字段解析之OopMapBlock(4)
OopMapBlock是一个简单的内嵌在Klass里面的数据结构,用来描述oop中包含的引用类型属性,即该oop所引用的其他oop在oop中的内存分布,然后就可以根据当前oop的地址找到所有引用的其他oop了,其定义如下:
源代码位置:oops/instanceKlass.hpp // ValueObjs embedded in klass. Describes where oops are located in instances of
// this klass.
class OopMapBlock VALUE_OBJ_CLASS_SPEC {
public:
// Byte offset of the first oop mapped by this block.
int offset() const { return _offset; }
void set_offset(int offset) { _offset = offset; } // Number of oops in this block.
uint count() const { return _count; }
void set_count(uint count) { _count = count; } // sizeof(OopMapBlock) in HeapWords.
static const int size_in_words() {
return align_size_up(int(sizeof(OopMapBlock)), HeapWordSize) >>
LogHeapWordSize;
} private:
int _offset;
uint _count;
};
OopMapBlock结构可以描述某个对象中引用区域的起始偏移和引用个数。offset描述第一个所引用的oop相对于当前oop地址的偏移量,count表示包含的oop的个数,注意这里的包含并不是指这些oop位于OopMapBlock里面,而是有count个连续存放的oop。为啥会有多个OopMapBlock了?因为每个OopMapBlock只能描述当前子类中包含的引用类型属性,父类的引用类型属性由单独的OopMapBlock描述。
之前介绍过,可以利用-XX:+PrintFieldLayout来查看布局情况。该选项只在调试版本中有效。至于布局模式,可以使用-XX:+FieldsAllocationStyle=mode来指定,默认是1。之前介绍过布局模式有3种,如下:
- allocation_style=0,字段排列顺序为oops、longs/doubles、ints、shorts/chars、bytes,最后是填充字段,以满足对齐要求;
- allocation_style=1,字段排列顺序为longs/doubles、ints、shorts/chars、bytes、oops,最后是填充字段,以满足对齐要求;
- allocation_style=2,JVM在布局时会尽量使父类oops和子类oops挨在一起。
当allocation_style的值为2时,父子oop的布局会连续在一起,这样至少有2个好处:
- 减少OopMapBlock的数量。由于GC收集时要扫描存活的对象,所以必须知道对象中引用的内存位置。原始类型不需要扫描。
- 连续的对象区域使得缓存行的使用效率更高。试想如果父对象和子对象的对象引用区域不连续,而中间插入了原始类型字段的话,那么在做GC对象扫描时,很可能需要跨缓存行读取才能完成扫描。
下面我们用HSDB来实际探查下相关的内存布局:
package jvmTest; import java.lang.management.ManagementFactory;
import java.lang.management.RuntimeMXBean; class Base{
private int a=1; private String s="abc"; private Integer a2=12; private int a3=22;
} class A extends Base {
private int b=3; private String s2="def"; private int b2=33; private Base a=new Base();
} class B extends A{
private String s3="ghk"; private Integer c=4; private int c2=44;
} public class jvmTest { public static void main(String[] args) {
Base a=new Base();
A a2=new A();
B b=new B();
while (true){
try {
System.out.println(getProcessID());
Thread.sleep(600*1000);
} catch (Exception e) { }
}
} public static final int getProcessID() {
RuntimeMXBean runtimeMXBean = ManagementFactory.getRuntimeMXBean();
System.out.println(runtimeMXBean.getName());
return Integer.valueOf(runtimeMXBean.getName().split("@")[0]).intValue();
}
}
运行main方法后,用HSDB查看main线程的线程栈,从中找出变量a,a2,b对应的oop的地址,如下:

分别查看0x00000000d69d98a0,0x00000000d69db5f8,0x00000000d69dd070对应的oop,如下:

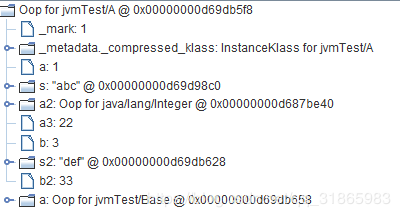

上从面的截图可知,子类会完整的保留父类的属性,从而方便调用父类方法时能够正确的使用父类的属性。上述对oop的属性打印是按照类声明属性的顺序来的,内存中是这样保存的么?可以通过查看属性的偏移量来判断。
在Class Browser中搜索jvmTest,可以查找到我们三个自定义类对应的Klass,如下图:
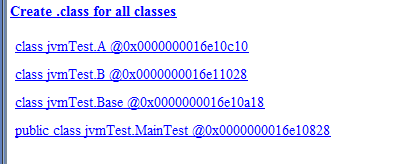
分别点击这三个类查看属性的偏移量,如下:



根据上述偏移量,我们可以得出jvmTest.B对象的内存布局,如下:

int本身占4个字节,引用类型属性本质上就是一个指针,这里因为默认开启了指针压缩,所以也是4字节。
我们再看下表示OopMapBlock在Klass中的字宽数的属性_nonstatic_oop_map_size在三个类中的取值,如下:
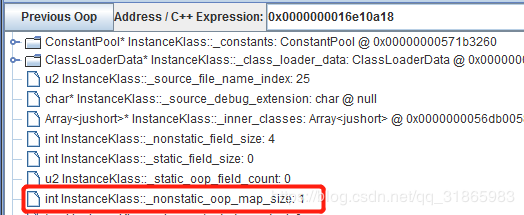
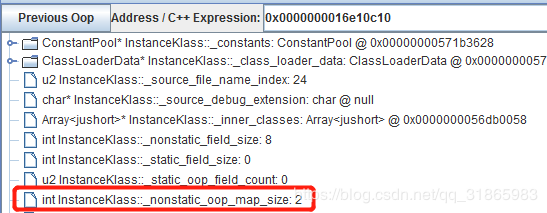
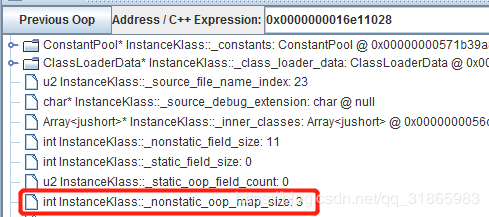
OopMapBlock本身就只有两个int属性,所以一个OopMapBlock实例只有8字节,即一个字宽,jvmTest.B的_nonstatic_oop_map_size属性值为3,即由3个OopMapBlock,下面通过CHSDB的mem命令来看看这3个OopMapBlock对应的内存数据。
首先执行inspect对象得到该Klass本身的大小,即sizeof的大小,如下:

vtable,itable,OopMapBlock这三个都是内嵌在Klass里面的,所谓的内嵌实际是指这块内存是紧挨着Klass自身的属性对应的内存的下面,从上一节的分析可知,OopMapBlock在itable的后面,itable在vtable的后面,而vtable是紧挨着Klass的,从上述inspect命令的输出,也可知道itable和vtable的内存大小,单位是字宽,如下:

因此OopMapBlock的起始地址就是Klass的地址加上Klass本身的大小440字节即55字宽,再加上vtable的5字宽,itable的2字宽,总共加62字宽,OopMapBlock本身占用3个字宽,因此用mem查看这65字宽的数据,如下:

最后的3个字宽如下:

每个字宽对应一个OopMapBlock,前面4字节就是count属性,这里都是2,后面4字节就是offset,分别是20,36,48,与jvmTest.B的内存结构是完全一致的。
相关文章的链接如下:
1、在Ubuntu 16.04上编译OpenJDK8的源代码
13、类加载器
14、类的双亲委派机制
15、核心类的预装载
16、Java主类的装载
17、触发类的装载
18、类文件介绍
19、文件流
20、解析Class文件
21、常量池解析(1)
22、常量池解析(2)
23、字段解析(1)
24、字段解析之伪共享(2)
25、字段解析(3)
作者持续维护的个人博客classloading.com。
关注公众号,有HotSpot源码剖析系列文章!

参考文章:
(1)https://zhuanlan.zhihu.com/p/28226360
(2)https://blog.csdn.net/lqp276/article/details/52190503
(3)https://blog.csdn.net/qq_31865983/article/details/104284546#t3
(6)https://blog.csdn.net/qq_31865983/article/details/104284546#4%E3%80%81OopMapBlock
字段解析之OopMapBlock(4)的更多相关文章
- 简单sql字段解析器实现参考
用例:有一段sql语句,我们需要从中截取出所有字段部分,以便进行后续的类型推断,请给出此解析方法. 想来很简单吧,因为 sql 中的字段列表,使用方式有限,比如 a as b, a, a b... 1 ...
- iis日志字段解析
IIS日志字段 #Software: Microsoft Internet Information Services 7.5 #Version: 1.0 #Date: 2013-08-21 01:00 ...
- C++11 STL Regex正则表达式与字符串字段解析
简单的日期正则表达式 一个简单的日期解析程序,从yyyy-mm-dd格式的日期字符串中,分别获取年月日. 先设置一个简单的正则表达式,4位数字的"年",1-2位数字的"月 ...
- Linux iostat字段解析
iostat主要用于监控系统设备的IO负载情况,iostat首次运行时显示自系统启动开始的各项统计信息,之后运行iostat将显示自上次运行该命令以后的统计信息.用户可以通过指定统计的次数和时间来获得 ...
- Linux mpstat字段解析
mpstat是Multiprocessor Statistics的缩写,是实时系统监控工具.其报告与CPU的一些统计信息,这些信息存放在/proc/stat文件中.在多CPUs系统里,其不但能查看所有 ...
- Linux free字段解析
下面是free的运行结果,一共有4行.为了方便说明,我加上了列号.这样可以把free的输出看成一个二维数组FO(Free Output).例如: FO[2][1] = 24677460 FO[3][2 ...
- python scapy dns 包字段解析
qr: 0表示查询报文,1表示响应报文opcode: 通常值为0(标准查询),其他值为1(反向查询)和2(服务器状态请求).aa: 表示授权回答(authoritative answer)tc: ...
- python orm字段解析
null # 是否可以为空 default # 默认值 primary_key # 主键 db_column # 列名 db_index # 索引(db_index=True) unique # 唯一 ...
- 【转】odoo学习之:开发字段解析
odoo新API中,字段类型不变,继承改变 1.旧的API定义模型: from openerp.osv import osv,fields class oldmodel(osv.osv): #模型名称 ...
随机推荐
- DirectX11 With Windows SDK--33 曲面细分阶段(Tessellation)
前言 曲面细分是Direct3D 11带来的其中一项重要的新功能.它引入了两个可编程着色器阶段以及一个固定的镶嵌处理过程.简单来说,曲面细分技术可以将几何体细分为更小的三角形,并以某种方式把这些新生成 ...
- 安装完Linux需要做的关于安全的事
故事是这样子的 最近主机受到攻击,原因可能是redis集群没有设置密码(因为快过期了,不想搞得太复杂就没设),然后被人家搞事情了,就被人一把set了些执行脚本,形如curl -fsSL http:// ...
- OSCP Learning Notes - Enumeration(1)
Installing Kioptrix: Level 1 Download the vm machine form https://www.vulnhub.com/entry/kioptrix-lev ...
- 深度学习趣谈:什么是迁移学习?(附带Tensorflow代码实现)
一.迁移学习的概念 什么是迁移学习呢?迁移学习可以由下面的这张图来表示: 这张图最左边表示了迁移学习也就是把已经训练好的模型和权重直接纳入到新的数据集当中进行训练,但是我们只改变之前模型的分类器(全连 ...
- 手把手教你安装Office 2019 for Mac ,安装包和破解码都给你准备好了,还装不上的话,你找我!
准备一个安装包,和一个破解工具 安装MicrosoftOffice16.23.19030902_Installer.pkg, 注意在断网情况下安装 同时不要自动更新 , 安装好之后不要打开文件! ...
- 如何看待HTTP/3
前言 HTTP/2 相比于 HTTP/1.1,可以说是大幅度提高了网页的性能,只需要升级到该协议就可以减少很多之前需要做的性能优化工作,当然兼容问题以及如何优雅降级应该是国内还不普遍使用的原因之一. ...
- Python基础学习之环境搭建
Python如今成为零基础编程爱好者的首选学习语言,这和Python语言自身的强大功能和简单易学是分不开的.今天我们将带领Python零基础的初学者完成入门的第一步——环境搭建.本文会先来区分几个在P ...
- Spring bean初始化
- 【题解】cf1381c Mastermind
序 (一道很考验思维质量的构造好题,而且需要注意的细节也很多.) 本题解主体使用的是简洁且小常数的\(O(nlogn)\)时间复杂度代码,并且包含其他方法的分析留给读者自行实现(其实是自己不会写或者写 ...
- 放弃dagger?Anrdoi依赖注入框架koin
Koin 是什么 Koin 是为 Kotlin 开发者提供的一个实用型轻量级依赖注入框架,采用纯 Kotlin 语言编写而成,仅使用功能解析,无代理.无代码生成.无反射. 官网地址 优势 依赖注入好处 ...