Docker Elasticsearch 集群配置
一:选用ES原因
公司项目有些mysql的表数据已经超过5百万了,各种业务的查询入库压力已经凸显出来,初步打算将一个月前的数据迁移到ES中,mysql的老数据就物理删除掉。
首先是ES使用起来比较方便,对于项目初期存储一些不能删除但又一般使用不到的数据比较合适,
还有就是ES的存储采用索引分片式,使用数据的创建时间分片也很合适。
本文使用的ES版本:5.6.8,docker版本:18.06.3-ce。
本文的测试机器为两台百度云的2C4G的机器,每个机器分别部署三个节点(1个master,2个data),总共6个节点,次配置仅为研究测试用,具体生产业务要看情况考虑。
二:Docker的安装:
参考我之前的安装文档:《Docker-常用基建的安装与部署》。
三:ES配置
1:创建es相关目录
cd /home/data/docker
mkdir -p es/cluster/es-0/conf
mkdir -p es/cluster/es-1/conf
mkdir -p es/cluster/es-2/conf
cd es/cluster/es-0/conf
touch elasticsearch.yml
# 一个机器 三个节点,复制两份
cd /home/data/docker
cp es/cluster/es-0/conf/elasticsearch.yml es/cluster/es-1/conf
cp es/cluster/es-0/conf/elasticsearch.yml es/cluster/es-2/conf
2:编辑 服务器A的 elasticsearch.yml
#跨域支持
http.cors.enabled: true
http.cors.allow-origin: "*"
#集群名称(所有节点的集群名称必须一致)
cluster.name: es-nova
#节点名称(集群下每个节点都不相同)
node.name: node-0
#ifconfig查看当前系统的内网ip
network.host: 172.16.0.4
#对外服务的http端口,默认为9200
http.port: 9201
#设置可以访问的ip,默认为0.0.0.0,这里全部设置通过
network.bind_host: 0.0.0.0
#设置结点之间交互的ip地址
network.publish_host: 当前服务器的外网ip
#culster transport port
#节点之间交互的tcp端口
transport.tcp.port: 9301
transport.tcp.compress: true
#至少存在一个主资格节点时才进行主节点选举,防止脑裂
discovery.zen.minimum_master_nodes: 1
#是否有master选举资格:一个集群同时只有一个master存在,true代表有资格参与master选举
node.master: true
#是否作为数据节点:参与数据存储与查询
node.data: false
#等待集群至少存在多少节点数才进行数据恢复
gateway.recover_after_nodes: 3
#等待 5 分钟,或者3 个节点上线后,才进行数据恢复,这取决于哪个条件先达到
gateway.expected_nodes: 3
gateway.recover_after_time: 5m
#集群单播发现
discovery.zen.ping.unicast.hosts: ["外网ip:9301","另一台服务器外网ip:9301"]
# 连接集群超时时间
discovery.zen.ping_timeout: 120s
# discovery.zen.fd合理的设置可以避免正常机器重启造成的数据迁移
# 单次心跳检测ping超时时间
discovery.zen.fd.ping_timeout: 60s
# 多少次心跳检测失败才认为节点丢失
discovery.zen.fd.ping_retries: 3
# 集群机器间机器定时心跳检测时间
discovery.zen.fd.ping_interval: 30s
# 为保证ES性能,请同时关闭系统内存交换 swapp
#bootstrap.memory_lock: true
上面这个当前一个非数据节点的master节点的配置,然后再基于当前的配置,简单修改下,分别在es-1/conf 和 es-2/conf 下创建两个数据节点,
只需要修改以下配置:
node.name: node-1
http.port: 9202
transport.tcp.port: 9302
node.master: false
node.data: true
node.name: node-2
http.port: 9203
transport.tcp.port: 9303
node.master: false
node.data: true
3:编辑 服务器B的 elasticsearch.yml
#跨域支持
http.cors.enabled: true
http.cors.allow-origin: "*"
#集群名称(所有节点的集群名称必须一致)
cluster.name: es-nova
#节点名称(集群下每个节点都不相同)
node.name: node-4
#ifconfig查看当前系统的内网ip
network.host: 172.16.0.4
#对外服务的http端口,默认为9200
http.port: 9201
#设置可以访问的ip,默认为0.0.0.0,这里全部设置通过
network.bind_host: 0.0.0.0
#设置结点之间交互的ip地址
network.publish_host: 当前服务器的外网ip
#culster transport port
#节点之间交互的tcp端口
transport.tcp.port: 9301
transport.tcp.compress: true
#至少存在一个主资格节点时才进行主节点选举,防止脑裂
discovery.zen.minimum_master_nodes: 1
#是否有master选举资格:一个集群同时只有一个master存在,true代表有资格参与master选举
node.master: true
#是否作为数据节点:参与数据存储与查询
node.data: false
#等待集群至少存在多少节点数才进行数据恢复
gateway.recover_after_nodes: 3
#等待 5 分钟,或者3 个节点上线后,才进行数据恢复,这取决于哪个条件先达到
gateway.expected_nodes: 3
gateway.recover_after_time: 5m
#集群单播发现
discovery.zen.ping.unicast.hosts: ["外网ip:9301","另一台服务器外网ip:9301"]
# 连接集群超时时间
discovery.zen.ping_timeout: 120s
# discovery.zen.fd合理的设置可以避免正常机器重启造成的数据迁移
# 单次心跳检测ping超时时间
discovery.zen.fd.ping_timeout: 60s
# 多少次心跳检测失败才认为节点丢失
discovery.zen.fd.ping_retries: 3
# 集群机器间机器定时心跳检测时间
discovery.zen.fd.ping_interval: 30s
# 为保证ES性能,请同时关闭系统内存交换 swapp
#bootstrap.memory_lock: true
和服务器A的不同配置仅仅 node.name和network.publish_host。
同样在当前服务器下也分别在es-1/conf 和 es-2/conf 下创建两个数据节点,
node.name: node-5
http.port: 9202
transport.tcp.port: 9302
node.master: false
node.data: true
node.name: node-6
http.port: 9203
transport.tcp.port: 9303
node.master: false
node.data: true
四:修改宿主机的配置
如果es集群启动报错:max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144] vim /etc/sysctl.conf
# 配置里需要添加
vm.max_map_count=262144
# 执行命令sysctl -p 生效
sysctl -p
如果es集群启动报错:memory locking requested for elasticsearch process but memory is not locked
# 修改limits.conf
vim /etc/security/limits.conf
# 添加 *表示所用用户
* soft nofile 65536
* hard nofile 65536
* soft nproc 32000
* hard nproc 32000
* hard memlock unlimited
* soft memlock unlimited
# 关闭selinux
vim /etc/sysconfig/selinux
# 将 SELINUX=enforcing 改为 SELINUX=disabled
五:集群
1:开启集群
分别启动服务器A的三个es节点、服务器B的三个es节点 (启动命令中仅docker的路径不同)
docker run -d --name es-0 -p 9201:9201 -p 9301:9301 -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" -v /home/data/docker/es/cluster/es-0/data:/usr/share/elasticsearch/data -v /home/data/docker/es/cluster/es-0/conf/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /home/data/docker/es/cluster/es-0/logs:/user/share/elasticsearch/logs --restart=always elasticsearch:5.6.8 docker run -d --name es-1 -p 9202:9202 -p 9302:9302 -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" -v /home/data/docker/es/cluster/es-1/data:/usr/share/elasticsearch/data -v /home/data/docker/es/cluster/es-1/conf/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /home/data/docker/es/cluster/es-1/logs:/user/share/elasticsearch/logs --restart=always elasticsearch:5.6.8 docker run -d --name es-2 -p 9203:9203 -p 9303:9303 -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" -v /home/data/docker/es/cluster/es-2/data:/usr/share/elasticsearch/data -v /home/data/docker/es/cluster/es-2/conf/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /home/data/docker/es/cluster/es-2/logs:/user/share/elasticsearch/logs --restart=always elasticsearch:5.6.8
docker run -d --name es-0 -p 9201:9201 -p 9301:9301 -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" -v /root/data/docker/es/cluster/es-0/data:/usr/share/elasticsearch/data -v /root/data/docker/es/cluster/es-0/conf/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /root/data/docker/es/cluster/es-0/logs:/user/share/elasticsearch/logs --restart=always elasticsearch:5.6.8 docker run -d --name es-1 -p 9202:9202 -p 9302:9302 -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" -v /root/data/docker/es/cluster/es-1/data:/usr/share/elasticsearch/data -v /root/data/docker/es/cluster/es-1/conf/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /root/data/docker/es/cluster/es-1/logs:/user/share/elasticsearch/logs --restart=always elasticsearch:5.6.8 docker run -d --name es-2 -p 9203:9203 -p 9303:9303 -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" -v /root/data/docker/es/cluster/es-2/data:/usr/share/elasticsearch/data -v /root/data/docker/es/cluster/es-2/conf/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /root/data/docker/es/cluster/es-2/logs:/user/share/elasticsearch/logs --restart=always elasticsearch:5.6.8
启动完成后,docker ps 以及docker logs es-0 去查看es是否启动成功。

2:常用的一些es命令
#集群健康
curl -XGET 127.0.0.1:9201/_cat/health?v

"status": 集群状态,重点关注项
* green正常
* yellow服务仍然可用但存在副本分片丢失,
* red 存在主分片丢失,集群不正常,存在数据丢失可能
shards :所有分片数(主分片+副本分片)
pri:主分片数
# 查询集群节点
curl -XGET 127.0.0.1:9203/_cat/nodes?v
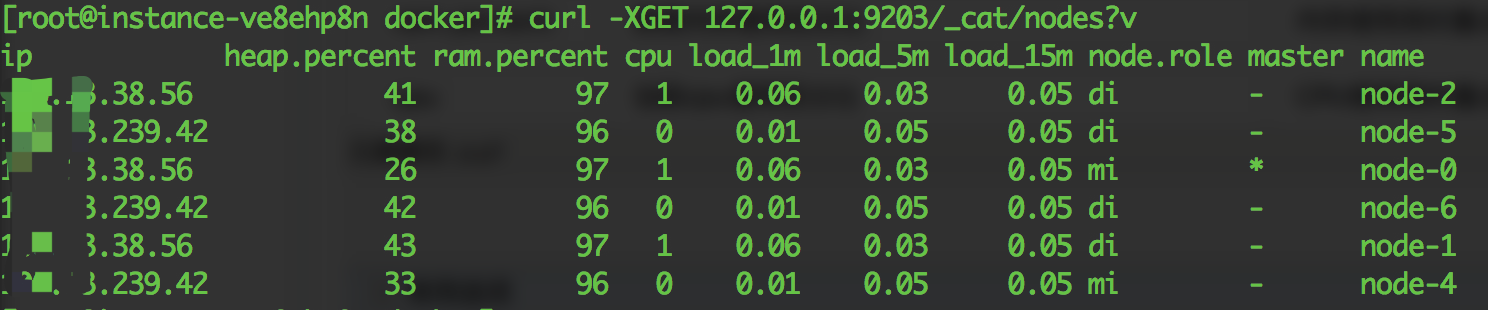
v替换为format=json可以使用json形式返回
| 表头字段 | 含义 | 用途 |
| Ip | IP地址 | |
| heap.percent | heap使用百分比 | 内存使用高时重点关注 |
| ram.percent | 系统内存使用百分比 | 内存使用高时重点关注 |
| cpu | 当前cpu使用百分比 | CPU使用高时重点关注 |
| load_1m | 最近1分钟cpu load | CPU使用高时重点关注 |
| load_5m | 最近5分钟cpu load | CPU使用高时重点关注 |
| load_15m | 最近15分钟cpu load | CPU使用高时重点关注 |
| node.role | 三字母缩写 m: 主节点 d: 数据节点 i: 协调节点 | |
| master | * 表示当前节点为主节点 |
# 分片信息查询
curl -XGET 127.0.0.1:9201/_cat/shards?v
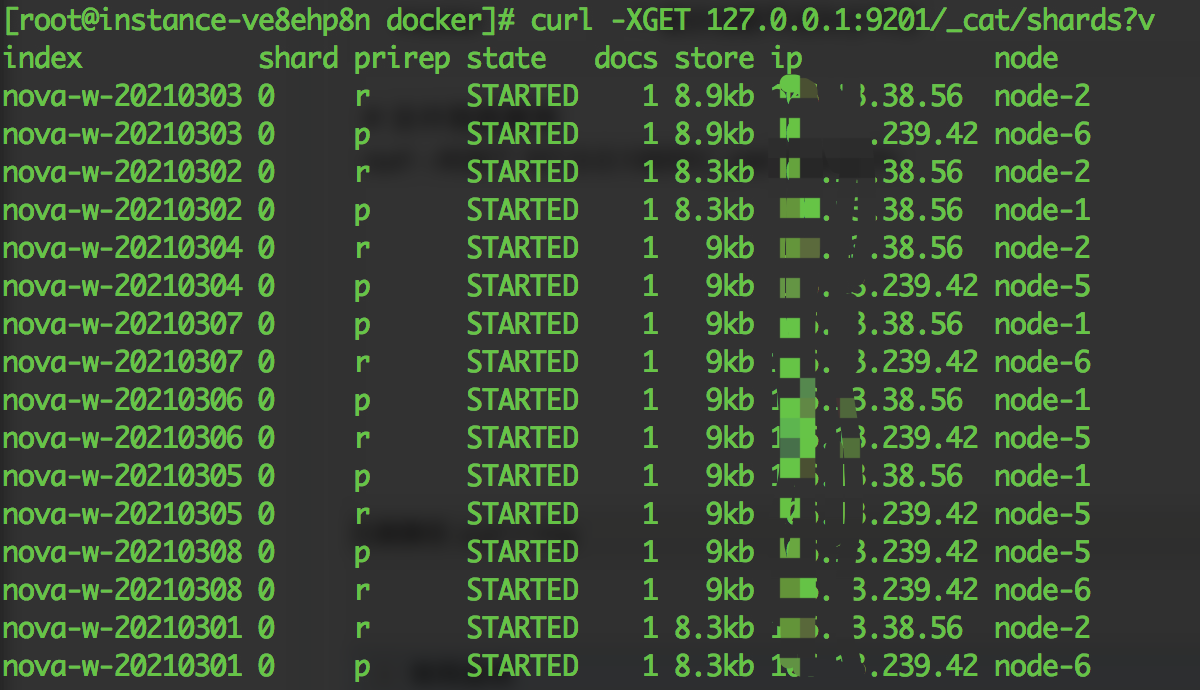
| 表头字段 | 含义 | 用途 |
| index | 索引名 | |
| shard | 分片 | |
| prirep | p:主分片,r:副本分片 | |
| state | 节点状态 | |
| docs | 分片文档数 | |
| store | 分片数据大小 | |
| ip | 分片所在ip地址 | |
| node | 分片所在节点名称 | 结合prirep,确定多个主分片是否分布在同一个节点 |
分片移动(当多个主分片分配在同一节点,造成单节点写入压力较大,可将其中一个主分片移动到空闲节点)
POST _cluster/reroute
{
"commands": [
{
"move": {
"index": "poi-address", // 索引名
"shard": 2, // 分片号
"from_node": "node-1", // 源节点
"to_node": "node-5" // 目标节点
}
}
]
}
commands为json数据,支持多个迁移命令同时执行,可通过GET /_cat/recovery?v 查看迁移进度
六:参考文献
Docker Elasticsearch 集群配置的更多相关文章
- Ubuntu 14.04中Elasticsearch集群配置
Ubuntu 14.04中Elasticsearch集群配置 前言:本文可用于elasticsearch集群搭建参考.细分为elasticsearch.yml配置和系统配置 达到的目的:各台机器配置成 ...
- elasticsearch集群配置 (Tobe Continue)
elasticsearch集群配置 (Tobe Continue) 准备 首先需要在每个节点有可以正常启动的单节点elasticsearch elasticsearch集群配置仅需要在elas ...
- elasticsearch 集群配置
2015-10-10 09:56 by 轩脉刃, 999 阅读, 1 评论, 收藏, 编辑 elasticsearch 集群 搭建elasticsearch的集群 现在假设我们有3台es机器,想要把他 ...
- ES2:ElasticSearch 集群配置
ElasticSearch共有两个配置文件,都位于config目录下,分别是elasticsearch.yml和logging.yml,其中,elasticsearch.yml 用来配置Elastic ...
- ElasticSearch(十):Elasticsearch集群配置
我本地虚拟机配置了两台centos机器,分别安装了elasticsearch6.4.0版本,IP分别为:192.168.56.12, 192.168.56.13 分别修改两个机器上Elasticsea ...
- ElasticSearch集群配置
因机器有限,本文只做单机3个节点的集群测试. 1.集群测试信息 elasticsearch版本:elasticsearch-2.4.1 windowns版本:win10 2.解压elasticsear ...
- Elasticsearch集群配置以及REST API使用
ES安装与启动 在官网下载压缩包,解压后直接运行bin目录下的.bat文件即可.下载地址戳这里. ES配置集群 Elasticsearch配置集群很简单,只要配置一个集群的 名称 ,ES就会自动寻找并 ...
- Docker Swanm集群配置
首先 可以用ContOS虚拟机 克隆 5个虚拟机,注意(克隆主机必须装了Docker,克隆后,克隆机都会有Docker) 配置 网络 克隆CentOS虚拟机 最后和到如下结果 打开2377端口 ...
- Elasticsearch集群搭建教程及生产环境配置
Elasticsearch 是一个极其强大的搜索和分析引擎,其强大的部分在于能够对其进行扩展以获得更好的性能和稳定性. 本教程将提供有关如何设置 Elasticsearch 集群的一些信息,并将添加一 ...
随机推荐
- 22.firewalld
1.firewalld 中常用的区域名称及策略规则 2.firewalld-cmd 命令中使用的参数以及作用 与 Linux 系统中其他的防火墙策略配置工具一样,使用firewalld 配置的防火墙策 ...
- HarmonyOS单模块编译与源码导读
我这里以3518的开发板为例进行讲解,3516的也是通用的. 下面是之前全量编译的脚本 python build.py ipcamera_hi3518ev300 -b debug HarmonyOS最 ...
- 2. Linear Regression with One Variable
Speaker:Andrew Ng 这一次主要讲解的是单变量的线性回归问题. 1.Model Representation 先来一个现实生活中的例子,这里的例子是房子尺寸和房价的模型关系表达. 通过学 ...
- Codeforces Round #657 (Div. 2) B. Dubious Cyrpto(数论)
题目链接:https://codeforces.com/contest/1379/problem/B 题意 给出三个正整数 $l,r,m$,判断在区间 $[l,r]$ 内是否有 $a,b,c$ 满足存 ...
- codeforces#244(div.2) C
动漫节一游回来之后一直处于一种意识模糊的状态 看到大家都陆陆续续地过了C心里还是有点着急(自己没思路啊囧) 其实当时就在想该如何找到DFS中的一个环,然后再找到环路上最小的一个值 把所有环路上最小的值 ...
- 2017-2018 ACM-ICPC German Collegiate Programming Contest (GCPC 2017)(9/11)
$$2017-2018\ ACM-ICPC\ German\ Collegiate\ Programming\ Contest (GCPC 2017)$$ \(A.Drawing\ Borders\) ...
- Dire Wolf——HDU5115
Dire wolves, also known as Dark wolves, are extraordinarily large and powerful wolves. Many, if not ...
- hdu-6699 Block Breaker
题意: 就是给你一个n行m列的矩形,后面将会有q次操作,每次操作会输入x,y表示要击碎第x行第y列的石块,当击碎它之后还去判断一下周围石块是否牢固 如果一个石块的左右两边至少一个已经被击碎且上下也至少 ...
- 一维二维Sparse Table
写在前面: 记录了个人的学习过程,同时方便复习 Sparse Table 有些情况,需要反复读取某个指定范围内的值而不需要修改 逐个判断区间内的每个值显然太浪费时间 我们希望用空间换取时间 ST表就是 ...
- AtCoder Beginner Contest 179 E - Sequence Sum (模拟)
题意:\(f(x,m)\)表示\(x\ mod\ m\),\(A_{1}=1\),而\(A_{n+1}=f(A^{2}_{n},M)\),求\(\sum^{n}_{i=1}A_{i}\). 题解:多算 ...