, pos, prog);
//++pos;
//ch = prog[ch];
}
}
cit = keys.find(token);
if (cit != keys.end())
{
id = cit->second;
}
break; case '>':
token += ch;
if (gofor(ch, pos, prog))
//++pos;
//ch = prog[pos];
{
if (ch == '>')
{
token += ch;
if (gofor(ch, pos, prog))
//++pos;
//ch = prog[pos];
{
if (ch == '=')
{
token += ch;
gofor(ch, pos, prog);
//++pos;
//ch = prog[pos];
}
}
}
else if (ch == '=')
{
token += ch;
gofor(ch, pos, prog);
//++pos;
//ch = prog[pos];
}
}
cit = keys.find(token);
if (cit != keys.end())
{
id = cit->second;
}
break; case '(':
case ')':
case ',':
case '.':
case ':':
case ';':
case '?':
case '[':
case ']':
case '{':
case '}':
case '~':
case '"':
token += ch;
gofor(ch, pos, prog);
//++pos;
//ch = prog[pos];
cit = keys.find(token);
if (cit != keys.end())
{
id = cit->second;
}
break; //case '#':
// id = 0;
// token += ch;
// break; case '\n':
token += "换行";
++pos;
ch = prog[pos];
id = -;
break;
default:
token += "错误";
++pos;
ch = prog[pos];
id = -;
break;
}
}
ret.token = token;
ret.id = id; return ret;
} void init_keys(const string& file, map<string, int>& keys)
{
ifstream fin(file.c_str());
if (!fin)
{
cerr << file << " doesn't exist!" << endl;
exit();
}
keys.clear();
string line;
string key;
int id;
while (getline(fin, line))
{
istringstream sin(line);
sin >> key >> id;
keys[key] = id;
}
} void read_prog(const string& file, string& prog)
{
ifstream fin(file.c_str());
if (!fin)
{
cerr << file << " error!" << endl;
exit();
}
prog.clear();
string line;
while (getline(fin, line))
{
prog += line + '\n';
}
} int main()
{
map<string, int> keys;
init_keys("c_keys.txt", keys); string prog;
read_prog("prog.txt", prog); vector< _2tup > tups;
string token, id; string::size_type pos = ;
int row = ; _2tup tu; cout << prog << endl << endl; // prog += "#"; // 标识充值,其实可以检测 pos 来判别是否终止 int no = ; do
{
tu = scanner(prog, pos, keys, row); switch (tu.id)
{
case -:
++no;
cout << no << ": ";
cout << "Error in row" << row << "!" << '<' << tu.token<< "," << tu.id << '>' << endl;
tups.push_back(tu);
break;
case -:
++row;
// cout << '<' << tu.token<< "," << tu.id << '>' << endl;
break;
default:
++no;
cout << no << ": ";
cout << '<' << tu.token<< "," << tu.id << '>' << endl;
tups.push_back(tu);
break;
}
} while (/*tu.id != 0 && */pos < prog.size()); cout << endl << tups.size() << endl;
return ;
}
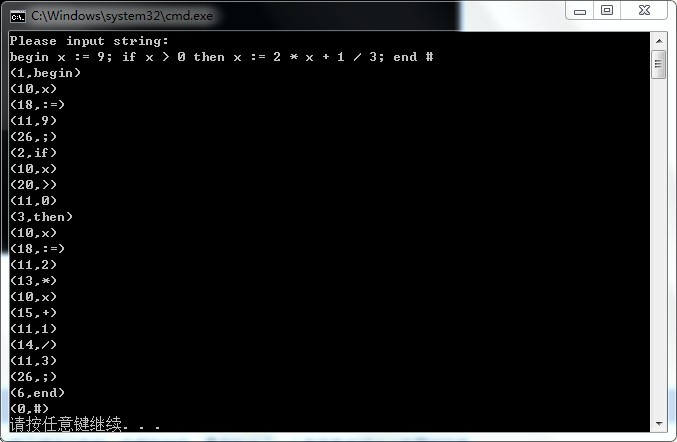
测试样例1:
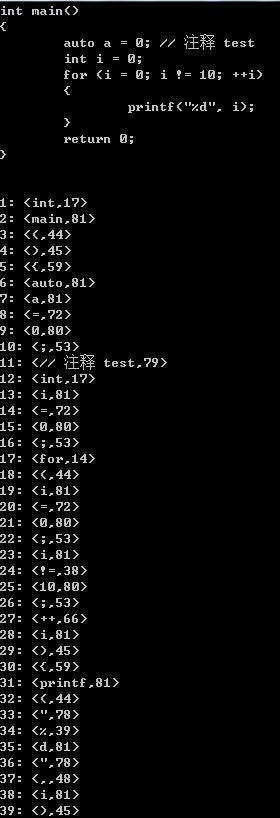
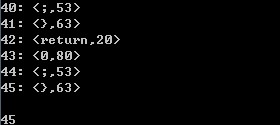
int main()
{
auto a = ; // 注释 test
int i = ;
for (i = ; i != ; ++i)
{
printf("%d", i);
}
return ;
}
测试样例2
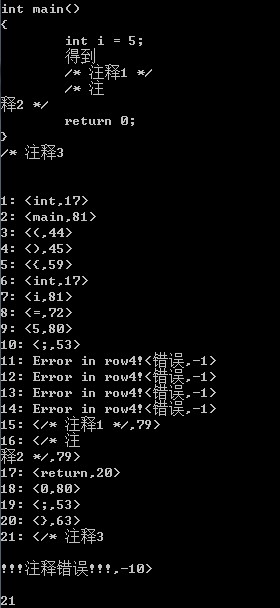
int main()
{
int i = ;
得到
/* 注释1 */
/* 注
释2 */
return ;
}
/* 注释3
总结
以上我们实现了一个C语言的词法分析器,其原理主要就是根据C语言中各个token的规则,逐位分析。
词法分析后续工作还有语法分析、语义分析等等。
另外还有制作一个过滤注释的程序、C预处理器等。
附:《词法分析器的实现》中的相关内容
该文中关键字有:
begin、if、then、while、do、end
运算符有:
:=、+、-、*、/、<、<=、<>、>、>=、=、;、(、)、#
标示符ID和整形常熟的定义为:
ID = letter(letter|digit)*
NUM = digit digit*
空白符由空格、制表符、换行符组成,空格用来分割ID、NUM、运算符、界符、关键字等。词法分析阶段通常将其忽略。
各种token及对应的种别码
程序输出二元组(syn, token或sum),其中syn为单词种别码,token为存放的单词自身字符串,sum为整形常数。
程序如下(有些改动):
#include <cstdio>
#include <cstring>
#include <iostream>
using namespace std; char prog[], token[];
char ch; int syn, p, m = , n, row, sum = ;
char* rwtab[] = {"begin", "if", "then", "while", "do", "end"}; void scanner()
{
/*
if
标示符
else if
数字
else
符号
*/
for (n = ; n < ; ++n)
{
token[n] = NULL;
}
ch = prog[p++]; while(ch == ' ')
{
ch = prog[p];
++p;
}
if ((ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z'))
{
m = ;
while((ch >= '' && ch <= '') || (ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z'))
{
token[m++] = ch;
ch = prog[p++];
}
token[m++] = '\0';
--p;
syn = ;
for (n = ; n < ; ++n)
{
if (strcmp(token, rwtab[n]) == )
{
syn = n + ;
break;
}
}
}
else if ((ch >= '' && ch <= ''))
{
sum = ;
while (ch >= '' && ch <= '')
{
sum = sum * + ch - '';
ch = prog[p++];
}
--p;
syn = ;
if (sum > )
{
syn = -;
}
}
else switch (ch)
{
case '<':
m = ;
token[m++] = ch;
ch = prog[p++];
if (ch == '>')
{
syn = ;
token[m++] = ch;
}
else if (ch == '=')
{
syn = ;
token[m++] = ch;
}
else
{
syn = ;
--p;
}
break;
case '>':
m = ;
token[m++] = ch;
ch = prog[p++];
if (ch == '=')
{
syn = ;
token[m++] = ch;
}
else
{
syn = ;
--p;
}
break;
case ':':
m = ;
token[m++] = ch;
ch = prog[p++];
if (ch == '=')
{
syn = ;
token[m++] = ch;
}
else
{
syn = ;
--p;
}
break;
case '*':
syn = ;
token[] = ch;
break;
case '/':
syn = ;
token[] = ch;
break;
case '+':
syn = ;
token[] = ch;
break;
case '-':
syn = ;
token[] = ch;
break;
case '=':
syn = ;
token[] = ch;
break;
case ';':
syn = ;
token[] = ch;
break;
case '(':
syn = ;
token[] = ch;
break;
case ')':
syn = ;
token[] = ch;
break;
case '#':
syn = ;
token[] = ch;
break;
case '\n':
syn = -;
break;
default:
syn = -;
break;
}
} int main()
{
p = ;
row = ;
cout << "Please input string:" << endl; do
{
cin.get(ch);
prog[p++] = ch;
} while (ch != '#'); p = ; do
{
scanner();
switch (syn)
{
case :
cout << '(' << syn << "," << sum << ")" << endl;
break;
case -:
cout << "Error in row" << row << "!" << endl;
break;
case -:
++row;
break;
default:
cout << "(" << syn << "," << token << ")" << endl;
break;
}
} while (syn != );
}
写一个简单的C词法分析器的更多相关文章
- 用Python写一个简单的Web框架
一.概述 二.从demo_app开始 三.WSGI中的application 四.区分URL 五.重构 1.正则匹配URL 2.DRY 3.抽象出框架 六.参考 一.概述 在Python中,WSGI( ...
- 如何写一个简单的http服务器
最近几天用C++写了一个简单的HTTP服务器,作为学习网络编程和Linux环境编程的练手项目,这篇文章记录我在写一个HTTP服务器过程中遇到的问题和学习到的知识. 服务器的源代码放在Github. H ...
- 如何写一个简单的shell
如何写一个简单的shell 看完<UNIX环境高级编程>后我就一直想写一个简单的shell来作为练习,因为有事断断续续的写了好几个月,如今写了差不多来总结一下. 源代码放在了Github: ...
- 分享:计算机图形学期末作业!!利用WebGL的第三方库three.js写一个简单的网页版“我的世界小游戏”
这几天一直在忙着期末考试,所以一直没有更新我的博客,今天刚把我的期末作业完成了,心情澎湃,所以晚上不管怎么样,我也要写一篇博客纪念一下我上课都没有听,还是通过强大的度娘完成了我的作业的经历.(当然作业 ...
- 一步一步写一个简单通用的makefile(三)
上一篇一步一步写一个简单通用的makefile(二) 里面的makefile 实现对通用的代码进行编译,这一章我将会对上一次的makefile 进行进一步的优化. 优化后的makefile: #Hel ...
- Java写一个简单学生管理系统
其实作为一名Java的程序猿,无论你是初学也好,大神也罢,学生管理系统一直都是一个非常好的例子,初学者主要是用数组.List等等来写出一个简易的学生管理系统,二.牛逼一点的大神则用数据库+swing来 ...
- (2)自己写一个简单的servle容器
自己写一个简单的servlet,能够跑一个简单的servlet,说明一下逻辑. 首先是写一个简单的servlet,这就关联到javax.servlet和javax.servlet.http这两个包的类 ...
- express 写一个简单的web app
之前写过一个简单的web app, 能够完成注册登录,展示列表,CURD 但是版本好像旧了,今天想写一个简单的API 供移动端调用 1.下载最新的node https://nodejs.org/zh- ...
- (原创)如何使用boost.asio写一个简单的通信程序(二)
先说下上一篇文章中提到的保持io_service::run不退出的简单办法.因为只要异步事件队列中有事件,io_service::run就会一直阻塞不退出,所以只要保证异步事件队列中一直有事件就行了, ...
随机推荐
- jquery iframe父子框架中的元素访问方法
在web开发中,经常会用到iframe,难免会碰到需要在父窗口中使用iframe中的元素.或者在iframe框架中使用父窗口的元素 js 在父窗口中获取iframe中的元素 1. 格式:window. ...
- MVC005之页面调用控制器中的方法
描述:控制器在传给页面数据时,有时我们需要对传过来的数据进行二次处理 如: 1:传过来部门编码,但页面上要显示为部门名称 2:格式转换等 我们在写aspx时一般在cs文件中写一个protected的方 ...
- putty颜色调整
右键window窗口--Changing Setting--window--Colours: * Default Foreground: 255/255/255 * Default Backgroun ...
- java定义object数组(可以存储String或int等多种类型)
需求| 想在数组中既有String类型又有int等类型,所以需要定义数组为Object类型 背景| 现在有一个字符串params,需要对其进行逗号分隔赋值到数组里,这时遇到了个问题,即使直接定义的 ...
- Zabbix3.2下Template App Zabbix Server+Template OS Linux Item
序号 Name Key 返回值 释义1 Agent ping agent.ping 1 就是ping一下2 Avaliable memory vm.memory.size[available] 563 ...
- as3.0两点之间简单的运动,斜着运动,任意两点
import flash.utils.Timer;import flash.events.TimerEvent;//fixed结束点//sprite初始点var fixedX:Number = fix ...
- c++ - Linking problems due to symbols with abi::cxx11?
看错误内容: /data/projects/LipReadingSDKGPU/lib/cwlibs/libLipReading.so: undefined reference to `tensorfl ...
- 如何解决make: Nothing to be done for `all' 的方法
正常情况下,当文件没有更新且已经编译过时,再次make就会报这个错误,表示文件未更新,不需要编译. 如果异常情况没有检测到更新文件,或者想要强制重新编译,只需要make clean,再次编译即可.
- hdu 1540 线段树
这题的意思是现在有一些村庄成一条直线排列,现在有三个操作,D:摧毁一个指定的村庄,Q:询问与指定村庄相连的村庄个数, 就是这个村庄向左和向右数村庄数量,遇到尽头或损坏的村庄为止,这个就是与这个村庄相连 ...
- 使用phpStudyy运行tipask
tipask官网:https://www.tipask.com/tipask源码下载:https://www.tipask.com/download.html 可参考此处安装文档的链接 除此之外可以参 ...