ElasticSearch-生命周期管理
1月29日,Elastic Stack 迎来 6.6 版本的发布,该版本带来很多新功能,比如:
- Index Lifecycle Management
- Frozen Index
- Geoshape based on Bkd Tree
- SQL adds support for Date histograms
- ......
在这些众多功能中,Index Lifecycle Management(索引生命周期管理,后文简称 ILM) 是最受社区欢迎的。今天我们从以下几方面来快速了解下该功能:
- 为什么索引会有生命?什么是索引生命周期?
- ILM 是如何划分索引生命周期的?
- ILM 是如何管理索引生命周期的?
- 实战
Index Lifecycle 索引生命周期
先来看第一个问题:
为什么索引有生命?
索引(Index)是 Elasticsearch 中数据组织的一个逻辑概念,是具有相同或相似字段的文档组合。它由众多分片(Shard)组成,比如book、people都可以用作索引名称,可以简单类比为关系型数据库的表(table)。
所谓生命,即生与死;索引的生与死便是创建与删除了。
在我们日常使用 Elasticsearch 的时候,索引的创建与删除似乎是很简单的事情,用的时候便创建,不用了删除即可,有什么好管理的呢?
这就要从 Elasticsearch 的应用场景来看了。
在业务搜索场景,用户会将业务数据存储在 Elasticsearch 中,比如商品数据、订单数据、用户数据等,实现快速的全文检索功能。像这类数据基本都是累加的,不会删除。一般删除的话,要么是业务升级,要么是业务歇菜了。此种场景下,基本只有生,没有死,也就不存在管理一说。
而在日志业务场景中,用户会将各种日志,如系统、防火墙、中间件、数据库、web 服务器、应用日志等全部实时地存入 Elasticsearch 中,进行即时日志查询与分析。这种类型的数据都会有时间维度,也就是时序性的数据。由于日志的数据量过大,用户一般不会存储全量的数据,一般会在 Elasticsearch 中存储热数据,比如最近7天、30天的数据等,而在7天或者30天之前的数据都会被删除。为了便于操作,用户一般会按照日期来建立索引,比如 nginx 的日志索引名可能为 nginx_log-2018.11.12、nginx_log-2018.11.13等,当要查询或删除某一天的日志时,只需要针对对应日期的索引做操作就可以了。那么在该场景下,每天都会上演大量索引的生与死。
一个索引由生到死的过程,即为一个生命周期。举例如下:
生:在 2019年2月5日 创建 nginx_log-2019.02.05的索引,开始处理日志数据的读写请求
生:在 2019年2月6日 nginx_log-2019.02.05 索引便不再处理写请求,只处理读请求
死:在 2019年3月5日 删除 nginx_log-2018.02.05的索引
其他的索引,如 nginx_log-2019.02.06 等也会经过相同的一个生命周期。
ILM 是如何划分索引生命周期的?
我们现在已经了解何为生命周期了,而最简单的生命周期只需要生与死两个阶段即可。但在实际使用中生命周期是有多个阶段的,我们来看下 ILM 是如何划分生命周期的。
ILM 一共将索引生命周期分为四个阶段(Phase):
- Hot 阶段
- Warm 阶段
- Cold 阶段
- Delete 阶段
如果我们拿一个人的生命周期来做类比的话,大概如下图所示:
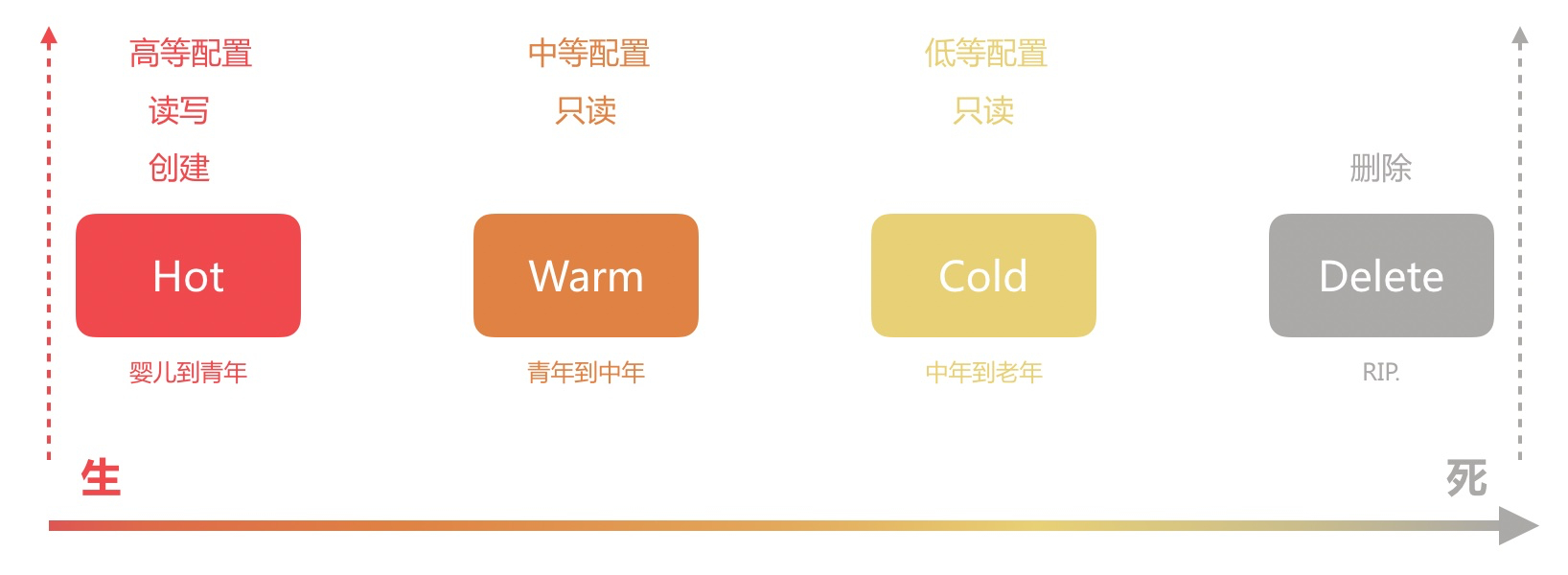
Hot 阶段
索引数据正在活跃的更新和查询
Hot 阶段可类比为人类婴儿到青年的阶段,在这个阶段,它会不断地进行知识的输入与输出(数据读写),不断地长高长大(数据量增加)成有用的青年。
由于该阶段需要进行大量的数据读写,因此需要高配置的节点,一般建议将节点内存与磁盘比控制在 32 左右,比如 64GB 内存搭配 2TB 的 SSD 硬盘。
Warm 阶段
索引数据不再被更新,但是仍被查询
Warm 阶段可类比为人类青年到中年的阶段,在这个阶段,它基本不会再进行知识的输入(数据写入),主要进行知识输出(数据读取),为社会贡献价值。
由于该阶段主要负责数据的读取,中等配置的节点即可满足需求,可以将节点内存与磁盘比提高到 64~96 之间,比如 64GB 内存搭配 4~6TB 的 HDD 磁盘。
Cold 阶段
索引已经不被更新且很少查询。但是索引数据的信息还需要被搜索,若被搜索则比较慢
Cold 阶段可类别比为人类中年到老年的阶段,在这个阶段,它退休了,在社会有需要的时候才出来输出下知识(数据读取),大部分情况都是静静地待着。
由于该阶段只负责少量的数据读取工作,低等配置的节点即可满足要求,可以将节点内存与磁盘比进一步提高到 96 以上,比如128,即 64GB 内存搭配 8 TB 的 HDD 磁盘。
Delete 阶段
索引不再被需要可以安全的删除
Delete 阶段可类比为人类寿终正寝的阶段,在发光发热之后,静静地逝去,Rest in Peace~
ILM 对于索引的生命周期进行了非常详细的划分,但它并不强制要求必须有这个4个阶段,用户可以根据自己的需求组合成自己的生命周期。
ILM 是如何管理索引生命周期的?
所谓生命周期的管理就是控制 4 个生命阶段转换,何时由 Hot 转为 Warm,何时由 Warm 转为 Cold,何时 Delete 等。
阶段的转换必然是需要时机的,而对于时序数据来说,时间必然是最好的维度,而 ILM 也是以时间为转换的衡量单位。比如下面这张转换的示意图,即默认是 Hot 阶段,在索引创建 3 天后转为 Warm 阶段,7 天后转为 Cold 阶段,30 天后删除。这个设置的相关字段为 min_age,后文会详细讲解。
ILM 将不同的生命周期管理策略称为 Policy,而所谓的 Policy 是由不同阶段(Phase)的不同动作(Action)组成的。
Action是一系列操作索引的动作,比如 Rollover、Shrink、Force Merge等,不同阶段可用的 Action 不同,详情如下:
- Hot Phase
- Rollover
滚动索引操作,可用在索引大小或者文档数达到某设定值时,创建新的索引用于数据读写,从而控制单个索引的大小。这里要注意的一点是,如果启用了 Rollover,那么所有阶段的时间不再以索引创建时间为准,而是以该索引 Rollover 的时间为准。
- Rollover
- Warm Phase
- Allocate 设定副本数、修改分片分配规则(如将分片迁移到中等配置的节点上)等
- Read-Onlly 设定当前索引为只读状态
- Force Merge 合并 segment 操作
- Shrink 缩小 shard 分片数
- Cold Phase
- Allocate 同上
- Delete Phase
- Delete 删除
从上面看下来整体操作还是很简单的,Kibana 也提供了一套 UI 界面来设置这些策略,如下所示:
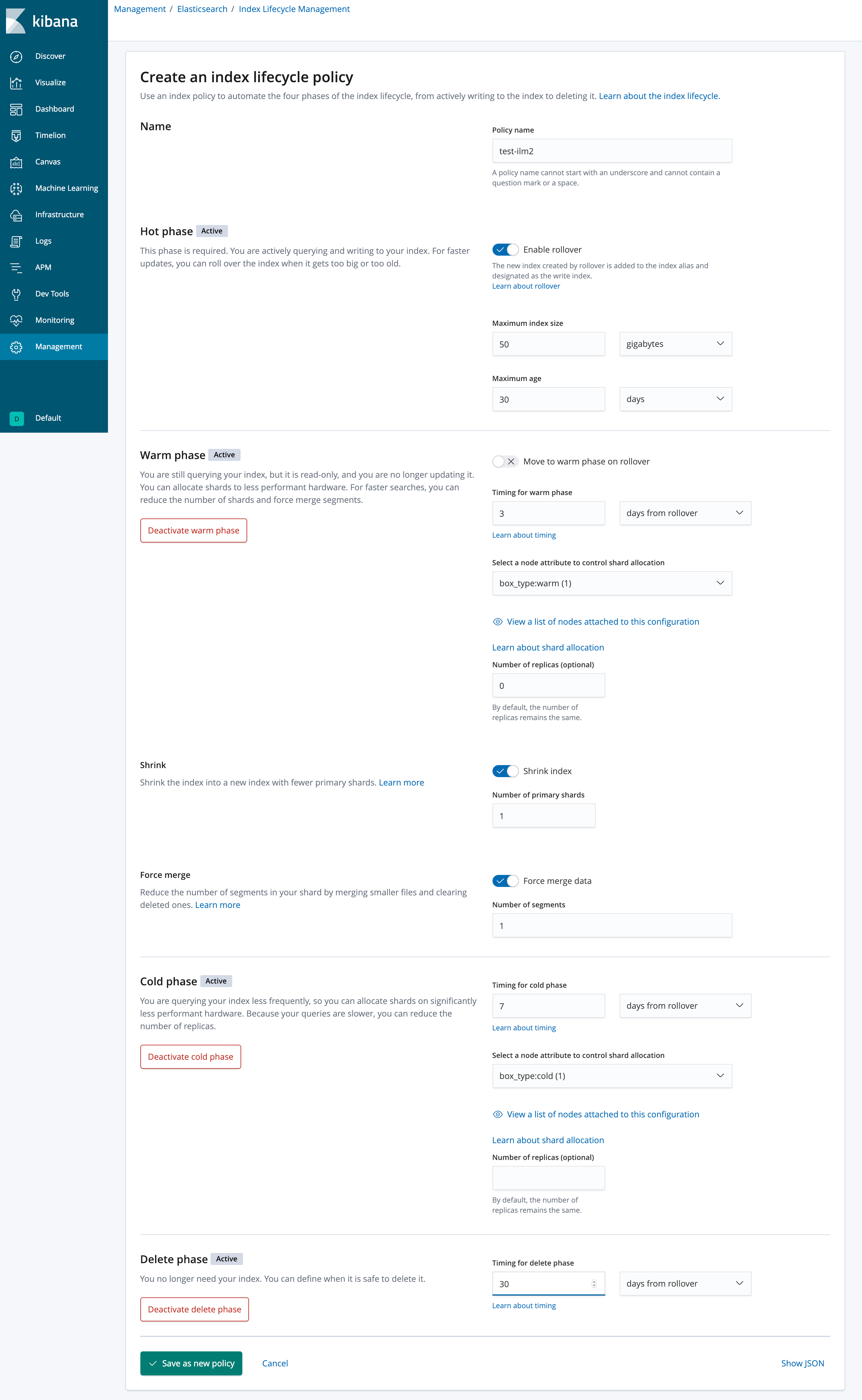
从上图看下来 ILM 的设置是不是一目了然呢?
- Delete 删除
当然,ILM 是有自己的 api 的,比如上面图片对应的 api 请求如下:
PUT /_ilm/policy/test_ilm2
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_age": "30d",
"max_size": "50gb"
}
}
},
"warm": {
"min_age": "3d",
"actions": {
"allocate": {
"require": {
"box_type": "warm"
},
"number_of_replicas": 0
},
"forcemerge": {
"max_num_segments": 1
},
"shrink": {
"number_of_shards": 1
}
}
},
"cold": {
"min_age": "7d",
"actions": {
"allocate": {
"require": {
"box_type": "cold"
}
}
}
},
"delete": {
"min_age": "30d",
"actions": {
"delete": {}
}
}
}
}
}
这里不展开讲了,感兴趣的同学可以自行查看官方手册。
现在管理策略(Policy)已经有了,那么如何应用到索引(Index)上面呢?
方法为设定如下的索引配置:
index.lifecycle.name 设定 Policy 名称,比如上面的 test_ilm2
index.lifecycle.rollover_alias 如果使用了 Rollover,那么还需要指定该别名
修改索引配置可以直接修改(PUT index_name/_settings)或者通过索引模板(Index Template)来实现。
我们这里不展开讲了,大家参考下面的实战就明白了。
实战
目标
现在需要收集 nginx 日志,只需保留最近30天的日志,但要保证最近7天的日志有良好的查询性能,搜索响应时间在 100ms 以内。
为了让大家可以快速看到效果,下面实际操作的时候会将 30天、7天 替换为 40秒、20秒。
ES 集群架构
这里我们简单介绍下这次实战所用 ES 集群的构成。该 ES 集群一共有 3个节点组成,每个节点都有名为 box_type 的属性,如下所示:
GET _cat/nodeattrs?s=attr
es01_hot 172.24.0.5 172.24.0.5 box_type hot
es02_warm 172.24.0.4 172.24.0.4 box_type warm
es03_cold 172.24.0.3 172.24.0.3 box_type cold
由上可见我们有 1 个 hot 节点、1 个 warm 节点、1 个 cold 节点,分别用于对应 ILM 的阶段,即 Hot 阶段的索引都位于 hot 上,Warm 阶段的索引都位于 warm 上,Cold 阶段的索引都位于 cold 上。
创建 ILM Policy
根据要求,我们的 Policy 设定如下:
- 索引名以 nginx_logs 为前缀,且以每10个文档做一次 Rollover
- Rollover 后 5 秒转为 Warm 阶段
- Rollover 后 20 秒转为 Cold 阶段
- Rollover 后 40 秒删除
API 请求如下:
PUT /_ilm/policy/nginx_ilm_policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_docs": "10"
}
}
},
"warm": {
"min_age": "5s",
"actions": {
"allocate": {
"include": {
"box_type": "warm"
}
}
}
},
"cold": {
"min_age": "20s",
"actions": {
"allocate": {
"include": {
"box_type": "cold"
}
}
}
},
"delete": {
"min_age": "40s",
"actions": {
"delete": {}
}
}
}
}
}
创建 Index Template
我们基于索引模板来创建所需的索引,如下所示:
PUT /_template/nginx_ilm_template
{
"index_patterns": ["nginx_logs-*"],
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"index.lifecycle.name": "nginx_ilm_policy",
"index.lifecycle.rollover_alias": "nginx_logs",
"index.routing.allocation.include.box_type": "hot"
}
}
上述配置解释如下:
- index.lifecycle.name 指明该索引应用的 ILM Policy
- index.lifecycle.rollover_alias 指明在 Rollover 的时候使用的 alias
- index.routing.allocation.include.box_type 指明新建的索引都分配在 hot 节点上
创建初始索引 Index
ILM 的第一个索引需要我们手动来创建,另外启动 Rollover 必须以数值类型结尾,比如 nginx_logs-000001。索引创建的 api 如下:
PUT nginx_logs-000001
{
"aliases": {
"nginx_logs": {
"is_write_index":true
}
}
}
此时索引分布如下所示:
修改 ILM Polling Interval
ILM Service 会在后台轮询执行 Policy,默认间隔时间为 10 分钟,为了更快地看到效果,我们将其修改为 1 秒。
PUT _cluster/settings
{
"persistent": {
"indices.lifecycle.poll_interval":"1s"
}
}
开始吧
一切准备就绪,我们开始吧!
首先执行下面的新建文档操作 10 次。
POST nginx_logs/_doc
{
"name":"abbc"
}
之后 Rollover 执行,新的索引创建,如下所示:
5 秒后,nginx_logs-000001 转到 Warm 阶段
15 秒后(20 秒是指距离 Rollover 的时间,因为上面已经过去5秒了,所以这里只需要15秒),nginx_logs-00001转到 Cold 阶段
25 秒后,nginx_logs-00001删除
至此,一个完整的 ILM Policy 执行的流程就结束了,而后续 nginx_logs-000002 也会按照这个设定进行流转。
总结
ILM 是 Elastic 团队将多年 Elasticsearch 在日志场景领域的最佳实践进行的一次总结归纳和落地实施,极大地降低了用好 Elasticsearch 的门槛。掌握了 ILM 的核心概念,也就意味着掌握了 Elasticsearch 的最佳实践。希望本文能对大家入门 ILM 有所帮助。
结语
欢迎关注微信公众号『码仔zonE』,专注于分享Java、云计算相关内容,包括SpringBoot、SpringCloud、微服务、Docker、Kubernetes、Python等领域相关技术干货,期待与您相遇!

ElasticSearch-生命周期管理的更多相关文章
- ElasticSearch生命周期管理-索引策略配置与操作
概述 本文是在本人学习研究ElasticSearch的生命周期管理策略时,发现官方未提供中文文档,有的也是零零散散,此文主要是翻译官方文档Policy phases and actions模块. 注: ...
- ElasticSearch——索引生命周期管理
从ES6.6开始,Elasticsearch提供索引生命周期管理功能,索引生命周期管理可以通过API或者kibana界面配置,详情参考[index-lifecycle-management] 本文仅通 ...
- Elasticsearch索引生命周期管理方案
一.前言 在 Elasticsearch 的日常中,有很多如存储 系统日志.行为数据等方面的应用场景,这些场景的特点是数据量非常大,并且随着时间的增长 索引 的数量也会持续增长,然而这些场景基本上只有 ...
- Elasticsearch 索引生命周期管理 ILM 实战指南
文章转载自:https://mp.weixin.qq.com/s/7VQd5sKt_PH56PFnCrUOHQ 1.什么是索引生命周期 在基于日志.指标.实时时间序列的大型系统中,集群的索引也具备类似 ...
- Elasticsearch 快照生命周期管理 (SLM) 实战指南
文章转载自:https://mp.weixin.qq.com/s/PSfgPJc4dKN2pOZd0Y02wA 1.Elasticsearch 保证高可用性的方式 Elasticsearch 保证集群 ...
- Elasticsearch:Index生命周期管理入门
如果您要处理时间序列数据,则不想将所有内容连续转储到单个索引中. 取而代之的是,您可以定期将数据滚动到新索引,以防止数据过大而又缓慢又昂贵. 随着索引的老化和查询频率的降低,您可能会将其转移到价格较低 ...
- Elasticsearch索引生命周期管理探索
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484130&idx=1&sn=454f199 ...
- Elastic 使用索引生命周期管理实现热温冷架构
Elastic: 使用索引生命周期管理实现热温冷架构 索引生命周期管理 (ILM) 是在 Elasticsearch 6.6(公测版)首次引入并在 6.7 版正式推出的一项功能.ILM 是 Elast ...
- 这么简单的ES索引生命周期管理,不了解一下吗~
对于日志或指标(metric)类时序性强的ES索引,因为数据量大,并且写入和查询大多都是近期时间内的数据.我们可以采用hot-warm-cold架构将索引数据切分成hot/warm/cold的索引.h ...
- Elasticsearch7.X ILM索引生命周期管理(冷热分离)
Elasticsearch7.X ILM索引生命周期管理(冷热分离) 一.“索引生命周期管理”概述 Elasticsearch索引生命周期管理指:Elasticsearch从设置.创建.打开.关闭.删 ...
随机推荐
- Webpack 原理浅析
作者: 凹凸曼 - 风魔小次郎 背景 Webpack 迭代到4.x版本后,其源码已经十分庞大,对各种开发场景进行了高度抽象,阅读成本也愈发昂贵.但是为了了解其内部的工作原理,让我们尝试从一个最简单的 ...
- Pandas 复习
1.导包 import pandas as pd 2.数据读取,文件在该代码文件夹内 food_info = pd.read_csv('food_info.csv') 3.查看类型 food_info ...
- HTML 统一资源定位器(Uniform Resource Locators)
HTML 统一资源定位器(Uniform Resource Locators) URL 是一个网页地址.高佣联盟 www.cgewang.com URL可以由字母组成,如"runoob.co ...
- PHP wordwrap() 函数
实例 按照指定长度对字符串进行折行处理: <?php高佣联盟 www.cgewang.com$str = "An example of a long word is: Supercal ...
- Scala---初探
scala语言量大特性:面向对象+函数式编程 Scala的类型 val指的是引用不可变,而不是值. 值类型 Byte Char Short Int Long Float Double 引用类型 Str ...
- Pandas 数据处理 | Datetime 在 Pandas 中的一些用法!
Datatime 是 Python 中一种时间数据类型,对于不同时间格式之间的转换是比较方便的,而在 Pandas 中也同样支持 DataTime 数据机制,可以借助它实现许多有用的功能,例如 1,函 ...
- 【PA2014】Bohater 题解(贪心)
前言:一道经典贪心题. -------------------------- 题目链接 题目大意:你有$z$滴血,要打$n$只怪.打第$i$只怪扣$d_i$滴血,回$a_i$滴血.问是否存在一种能够通 ...
- 虚拟机安装Centos(VirtulBox)
阿里云服务器本月底到期了,之前自己犹豫不觉没上279元3年服务器的车,但是又要用linux,所以有了这篇文章. VirtulBox 一款开源的虚拟化主机应用,可以实现一台电脑上运行多个操作系统(Lin ...
- iOS开发多线程在实际项目中的运用
实际项目开发中为了能够给用户更好的体验,有些延时操作我们都会放在子线程中进行. 今天我们就来聊聊多线程在实际项目中的运用. 我们先来看看多线程的基础知识: 1.多线程的原理: 同一时间,CPU只能处理 ...
- 移动物体监控系统-sprint4嵌入式web服务器开发
一.BOA嵌入式服务器的移植 step1:下载BOA服务器并解压,进入boa下面的src目录,执行./configure生成必须的配置文件以及Makefile step2:修改Makefile文件 c ...