论文阅读笔记: Multi-Perspective Sentence Similarity Modeling with Convolution Neural Networks
论文概况
Multi-Perspective Sentence Similarity Modeling with Convolution Neural Networks是处理比较两个句子相似度的问题, 适用于解决智能客服问题匹配场景中用户提交的问句与知识库中问句的匹配.
文章将整个问题的解决分成两部分:
- 对句子进行建模, 将句子转换为某种向量表示. 这部分使用CNN完成
- 两个句子相似度衡量的方式. 这里是新颖的地方.
然后将衡量计算得到的相似度向量投入到Dense层中, 再根据目标接Output层(如sigmoid层, softmax层等), 训练得到模型.
整体的结构如下:
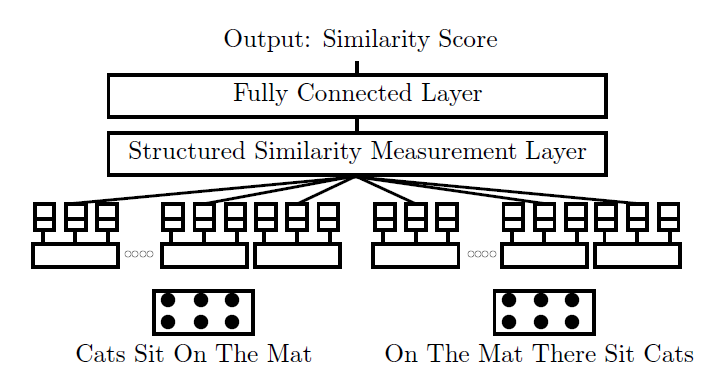
按照模型的结构, 分成两部分阐述模型结构.
句子模型(sentence model)
整体模型如下图:
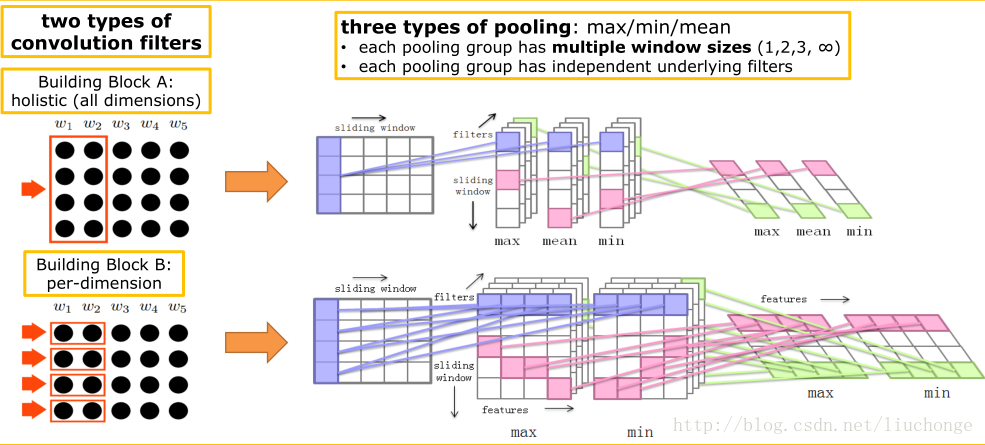
首先预训练一个embedding层, 将句子按词转换为embedding后的结果.
对于一个长度为SEQ_LEN的句子, 若embedding向量的长度为EMBED_SIZE, 那么输入到句子模型中的每个句子的数据矩阵为大小为(SEQ_LEN, EMBED_SIZE). 这里我们不考虑BATCH_SIZE的大小, 实际在模型中的Tensor, 只需在第一维上拼接上BATCH_SIZE即可.
论文中使用了两种卷积核:
整体卷积核(holistic)
这种卷积核就是我们正常使用的卷积核, 大小为
(ws, A_num_filters).ws为卷积核的window大小, 代表评价相邻的若干个词之间关系, 论文中取ws={1, 2, 3, SEQ_LEN}, 之所以有一种卷积核的window为SEQ_LEN, 是衡量整个句子的特征.A_num_filters表示这个卷积核的通道数量, 论文中没有给出具体数值.
文章中卷积核进行卷积都是采用
valid方式, 造成输出序列长度减小. 具体来说, 对于此类卷积核的输出output_A的大小为(SEQ_LEN + 1 - ws, A_num_filters).单维卷积核(per-dimension)
上面的卷积核是会对输入在
EMBED_SIZE所有维上卷积相加得到一个输出. 这里的单维指的是一个卷积核只对输入向量的一个维度进行卷积, 输入向量有多长, 就有多少个卷积核, 考虑每个卷积核自己的通道数量, 因此单维卷积核的大小为(ws, EMBED_SIZE, B_num_filters).ws在这里只取{1, 2}即可.B_num_filters区别与A_num_filters, 即两种卷积核各自的通道数是不同的. 但同种卷积核的通道数是相同的.
因此, 这种卷积核的输出
output_B的大小为(SEQ_LEN + 1 - ws, EMBED_SIZE, B_num_filters).两种卷积核的输出维度不同, 但由于后文中计算相似度的特殊方式, 这里并不需要把结果展平.
池化层:
- 对于整体卷积核, 使用
{max, min, avg}三种池化层, 将它们的结果合并起来. - 对于单维卷积核, 使用
{max, min}两种池化层, 将它们的结果合并起来.
相似度计算模型
引入三种计算距离的方式:
- 余弦距离, L1距离, L2距离
组合成两种距离计算函数:
- \(comU_1(\textbf{x}, \textbf{y})=\{\cos(\textbf{x}, \textbf{y}), L_2(\textbf{x}, \textbf{y}), L_1(\textbf{x}, \textbf{y})\}\)
- \(comU_2(\textbf{x}, \textbf{y})=\{\cos(\textbf{x}, \textbf{y}), L_2(\textbf{x}, \textbf{y})\}\)
在输入经过不同的卷积层, 池化层之后, 会得到数据的结果, 我们不能简单的把所有的结果展开并拼接在一起, 组成一个大的向量, 然后计算相似度. 我们要考虑结果来源的相似程度, 具体来说, 从以下四个角度判断:
- 结果是否来自同一个
block, 即同一个输入, 同一种卷积核长度, 区别只在于池化层不同 - 结果是否来自同一个卷积核长度
- 结果是否来自同一个池化层
- 结果是否来自相同的通道, 可以是不同卷积核
以上四种衡量标准对于两种卷积核是分开的, 即相互之间不比较. 而且计算相似度时独立.
论文中提出了两种算法计算句子的相似度, 这两种算法都是结合以上四种规则中, 至少满足两种, 才能认为来源相似, 从而分块计算相似度. 将每一块的相似度累加得到最终的两个句子的相似度.
算法如下:

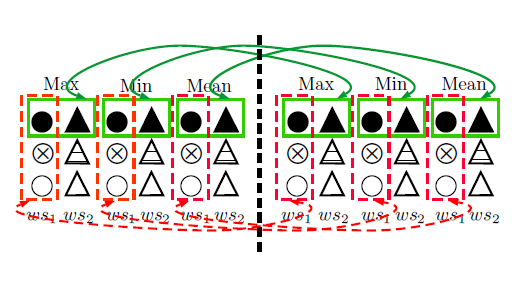
其中算法1只能对整体卷积核使用, 算法2对两种卷积核都适用. 我们将算法计算得到的相似度向量在接上一个Dense层, 最后接Output层, 就得到了完整的模型结构.
论文阅读笔记: Multi-Perspective Sentence Similarity Modeling with Convolution Neural Networks的更多相关文章
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- [置顶]
人工智能(深度学习)加速芯片论文阅读笔记 (已添加ISSCC17,FPGA17...ISCA17...)
这是一个导读,可以快速找到我记录的关于人工智能(深度学习)加速芯片论文阅读笔记. ISSCC 2017 Session14 Deep Learning Processors: ISSCC 2017关于 ...
- Nature/Science 论文阅读笔记
Nature/Science 论文阅读笔记 Unsupervised word embeddings capture latent knowledge from materials science l ...
- 论文阅读笔记(二十一)【CVPR2017】:Deep Spatial-Temporal Fusion Network for Video-Based Person Re-Identification
Introduction (1)Motivation: 当前CNN无法提取图像序列的关系特征:RNN较为忽视视频序列前期的帧信息,也缺乏对于步态等具体信息的提取:Siamese损失和Triplet损失 ...
- 论文阅读笔记(十八)【ITIP2019】:Dynamic Graph Co-Matching for Unsupervised Video-Based Person Re-Identification
论文阅读笔记(十七)ICCV2017的扩刊(会议论文[传送门]) 改进部分: (1)惩罚函数:原本由两部分组成的惩罚函数,改为只包含 Sequence Cost 函数: (2)对重新权重改进: ① P ...
- [论文阅读笔记] GEMSEC,Graph Embedding with Self Clustering
[论文阅读笔记] GEMSEC: Graph Embedding with Self Clustering 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 已经有一些工作在使用学习 ...
随机推荐
- Revisiting Fundamentals of Experience Replay
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! ICML 2020 Abstract 经验回放对于深度RL中的异策算法至关重要,但是在我们的理解上仍然存在很大差距.因此,我们对Q学习方法 ...
- The Successor Representation: Its Computational Logic and Neural Substrates
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! Received May 14, 2018; revised June 28, 2018; accepted July 5, 2018.T ...
- 关于函数式接口, printable 自定义
这段代码在jdk1.8可以使用, 由于我是jdk14, 会报错. 这里可以优化, lambda表达式进一步优化写为: printString(System.Out::println); 注意案例版 ...
- idea 执行maven打包命令时,修改war包名称
- day03 每日一行
day03 每日一行 问题描述 用列表解释式 .生成器表达式实现 字典列表为: [{'first': 'john', 'last': 'smith', 'email': 'jsmith@exsampl ...
- Orleans 知多少 | Orleans 中文文档上线
Orleans 简介 Orleans是一个跨平台框架,用于构建健壮,可扩展的分布式应用程序 Orleans建立在.NET开发人员生产力的基础上,并将其带入了分布式应用程序的世界,例如云服务. Orle ...
- Cookie:SameSite,防止CSRF攻击
前言 最近在本地调试时,发现请求接口提示“未登录”,通过分析HTTP请求报文发现未携带登录状态的Cookie: PS:登录状态Cookie名是TEST 再进一步分析,发现Cookie的属性SameSi ...
- 使用DataStax Java驱动程序的最佳实践
引言 如果您想开始建立自己的基于Cassandra的Java程序,欢迎! 也许您已经参加过我们精彩的DataStax Academy课程或开发者大会,又或者仔细阅读过Cassandra Java驱动的 ...
- 使用java爬虫从雪球网下载股票数据
雪球网也是采用Ajax方式展示数据,我依然采用开发者工具查看其访问地址和返回数据. 访问使用到的库是jsoup,解析返回的json用的类库是jackson,二者的依赖是: <!-- jsoup ...
- java 将map转为实体类
使用反射将map转为对象,如果不使用反射的话需要一个get一个set写起来麻烦,并且不通用,所以写了一个通用的方法将map集合转为对象,直接看代码,注释也都挺清楚的 public static < ...