论文阅读笔记: Multi-Perspective Sentence Similarity Modeling with Convolution Neural Networks
论文概况
Multi-Perspective Sentence Similarity Modeling with Convolution Neural Networks是处理比较两个句子相似度的问题, 适用于解决智能客服问题匹配场景中用户提交的问句与知识库中问句的匹配.
文章将整个问题的解决分成两部分:
- 对句子进行建模, 将句子转换为某种向量表示. 这部分使用CNN完成
- 两个句子相似度衡量的方式. 这里是新颖的地方.
然后将衡量计算得到的相似度向量投入到Dense层中, 再根据目标接Output层(如sigmoid层, softmax层等), 训练得到模型.
整体的结构如下:
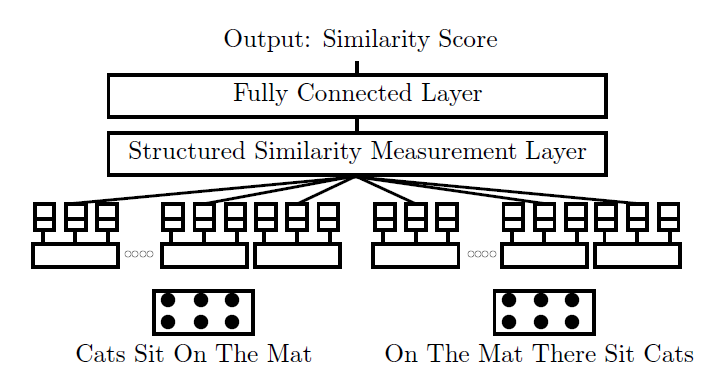
按照模型的结构, 分成两部分阐述模型结构.
句子模型(sentence model)
整体模型如下图:
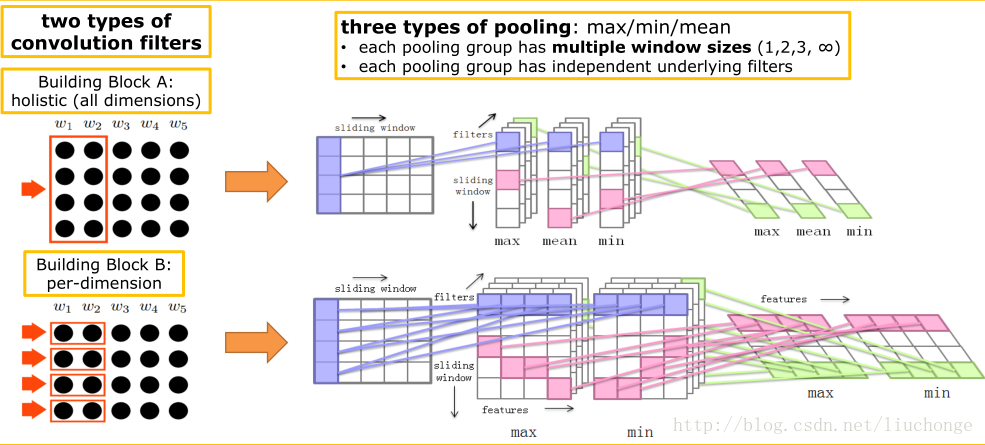
首先预训练一个embedding层, 将句子按词转换为embedding后的结果.
对于一个长度为SEQ_LEN的句子, 若embedding向量的长度为EMBED_SIZE, 那么输入到句子模型中的每个句子的数据矩阵为大小为(SEQ_LEN, EMBED_SIZE). 这里我们不考虑BATCH_SIZE的大小, 实际在模型中的Tensor, 只需在第一维上拼接上BATCH_SIZE即可.
论文中使用了两种卷积核:
整体卷积核(holistic)
这种卷积核就是我们正常使用的卷积核, 大小为
(ws, A_num_filters).ws为卷积核的window大小, 代表评价相邻的若干个词之间关系, 论文中取ws={1, 2, 3, SEQ_LEN}, 之所以有一种卷积核的window为SEQ_LEN, 是衡量整个句子的特征.A_num_filters表示这个卷积核的通道数量, 论文中没有给出具体数值.
文章中卷积核进行卷积都是采用
valid方式, 造成输出序列长度减小. 具体来说, 对于此类卷积核的输出output_A的大小为(SEQ_LEN + 1 - ws, A_num_filters).单维卷积核(per-dimension)
上面的卷积核是会对输入在
EMBED_SIZE所有维上卷积相加得到一个输出. 这里的单维指的是一个卷积核只对输入向量的一个维度进行卷积, 输入向量有多长, 就有多少个卷积核, 考虑每个卷积核自己的通道数量, 因此单维卷积核的大小为(ws, EMBED_SIZE, B_num_filters).ws在这里只取{1, 2}即可.B_num_filters区别与A_num_filters, 即两种卷积核各自的通道数是不同的. 但同种卷积核的通道数是相同的.
因此, 这种卷积核的输出
output_B的大小为(SEQ_LEN + 1 - ws, EMBED_SIZE, B_num_filters).两种卷积核的输出维度不同, 但由于后文中计算相似度的特殊方式, 这里并不需要把结果展平.
池化层:
- 对于整体卷积核, 使用
{max, min, avg}三种池化层, 将它们的结果合并起来. - 对于单维卷积核, 使用
{max, min}两种池化层, 将它们的结果合并起来.
相似度计算模型
引入三种计算距离的方式:
- 余弦距离, L1距离, L2距离
组合成两种距离计算函数:
- \(comU_1(\textbf{x}, \textbf{y})=\{\cos(\textbf{x}, \textbf{y}), L_2(\textbf{x}, \textbf{y}), L_1(\textbf{x}, \textbf{y})\}\)
- \(comU_2(\textbf{x}, \textbf{y})=\{\cos(\textbf{x}, \textbf{y}), L_2(\textbf{x}, \textbf{y})\}\)
在输入经过不同的卷积层, 池化层之后, 会得到数据的结果, 我们不能简单的把所有的结果展开并拼接在一起, 组成一个大的向量, 然后计算相似度. 我们要考虑结果来源的相似程度, 具体来说, 从以下四个角度判断:
- 结果是否来自同一个
block, 即同一个输入, 同一种卷积核长度, 区别只在于池化层不同 - 结果是否来自同一个卷积核长度
- 结果是否来自同一个池化层
- 结果是否来自相同的通道, 可以是不同卷积核
以上四种衡量标准对于两种卷积核是分开的, 即相互之间不比较. 而且计算相似度时独立.
论文中提出了两种算法计算句子的相似度, 这两种算法都是结合以上四种规则中, 至少满足两种, 才能认为来源相似, 从而分块计算相似度. 将每一块的相似度累加得到最终的两个句子的相似度.
算法如下:

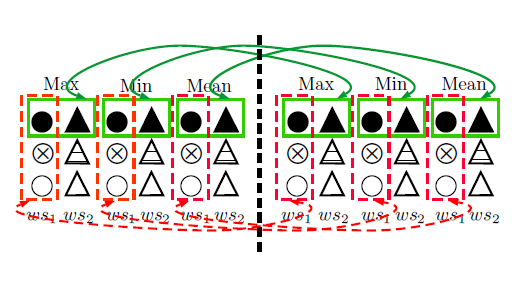
其中算法1只能对整体卷积核使用, 算法2对两种卷积核都适用. 我们将算法计算得到的相似度向量在接上一个Dense层, 最后接Output层, 就得到了完整的模型结构.
论文阅读笔记: Multi-Perspective Sentence Similarity Modeling with Convolution Neural Networks的更多相关文章
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- [置顶]
人工智能(深度学习)加速芯片论文阅读笔记 (已添加ISSCC17,FPGA17...ISCA17...)
这是一个导读,可以快速找到我记录的关于人工智能(深度学习)加速芯片论文阅读笔记. ISSCC 2017 Session14 Deep Learning Processors: ISSCC 2017关于 ...
- Nature/Science 论文阅读笔记
Nature/Science 论文阅读笔记 Unsupervised word embeddings capture latent knowledge from materials science l ...
- 论文阅读笔记(二十一)【CVPR2017】:Deep Spatial-Temporal Fusion Network for Video-Based Person Re-Identification
Introduction (1)Motivation: 当前CNN无法提取图像序列的关系特征:RNN较为忽视视频序列前期的帧信息,也缺乏对于步态等具体信息的提取:Siamese损失和Triplet损失 ...
- 论文阅读笔记(十八)【ITIP2019】:Dynamic Graph Co-Matching for Unsupervised Video-Based Person Re-Identification
论文阅读笔记(十七)ICCV2017的扩刊(会议论文[传送门]) 改进部分: (1)惩罚函数:原本由两部分组成的惩罚函数,改为只包含 Sequence Cost 函数: (2)对重新权重改进: ① P ...
- [论文阅读笔记] GEMSEC,Graph Embedding with Self Clustering
[论文阅读笔记] GEMSEC: Graph Embedding with Self Clustering 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 已经有一些工作在使用学习 ...
随机推荐
- kali安装open-vm-tools实现虚拟机交互
普通的VMware tools 弱爆了 安装具有复制粘贴功能的open-vm-tools.servic: 切记:如果之前已经安装了VMware tools,一定要删除:vmware-uninstall ...
- 方差分析、T检验、卡方分析如何区分?
差异研究的目的在于比较两组数据或多组数据之间的差异,通常包括以下几类分析方法,分别是方差分析.T检验和卡方检验. 三个方法的区别 其实核心的区别在于:数据类型不一样.如果是定类和定类,此时应该使用卡方 ...
- koa-graphql express-graphql 中如何 定义每一个字段resolver执行函数
第一种方式: 首先来看一下,官方给出的koa-graphql的例子, ```js var express = require('express'); var {graphqlHTTP} = requ ...
- JVM系列.历史上出现过的Java虚拟机
HotSpot绝对是当今商用虚拟机的王者,但是在Java历史上出现过很多Java虚拟机,这篇文章就来整理下历史上出现过的Java虚拟机以及他们的特性. Sun Classic Sun Classic虚 ...
- python sqlite3简单操作
python sqlite3简单操作(原创)import sqlite3class CsqliteTable: def __init__(self): pass def linkSqlite3(sel ...
- Qt setMouseTracking使用
Qt setMouseTracking使用(转载) bool mouseTracking 这个属性保存的是窗口部件跟踪鼠标是否生效. 如果鼠标跟踪失效(默认),当鼠标被移动的时候只有在至少一个鼠标 ...
- 《MySQL数据库》MySQL主从复制搭建与原理
前言 主从复制:两台或者更多的数据库实例,通过二进制日志,实现数据同步.为什么需要主从复制,主从复制的作用是什么,答:为了预防灾难. 搭建 第一步:准备多实例环境.如何创建多实例见: 第二步:确保每一 ...
- 力扣Leetcode 179. 最大数 EOJ 和你在一起 字符串拼接 组成最大数
最大数 力扣 给定一组非负整数,重新排列它们的顺序使之组成一个最大的整数. 示例 1: 输入: [10,2] 输出: 210 示例 2: 输入: [3,30,34,5,9] 输出: 9534330 说 ...
- 现在的市场对 C++ 的需求大吗?
分享 大师助手 先说结论:需求还是很大,但是没有什么初级程序员能干的岗位. 游戏引擎,存储,推荐引擎,infra,各种各样的性能敏感场景.这些都是C++的刚需场景,别的语言基本替代不了的.除了pin ...
- SpringBoot中加载XML配置
开篇 在SpringBoot中我们通常都是基于注解来开发的,实话说其实这个功能比较鸡肋,但是,SpringBoot中还是能做到的.所以用不用是一回事,会不会又是另外一回事. 涛锅锅在个人能力能掌握的范 ...