使用Lists.partition切分性能优化
项目实战
影拓邦电影同步中,使用Lists.partition按500条长度进行切分,来实现es的同步。
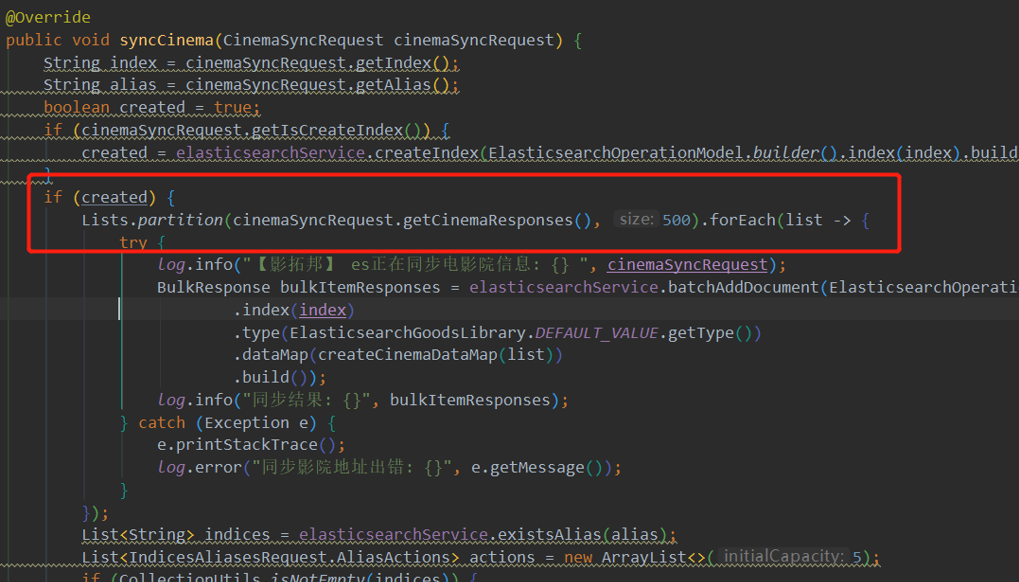
切分的List为
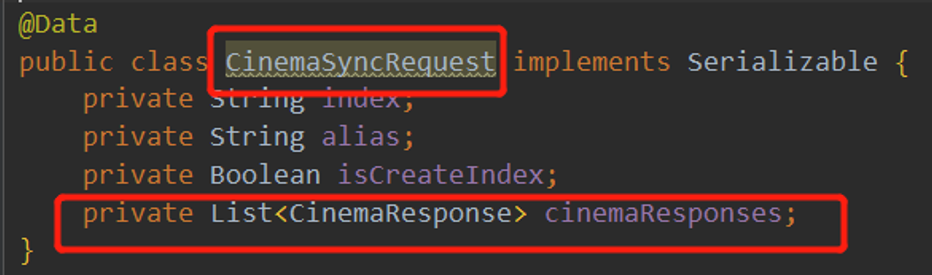
使用介绍及示例
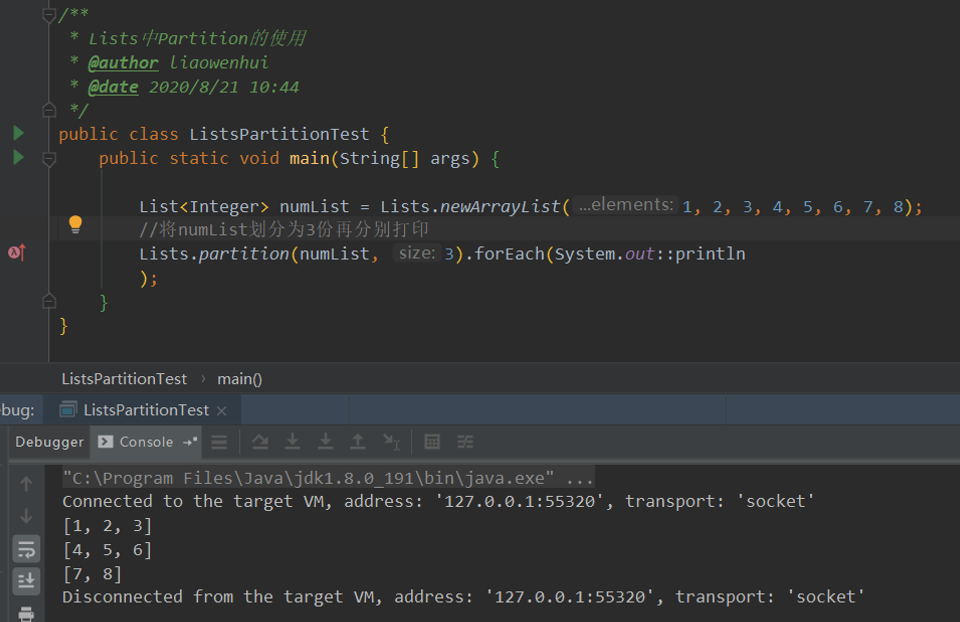
将list集合按指定长度进行切分,返回新的List<List<??>>集合,如下的:
List<List<Integer>> lists=Lists.partition(numList,切分数);
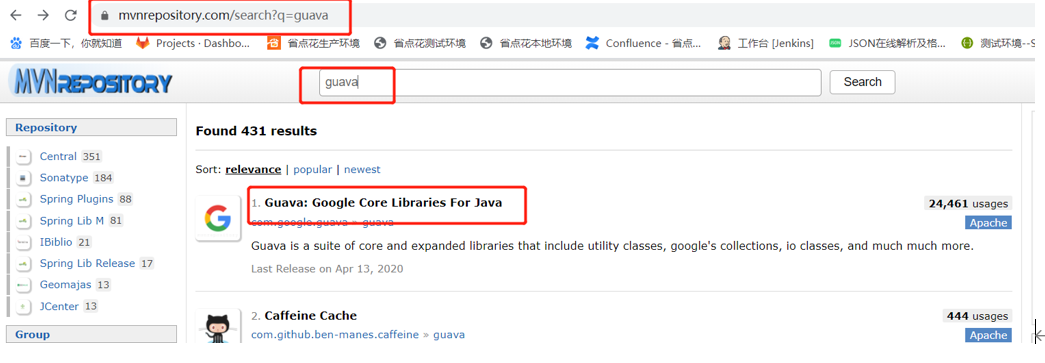
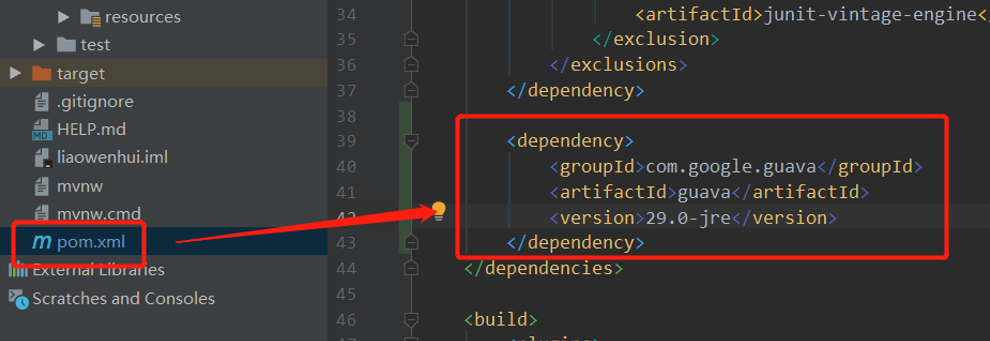
添加依赖
https://mvnrepository.com/search?q=guava仓库中搜索guava获取依赖
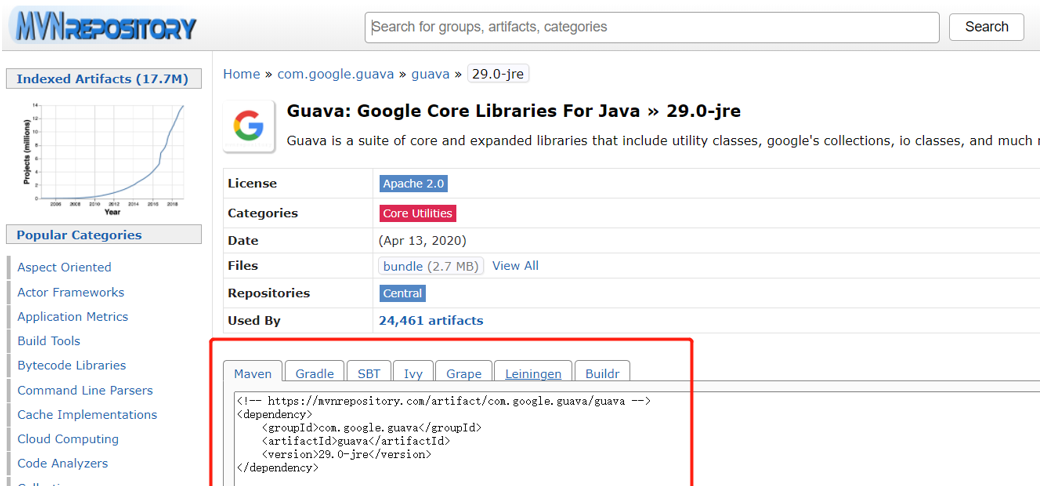
添加依赖到pom文件
示例
使用Lists.partition切分性能优化的更多相关文章
- List集合工具类之"将list集合按"指定长度"进行切分Lists.partition和ListUtils.partition"
将list集合按"指定长度"进行切分,返回新的List<List<类型>>集合,如下的: 方法1:List<List<Integer>& ...
- hadoop JOB的性能优化实践
使用了几个月的hadoopMR,对遇到过的性能问题做点笔记,这里只涉及job的性能优化,没有接触到 hadoop集群,操作系统,任务调度策略这些方面的问题. hadoop MR在做大数据量分析时候有限 ...
- Spark 3.x Spark Core详解 & 性能优化
Spark Core 1. 概述 Spark 是一种基于内存的快速.通用.可扩展的大数据分析计算引擎 1.1 Hadoop vs Spark 上面流程对应Hadoop的处理流程,下面对应着Spark的 ...
- 消息队列的一些场景及源码分析,RocketMQ使用相关问题及性能优化
前文目录链接参考: 消息队列的一些场景及源码分析,RocketMQ使用相关问题及性能优化 https://www.cnblogs.com/yizhiamumu/p/16694126.html 消息队列 ...
- MySQL性能优化总结
一.MySQL的主要适用场景 1.Web网站系统 2.日志记录系统 3.数据仓库系统 4.嵌入式系统 二.MySQL架构图: 三.MySQL存储引擎概述 1)MyISAM存储引擎 MyISAM存储引擎 ...
- (转)Web性能优化方案
第一章 打开网站慢现状分析 在公司访问部署在IDC机房的VIP网站时会感觉很慢.是什么原因造成的?为了缩短页面的响应时间,改进我们的用户体验,我们需要知道用户的时间花在等待什么东西上. 可以跟踪一下我 ...
- 【转载】 Spark性能优化指南——基础篇
转自:http://tech.meituan.com/spark-tuning-basic.html?from=timeline 前言 开发调优 调优概述 原则一:避免创建重复的RDD 原则二:尽可能 ...
- HBase设计与开发性能优化(转)
本文主要是从HBase应用程序设计与开发的角度,总结几种常用的性能优化方法.有关HBase系统配置级别的优化,这里涉及的不多,这部分可以参考:淘宝Ken Wu同学的博客. 1. 表的设计 1.1 Pr ...
- 让DB2跑得更快——DB2内部解析与性能优化
让DB2跑得更快——DB2内部解析与性能优化 (DB2数据库领域的精彩强音,DB2技巧精髓的热心分享,资深数据库专家牛新庄.干毅民.成孜论.唐志刚联袂推荐!) 洪烨著 2013年10月出版 定价:7 ...
随机推荐
- 【JAVA】SSM开源项目源码--城市学院移动后勤-毕业设计(Spring SpringMvc Mybatis Mui Redis )
项目简介 大学时期老师给我做的项目,学校后勤管理中心,也作为毕业设计项目. 有 后勤保修 二手交易 失物招领 后勤通知 等功能. 城市学院移动后勤 有APP端(webapp)和WEB端(PC) 后端使 ...
- 颜色直方图(Color Histogram)
数字成像中的颜色直方图是对给定图像中具有相同颜色的像素的频率进行计算的一种方法.这种方法通常被转换成一个图形,以帮助分析和调整图像中的平衡.几乎所有的照片编辑软件和大量的数码相机都具有颜色直方图的查看 ...
- Jmeter(8)分布式测试
通过Jmeter远程启动功能,把一台windows机器作为控制器,远程控制其他多个Windows或linux压力机,把压力分散到多台执行机器上,从而实现高并发,并在控制机上搜集测试结果 Jmeter分 ...
- Git的使用与五大场景的运用
目录 一.Git的基础 1.Git的基本运作流程 (1) workspace->index->Repository (2) checkout (3) pull, push, fetch/c ...
- 七牛云上传视频(后端获取tolen)
参照网址 https://developer.qiniu.com/kodo/sdk/1242/python #pip install qiniufrom qiniu import Auth #需要填写 ...
- Windows脚本转换Liunx识别并执行
1.执行安装: yum install -y dos2unix 插件2.执行 dos2unix test.sh3.赋值权限 chmod +x test.sh
- 附029.Kubernetes安全之网络策略
目录 环境构建 基础环境构建 网络测试 安全策略 策略配置 策略测试 ingress方向测试 egress方向测试 to和from行为 默认策略 环境构建 基础环境构建 [root@master01 ...
- ASP.NET Core WebAPI实现本地化多语言(单资源文件)
在Startup ConfigureServices 注册本地化所需要的服务AddLocalization和 Configure<RequestLocalizationOptions> p ...
- IIS安装 URL Rewrite Module 2.1
短地址http://www.iis.net/extensions/URLRewrite 下载页面https://www.iis.net/downloads/microsoft/url-rewrite# ...
- winform 跨线程 调用控件
public delegate void rtbCallBack(string txt); public void rtbAddText(string txt) { if (this.rtb.Invo ...