动画演示Sunday字符串匹配算法——比KMP算法快七倍!极易理解!
前言
上一篇我用动画的方式向大家详细说明了KMP算法(没看过的同学可以回去看看)。
这次我依旧采用动画的方式向大家介绍另一个你用一次就会爱上的字符串匹配算法:Sunday算法,希望能收获你的点赞关注收藏与转发哟!
KMP算法是一个里程碑似的算法,它的出现宣告了人类是找到线性时间复杂度的字符串匹配算法的。在这之后,出现了许多的字符串匹配算法,比如BM算法和Sunday算法。
这些算法在时间复杂度上都已经达到了线性时间。但是在实际应用的时候所耗费的时间却还是有所不同。
BM算法在实际应用中的效率已经达到了KMP算法的四五倍。
而Sunday算法的效率甚至犹在BM算法之上。
并且若是两种算法都了解的同学会明白:
Sunday算法比起BM算法来,真的极其容易理解。
正文
行,咱对Sunday算法的吹捧先到这为止,下面开始正戏!
PS:以下将带匹配字符串称为文本串,将用来匹配的字符串称为模式串。
为什么说Sunday算法极易理解呢?
因为它比暴力匹配算法只多了一个步骤而已!
话不多说,直接上我精心制作的GIF动态图:
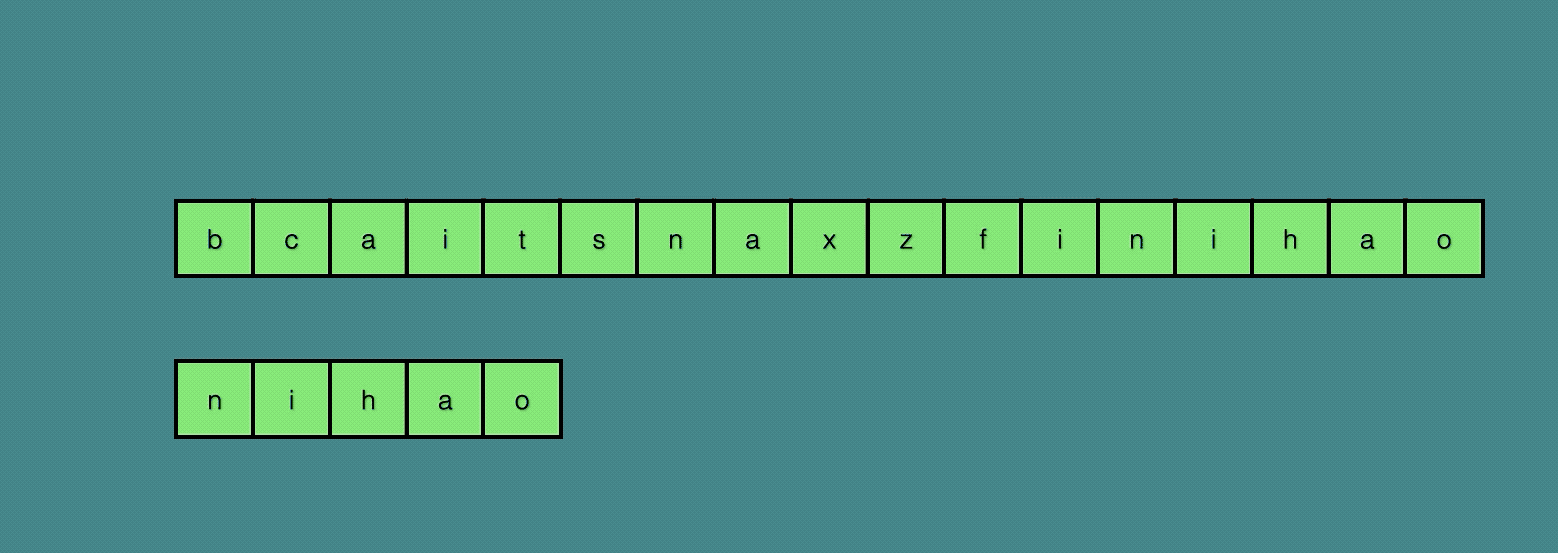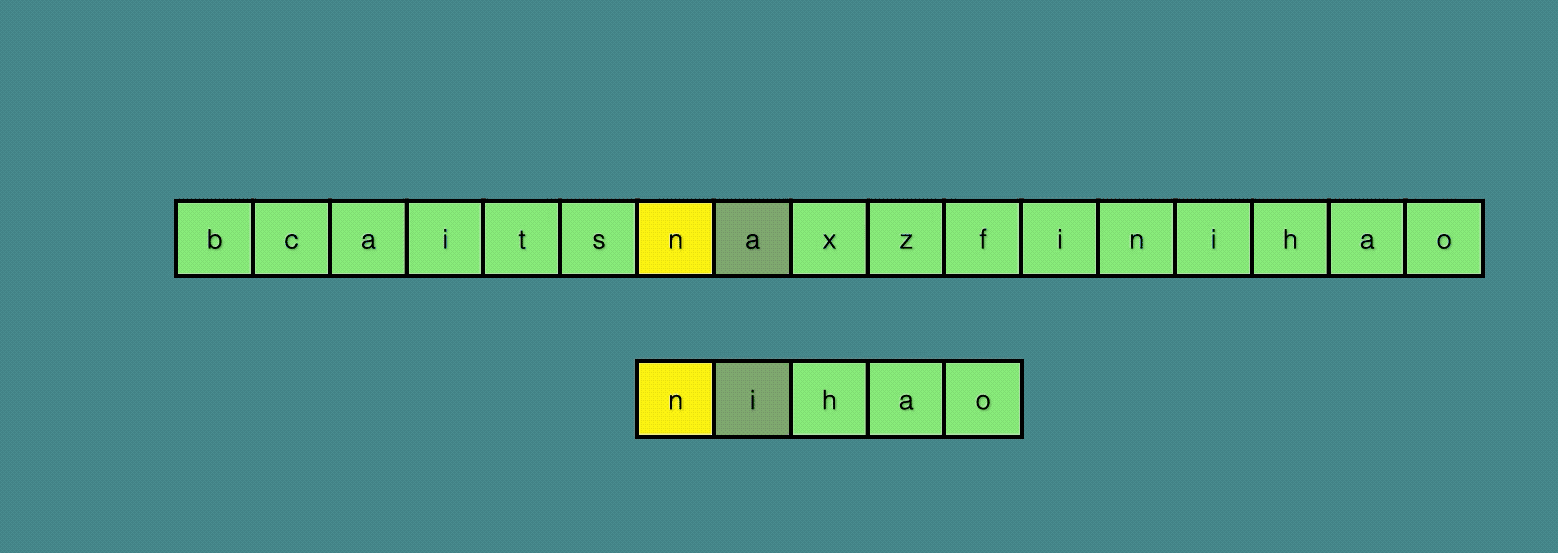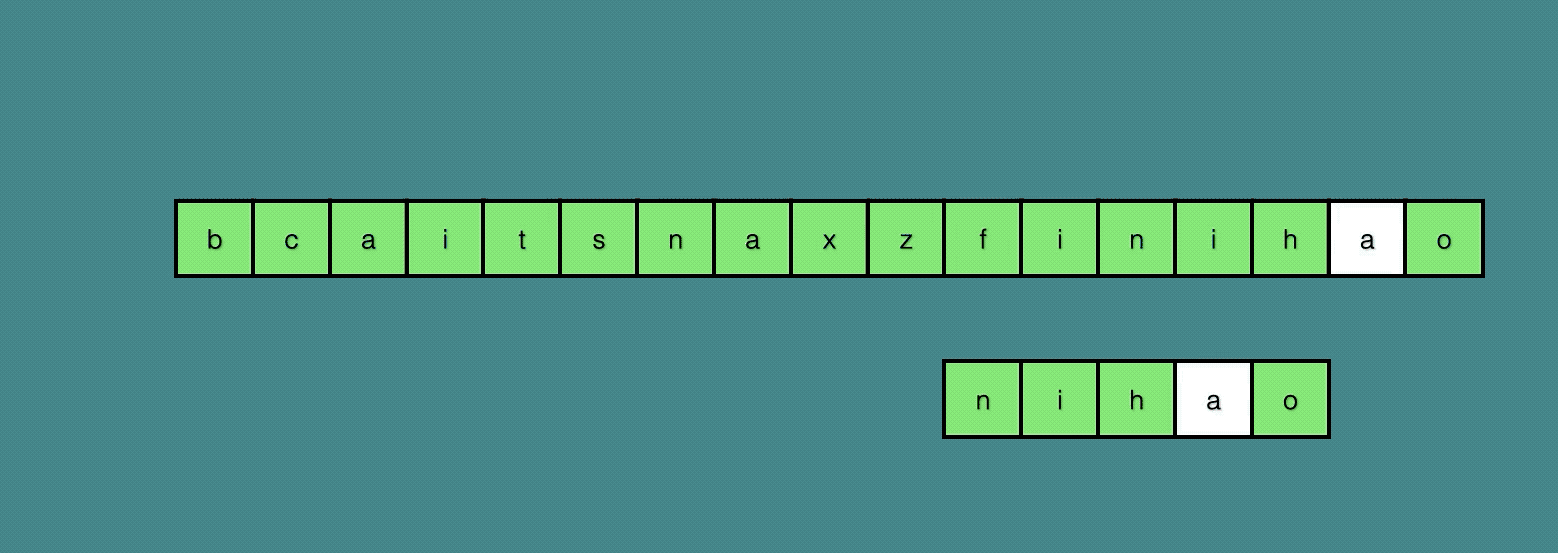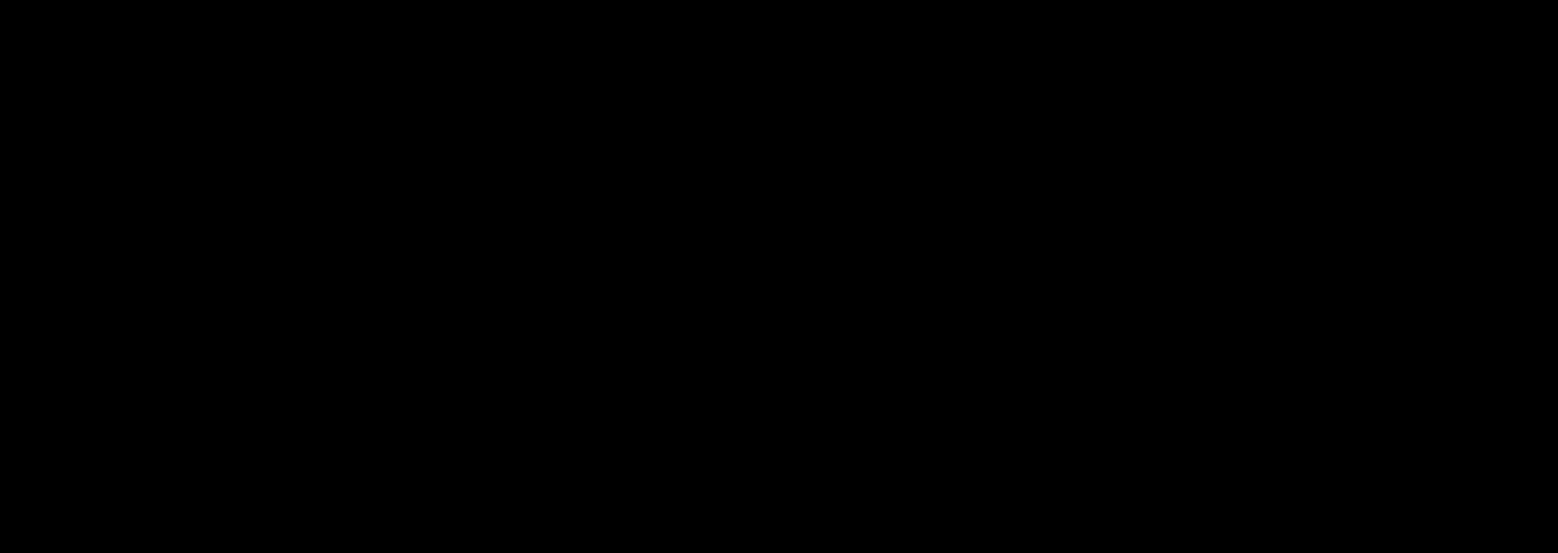
可以看到,我们只移动了三次,就直接找到了最终的结果。
Sunday算法是从前往后匹配的算法(BM算法是从后向前的),在匹配失败时重点关注的是文本串中参加匹配的最末位字符的下一位字符。
如果该字符没有在模式串中出现则直接跳过,即移动位数 = 模式串长度 + 1。
否则,其移动位数 = 模式串长度 - 该字符最右出现的位置(以0开始) = 模式串中该字符最右出现的位置到尾部的距离 + 1。
Sunday算法最巧妙的地方,就在于它发现匹配失败之后可以直接考察文本串中参加匹配的最末尾字符的下一个字符。
在python代码中,我们利用字典来存储模式串中每个字符最后出现的索引,这样在前期只需O(M),M为模式串长度的时间即可做完前期准备,然后再进行查询都是O(1)的时间。
同时为了防止越界,我在下面贴出来的python代码中手动在字符串末尾加上了一个'\0'字符。
代码
class Sunday(object):
def __init__(self, pattern:str):
# 模式串和其长度
self.pattern, self.length = pattern, len(pattern)
# 根据模式串构建的偏移字典
self.shift_dict = {}
# 构建字典
for index, value in enumerate(pattern):
self.shift_dict[value] = self.length - index
def match(self, text:str):
i = 0
text_length = len(text)
text += '\0'
while i <= text_length - self.length:
j = 0
while self.pattern[j] == text[i + j]:
j += 1
if j >= self.length:
return i
offset = self.shift_dict[text[i+self.length]] if text[i+self.length] in self.shift_dict else self.length + 1
i += offset
return -1
s = Sunday('nihao')
print(s.match('dasoijfoasjdoifjasdoifjoinihao'))
代码十分的简单,同时,我构造了一个类,是为了在同一个模式串下能够复用它的位置字典,简化代码。
Sunday算法与KMP算法大比拼
在写完代码之后,我对KMP算法和Sunday算法的匹配时间进行了一个粗略的检测,检测结果如下:
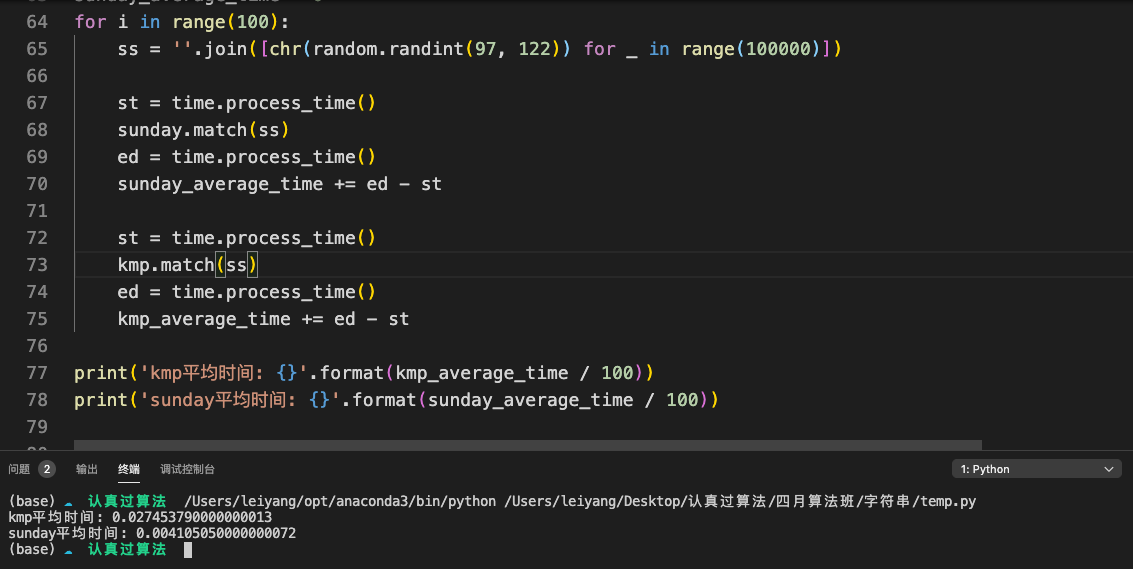
amazing!,Sunday算法的平均匹配速度达到了KMP算法的七倍左右!
对KMP和Sunday各自构造了一个对象,然后每次生成一个随机的十万个字符长度的字符串让它们俩分别开始匹配。
生成-->匹配这个过程循环一百遍,最终计算平均时间。如果有大佬觉得不放心的,我在下方放出检测代码,大家可以自行修改测试,拿去即可用!
检测代码如下
class KMP():
def __init__(self, ss: str) -> list:
self.length = len(ss)
self.next_lst = [0 for _ in range(self.length)]
self.next_lst[0] = -1
i = 0
j = -1
while i < self.length - 1:
if j == -1 or ss[i] == ss[j]:
i += 1
j += 1
if ss[i] == ss[j]:
self.next_lst[i] = self.next_lst[j]
else:
self.next_lst[i] = j
else:
j = self.next_lst[j]
self.pattern = ss
def match(self, ss:str):
ans_lst = []
j = 0
for i in range(len(ss)):
if ss[i] != self.pattern[j]:
j = self.next_lst[j] if self.next_lst[j] != -1 else 0
if ss[i] == self.pattern[j]:
j += 1
if j == self.length:
return i + 1 - self.length
return -1
class Sunday(object):
def __init__(self, pattern:str):
# 模式串和其长度
self.pattern, self.length = pattern, len(pattern)
# 根据模式串构建的偏移字典
self.shift_dict = {}
# 构建字典
for index, value in enumerate(pattern):
self.shift_dict[value] = self.length - index
def match(self, text:str):
i = 0
text_length = len(text)
text += '\0'
while i <= text_length - self.length:
j = 0
while self.pattern[j] == text[i + j]:
j += 1
if j >= self.length:
return i
offset = self.shift_dict[text[i+self.length]] if text[i+self.length] in self.shift_dict else self.length + 1
i += offset
return -1
import random
import time
sunday = Sunday('helloworld')
kmp = KMP('helloworld')
kmp_average_time = 0
sunday_average_time = 0
for i in range(100):
ss = ''.join([chr(random.randint(97, 122)) for _ in range(100000)])
st = time.process_time()
sunday.match(ss)
ed = time.process_time()
sunday_average_time += ed - st
st = time.process_time()
kmp.match(ss)
ed = time.process_time()
kmp_average_time += ed - st
print('kmp平均时间: {}'.format(kmp_average_time / 100))
print('sunday平均时间: {}'.format(sunday_average_time / 100))
最后
最后,如果你觉得这篇文章对你有帮助的话呢,给我点个关注,收藏吧!
我的个人公众号是【程序小员】,欢迎你的关注,你的认可是我最大的动力!
我会持续更新对你有帮助的文章!
我是落阳,谢谢你的到访!
动画演示Sunday字符串匹配算法——比KMP算法快七倍!极易理解!的更多相关文章
- 字符串匹配算法之 kmp算法 (python版)
字符串匹配算法之 kmp算法 (python版) 1.什么是KMP算法 KMP是三位大牛:D.E.Knuth.J.H.MorriT和V.R.Pratt同时发现的.其中第一位就是<计算机程序设计艺 ...
- Python 细聊从暴力(BF)字符串匹配算法到 KMP 算法之间的精妙变化
1. 字符串匹配算法 所谓字符串匹配算法,简单地说就是在一个目标字符串中查找是否存在另一个模式字符串.如在字符串 "ABCDEFG" 中查找是否存在 "EF" ...
- 字符串匹配算法之————KMP算法
上一篇中讲到暴力法字符串匹配算法,但是暴力法明显存在这样一个问题:一次只移动一个字符.但实际上,针对不同的匹配情况,每次移动的间隔可以更大,没有必要每次只是移动一位: 关于KMP算法的描述,推荐一篇博 ...
- 字符串匹配算法之kmp算法
kmp算法是一种效率非常高的字符串匹配算法,是由Knuth,Morris,Pratt共同提出的模式匹配算法,所以简称KMP算法 算法思想 在一个字符串中查找另一个字符串时,会遇到如下图的情况 我们通常 ...
- 字符串匹配算法(三)-KMP算法
今天我们来聊一下字符串匹配算法里最著名的算法-KMP算法,KMP算法的全称是 Knuth Morris Pratt 算法,是根据三位作者(D.E.Knuth,J.H.Morris 和 V.R.Prat ...
- 数据结构学习之字符串匹配算法(BF||KMP)
数据结构学习之字符串匹配算法(BF||KMP) 0x1 实验目的 通过实验深入了解字符串常用的匹配算法(BF暴力匹配.KMP.优化KMP算法)思想. 0x2 实验要求 编写出BF暴力匹配.KM ...
- 字符串匹配算法之BM算法
BM算法,全称是Boyer-Moore算法,1977年,德克萨斯大学的Robert S. Boyer教授和J Strother Moore教授发明了一种新的字符串匹配算法. BM算法定义了两个规则: ...
- 数据结构4_java---顺序串,字符串匹配算法(BF算法,KMP算法)
1.顺序串 实现的操作有: 构造串 判断空串 返回串的长度 返回位序号为i的字符 将串的长度扩充为newCapacity 返回从begin到end-1的子串 在第i个字符之前插入字串str 删除子串 ...
- Sunday字符串匹配算法
逛ACM神犇的博客的时候看到的这个神奇的算法 KMP吧,失配函数难理解,代码量长 BF吧,慢,很慢,特别慢. BM吧,我不会写... 现在看到了Sunday算法呀,眼前一亮,神清气爽啊. 字符串匹配算 ...
随机推荐
- python之os模块使用
python中os模块的常用语法 1.查看当前路径及路径下的目录 os.getcwd():返回当前路径(不包括文件名) os.listdir():返回当前路径下的所有目录列表. os.listdir( ...
- vue3 报错解决:找不到模块‘xxx.vue’或其相应的类型声明。(Vue 3 can not find module)
最近在用 vue3 写一个小组件库,在 ts 文件中引入 .vue 文件时出现以下报错: 报错原因:typescript 只能理解 .ts 文件,无法理解 .vue文件 解决方法:在项目根目录或 sr ...
- JavaScript 伪Ajax请求
伪Ajax 通过iframe以及form表单,可以实现伪Ajax的方式. 并且它的兼容性是最好的. iframe iframe标签能够获取一个其他页面的文档内容,这说明它内部肯定是发送了一个请求,并且 ...
- [Leetcode]225. 用队列实现栈 、剑指 Offer 09. 用两个栈实现队列
##225. 用队列实现栈 如题 ###题解 在push时候搞点事情:push时入队1,在把队2的元素一个个入队1,再交换队2和队1,保持队1除pushguocheng 始终为空. ###代码 cla ...
- 手把手教你配置git和git仓库
今天是git专题的第二篇,我们来介绍一下git的基本配置,以及建立一个git仓库的基本方法. 首先申明一点,本文不会介绍git的安装.一方面是大部分个人PC的系统当中都是已经装好了git的,另外一方面 ...
- Docker应用安装
一.安装mysql 1.查看可用的 MySQL 版本 访问 MySQL 镜像库地址:https://hub.docker.com/_/mysql?tab=tags . 可以通过 Sort by 查看其 ...
- 1.5Hadoop的启动
- 容器云平台No.5~企业级私有镜像仓库Harbor V2.02
镜像仓库 仓库,顾名思义,就是存放东西的地方,Docker仓库,理所当然,就是存放docker镜像的地方了. Docker仓库分公有仓库和私有仓库.共有仓库有hub.docker.com.gcr.io ...
- Redis学习(一)认识并安装redis
一.初识redis Redis是一个开源的Key-Value数据库,通常被称为数据结构服务器,其值可以是多种常见的数据格式,且读写性能极高,且所有操作都是原子性的. Redis是运行在内存中的,但是可 ...
- JSTL1.1函数标签库(functions)
JSTL1.1函数标签库(functions) 在jstl中的fn标签也是我们在网页设计中经常要用到的很关键的标签,在使用的时候要先加上头 <%@ taglib uri="http:/ ...