CephFS cache tier实践
这是一篇分享文,作者因为最近想深入研究下ceph的cache pool,作者写的文章非常的好,这里先直接翻译这篇文章,然后再加入我自己的相关数据
blog原文
作者想启动blog写下自己的Openstack和Ceph的相关经验,第一个话题就选择了 Ceph cache tiering , 作者的使用场景为短时间的虚拟机,用来跑测试的,这种场景他们准备用Nvme做一个缓冲池来加速的虚拟机
cache 相关的一些参数
target_max_bytes
target_max_objects
cache_target_dirty_ratio
cache_target_full_ratio
cache_min_flush_age
cache_min_evict_age
Jewel版本还新加入了一个参数
cache_target_dirty_high_ratio
作者的想法是先把数据写入到缓冲池当中,等后面某个时刻再写入到真实的存储池的当中
Flushing vs. Evicting
Flushing是将缓冲池中的数据刷到真实的存储池当中去,但是并不去删除缓冲池里面缓存的数据,只有clean的数据才能被evic,如果是dirty的数据做evic,那么先要flush到真实存储池,然后再删除掉
Cache 调整
Ceph的是不能够自动确定缓存池的大小,所以这里需要配置一个缓冲池的绝对大小,flush/evic将无法工作。
设置了上限以后,相关的参数就是cache_target_full_ratio和cache_target_dirty_ratio。这些参数是控制什么时候进行flush和evic的
这个dirty ratio是比较难设置的值,需要根据场景进行相关的调整
新版本里面到了dirty_high_ratio才开始下刷
还有cache_min_flush_age和cache_min_evict_age这个控制,这个一般来说到了设定的阀值前,这些对象的留存时间应该是要够老的,能够被触发清理掉的
通过ceph df detail 可以观测你的存储池的数据的情况
里面会有一些0字节对象的,缓冲池的0字节对象是数据已经被删除了,防止刷新的时候又要操作对象。在真实存储池中的0字节对象是数据已经在缓冲池当中,但没有刷新到缓冲池
案例测试
基于上面的控制,下面我们来具体看下这些参数的实际效果是怎样的,这样我们才能真正在实际场景当中做到精准的控制
首先我们要对参数分类
- 缓冲池的总大小,这个大小分成两类一个对象个数控制,一个大小的控制
- flush和evic的百分比,这个百分比既按照大小进行控制,也按照对象进行控制
- flush和evic的时间控制
分好类以后,我们就开始我们的测试,基于对象的数目的控制,比较容易观察,我们就用对象控制来举例子
创建一个缓冲池的环境
ceph osd pool create testpool 24 24
ceph osd pool create cachepool 24 24
ceph osd tier add testpool cachepool
ceph osd tier cache-mode cachepool writeback
ceph osd tier set-overlay testpool cachepool
ceph osd pool set cachepool hit_set_type bloom
ceph osd pool set cachepool hit_set_count 1
ceph osd pool set cachepool hit_set_period 3600
上面的操作是基本的一些操作、我们现在做参数相关的调整
ceph osd pool set cachepool target_max_bytes 1000000000000
为了排除干扰,我们把 target_max_bytes设置成了1T,我们的测试数据很少,肯定不会触发这个大小
ceph osd pool set cachepool target_max_objects 1000
设置缓冲池的对象max为1000
ceph osd pool set cachepool cache_target_dirty_ratio 0.4
设置dirty_ratio为0.4,也就是0.4为判断为dirty的阀值
ceph osd pool set cachepool cache_target_full_ratio 0.8
设置cache_target_full_ratio为0.8,即超过80%的时候需要evic
ceph osd pool set cachepool cache_min_flush_age 600
ceph osd pool set cachepool cache_min_evict_age 1800
设置两个flush和evic的时间,这个时间周期比我写入的数据的时间周期大很多,这个等下会调整这个
开启一个终端动态观察存储池的对象变化
[root@lab8106 ~]# watch ceph df
Every 2.0s: ceph df
GLOBAL:
SIZE AVAIL RAW USED %RAW USED
834G 833G 958M 0.11
POOLS:
NAME ID USED %USED MAX AVAIL OBJECTS
rbd 0 0 0 277G 0
metadata 1 61953k 0.01 416G 39
data 2 50500k 0.01 416G 50501
testpool 5 0 0 416G 0
cachepool 6 0 0 416G 0
尝试写入数据并且观察,到了1000左右的时候停止
rados -p testpool bench 100 write -b 4K --no-cleanup
可以观察到cachepool的对象数目大概在1100-1200之间,一直写也会是这个数字,在停止写以后,观察cachepool的对象数目在960左右,我们设置的 target_max_objects 为1000,在超过了这个值以后,并且写停止的情况下,系统会把这个cache pool的对象控制在比target_max少50左右,现在我们修改下 cache_min_evict_age 这个参数,看下会发生些什么
我们把这个参数调整为30
ceph osd pool set cachepool cache_min_evict_age 30
设置完了以后,可以看到cache pool的对象数目在 744左右,现在再写入数据,然后等待,看下会是多少,还是756,如果按我们设置的 cache_target_full_ratio 0.8就正好是800,我们尝试再次调整大cache_min_evict_age看下情况,对象维持在960左右,根据这个测试,基本上可以看出来是如何控制缓存的数据了,下面用一张图来看下这个问题
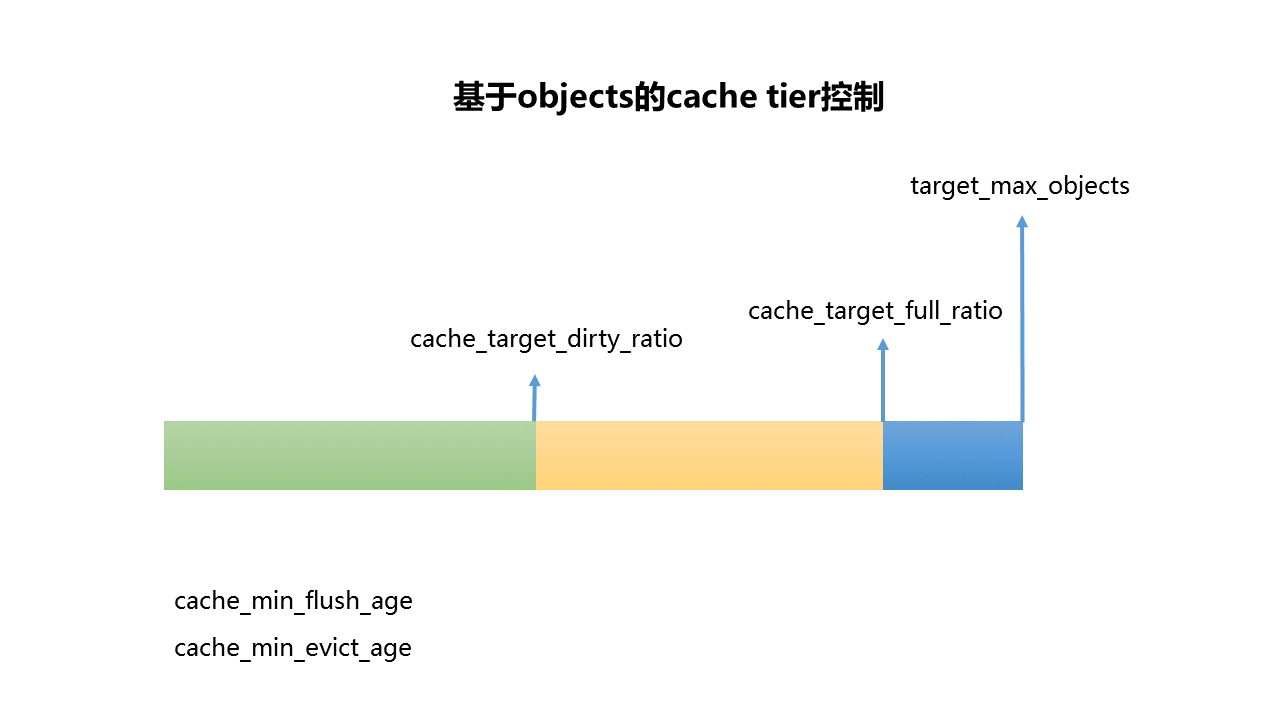
来总结一下:
- 如果cache pool对象到了 target_max_objects,那么会边flush,边evic,然后因为前面有客户端请求,这个时候实际是会阻塞的
- 如果停止了写请求,系统会自动将cache pool的对象控制在比 target_max_objects 少一点点
- 如果时间周期到了cache_min_evict_age,那么系统会自动将cache pool的对象控制在比 cache_target_full_ratio 少一点点
- 同理如果到了cache_min_flush_age,那么会将对象往真实的存储池flush到 cache_target_dirty_ratio 少一点点
也就是ratio是给定了一个比例,然后时间到了就去将缓存控制到指定的ratio,这个地方就需要根据需要去控制缓冲池数据是留有多少的缓存余地的
使用命令清空缓冲池的数据,会将数据flush到真实存储池,然后将数据evic掉
关于缓冲池的就写这么多了,实际环境是要根据自己的使用场景去制定这些值的,从而能保证缓冲池能真正起到作用,上面的例子是基于对象的控制的,基于大小的控制是一样的,只是将对象数的设置换成了大小即可,然后尽量去放大对象的控制
rados -p cachepool cache-try-flush-evict-all
变更记录
| Why | Who | When |
|---|---|---|
| 创建 | 武汉-运维-磨渣 | 2016-11-07 |
| 完成缓冲池相关 | 武汉-运维-磨渣 | 2016-11-08 |
CephFS cache tier实践的更多相关文章
- redis实现cache系统实践(六)
1. 介绍 rails中就自带有cache功能,不过它默认是用文件来存储数据的.我们要改为使用redis来存储.而且我们也需要把sessions也存放到redis中.关于rails实现cache功能的 ...
- 转-4年!我对OpenStack运维架构的总结
4年!我对OpenStack运维架构的总结 原创: 徐超 云技术之家 今天 前言 应“云技术社区”北极熊之邀,写点东西.思来想去云计算范畴实在广泛,自然就聊点最近话题异常火热,让广大云计算从业者爱之深 ...
- 对OpenStack运维架构的总结(转)
这里,仅从技术角度出发,谈谈OpenStack云平台在部署.架构和运维实施等方面的感想. 缘起,在2014年大二首次接触到OpenStack,当时国内外资料远没有当前这么丰富,为安装一个OpenSta ...
- Ceph分层存储分析
最近弄Ceph集群考虑要不要加入分层存储 因此花了点时间研究了下 1,首先肯定要弄清Ceph分层存储的结构 ,结构图大概就是下图所示 缓存层(A cache tier)为Ceph客户端提供更好的I/O ...
- php笔记07:http响应详解(禁用缓存设置和文件下载)
演示如何通过Http响应控制页面缓存,在默认情况下,浏览器是会缓存页面的1.禁用缓存设置 (1).我在...\htdocs\http文件夹,写一个cache.php文件如下: <?php ech ...
- ceph之纠删码
转自:http://m.blog.csdn.net/blog/skdkjxy/45695355 一.概述 按照误码控制的不同功能,可分为检错码.纠错码和纠删码等. 检错码仅具备识别错码功能 而无纠正错 ...
- Ceph源码解析:概念
Peering:一个PG内的所有副本通过PG日志来达成数据一致的过程.(某PG如果处于Peering将不能对外提供读写服务) Recovery:根据Peering的过程中产生的.依据PG日志推算出的不 ...
- 浅谈Ceph纠删码
目 录第1章 引言 1.1 文档说明 1.2 参考文档 第2章 纠删码概念和原理 2.1 概念 2.2 原理 第3章 CEPH纠删码介绍 3.1 CEPH纠删码用途 3.2 CEPH纠删码库 3.3 ...
- Tier和RBD Cache的区别
相同点 缓存 数据不会持久保存在ssd或者内存:预读回写直写 都需要解决缓存数据和磁盘数据不一致和“内存页”置换的问题. 差异点 缓存的位置不同,tier是rados层在osd端进行数据缓存,也就是说 ...
随机推荐
- 提取swagger内容到csv表格,excel可打开
swagger生成的页面api接口统计,有几种方法 直接在前端用js提取出来,较麻烦(不推荐,不同版本的页面生成的标签有可能不一样,因此可能提取不出来) //apilet a = document.g ...
- snappy压缩/解压库
snappy snappy是由google开发的压缩/解压C++库,注重压缩速度,压缩后文件大小比其它算法大一些 snappy在64位x86并且是小端的cpu上性能最佳 在Intel(R) Core( ...
- shell脚本获取随机数
$RANDOM系统变量 在bash中,支持$RANDOM系统变量,范围是 [0, 32767] #!/bin/bash set -e randN() { local N=$1 echo $(($RAN ...
- C语言的污垢,一个能污染内存的神秘操作!神级坑位再现~
本文目的是为了更好的理解指针和内存管理 背景 我们定义一个变量A,修改另外一个一个变量B,导致A的值被修改,我们称它为内存污染. 案例 如下程序,正常的预期输出应该是:97 98 256 ,但正确的结 ...
- kubernetes:用label让pod在指定的node上运行(kubernetes1.18.3)
一,为什么要为node指定label? 通常scheduler会把pod调度到所有可用的Node,有的情况下我们希望能把 Pod 部署到指定的 Node, 例如: 有的Node上配备了速度更快的SSD ...
- centos8安装fastdfs6.06集群方式三之:storage的安装/配置/运行
一,查看本地centos的版本 [root@localhost lib]# cat /etc/redhat-release CentOS Linux release 8.1.1911 (Core) 说 ...
- 第十八章 HTTPS介绍及实战演练
一.HTTPS介绍 1.概述 为什么需要使用HTTPS,因为HTTP不安全,当我们使用http网站时,会遭到劫持和篡改,如果采用https协议,那么数据在传输过程中是加密的,所以黑客无法窃取或者篡改数 ...
- qemu-kvm安装and配置桥接和SR-IOV
kvm和docker的区别:kvm是全虚拟化,需要模拟各种硬件,docker是容器,共享宿主机的CPU,内存,swap等.本文安装的qemu-kvm属于kvm虚拟化,其中:kvm负责cpu虚拟化和内存 ...
- Win10中装Win10---virtualbox虚拟机的安装及拓展
最近在准备一档专栏时,发现我电脑中已经把一些环境配置完了,卸掉重装又显得麻烦,于是我就求助于虚拟机,虚拟机确实是个很好的东西,不久前我的一个伙伴向我请教虚拟机怎么装,发现这玩意三言两语还很难说清,于是 ...
- spring与缓存注解,以及encache缓存使用
随着时间的积累,应用的使用用户不断增加,数据规模也越来越大,往往数据库查询操作会成为影响用户使用体验的瓶颈,此时使用缓存往往是解决这一问题非常好的手段之一.Spring 3开始提供了强大的基于注解的缓 ...