重要,知识点:InnoDB的插入缓冲
世界上最快的捷径,就是脚踏实地,本文已收录【架构技术专栏】关注这个喜欢分享的地方。
InnoDB引擎有几个重点特性,为其带来了更好的性能和可靠性:
- 插入缓冲(Insert Buffer)
- 两次写(Double Write)
- 自适应哈希索引(Adaptive Hash Index)
- 异步IO(Async IO)
- 刷新邻接页(Flush Neighbor Page)
今天我们的主题就是 插入缓冲(Insert Buffer),由于InnoDB引擎底层数据存储结构式B+树,而对于索引我们又有聚集索引和非聚集索引。
在进行数据插入时必然会引起索引的变化,聚集索引不必说,一般都是递增有序的。而非聚集索引就不一定是什么数据了,其离散性导致了在插入时结构的不断变化,从而导致插入性能降低。
所以为了解决非聚集索引插入性能的问题,InnoDB引擎 创造了Insert Buffer。
Insert Buffer 的存储
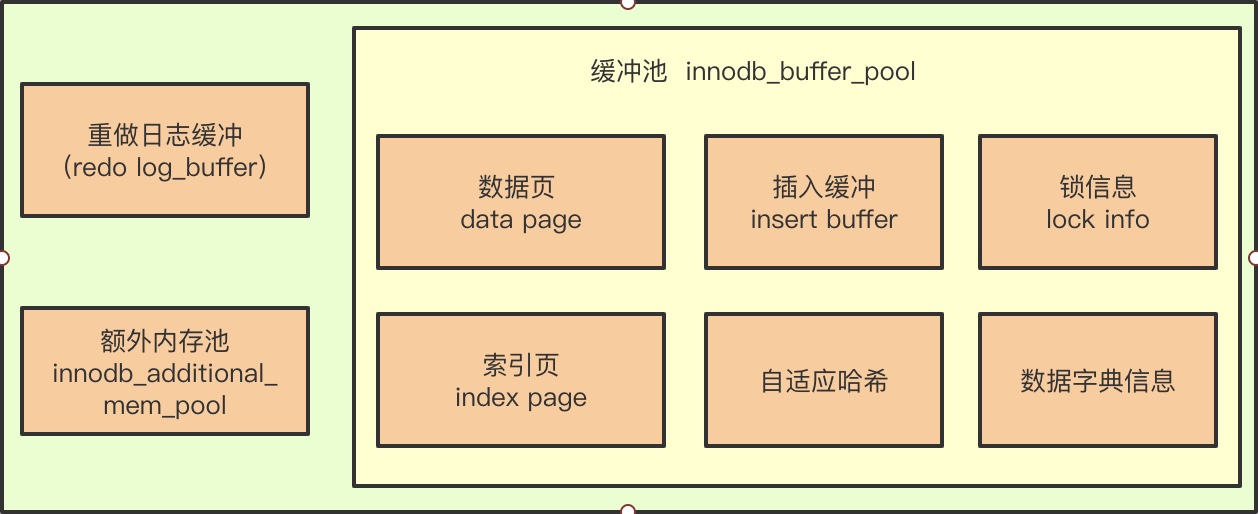
看到上图,可能大家会认为Insert Buffer 就是InnoDB 缓冲池的一个组成部分。
重点:其实对也不对,InnoDB 缓冲池确实包含了Insert Buffer的信息,但Insert Buffer 其实和数据页一样,也是物理存在的(以B+树的形式存在共享表空间中)。
Insert Buffer 的作用
先说几个点:
一张表只能有一个主键索引,那是因为其物理存储是一个B+树。(别忘了聚集索引叶子节点存储的数据,而数据只有一份)
非聚集索引叶子节点存的是聚集索引的主键

聚集索引的插入
首先我们知道在InnoDB存储引擎中,主键是行唯一的标识符(也就是我们常叨叨的聚集索引)。我们平时插入数据一般都是按照主键递增插入,因此聚集索引都是顺序的,不需要磁盘的随机读取。
比如表:
CREATE TABLE test(
id INT AUTO_INCREMENT,
name VARCHAR(30),
PRIMARY KEY(id)
);
如上我创建了一个主键 id,它有以下的特性:
- Id列是自增长的
- Id列插入NULL值时,由于AUTO_INCREMENT的原因,其值会递增
- 同时数据页中的行记录按id的值进行顺序存放
一般情况下由于聚集索引的有序性,不需要随机读取页中的数据,因为此类的顺序插入速度是非常快的。
但如果你把列 Id 插入UUID这种数据,那你插入就是和非聚集索引一样都是随机的了。会导致你的B+ tree结构不停地变化,那性能必然会受到影响。
非聚集索引的插入
很多时候我们的表还会有很多非聚集索引,比如我按照b字段查询,且b字段不是唯一的。如下表:
CREATE TABLE test(
id INT AUTO_INCREMENT,
name VARCHAR(30),
PRIMARY KEY(id),
KEY(name)
);
这里我创建了一个x表,它有以下特点:
- 有一个聚集索引 id
- 有一个不唯一的非聚集索引 name
- 在插入数据时数据页是按照主键id进行顺序存放
- 辅助索引 name的数据插入不是顺序的
非聚集索引也是一颗B+树,只是叶子节点存的是聚集索引的主键和name 的值。
因为不能保证name列的数据是顺序的,所以非聚集索引这棵树的插入必然也不是顺序的了。
当然如果name列插入的是时间类型数据,那其非聚集索引的插入也是顺序的。
Insert Buffer 的到来
可以看出非聚集索引插入的离散性导致了插入性能的下降,因此InnoDB引擎设计了 Insert Buffer来提高插入性能 。
我来看看使用Insert Buffer 是怎么插入的:
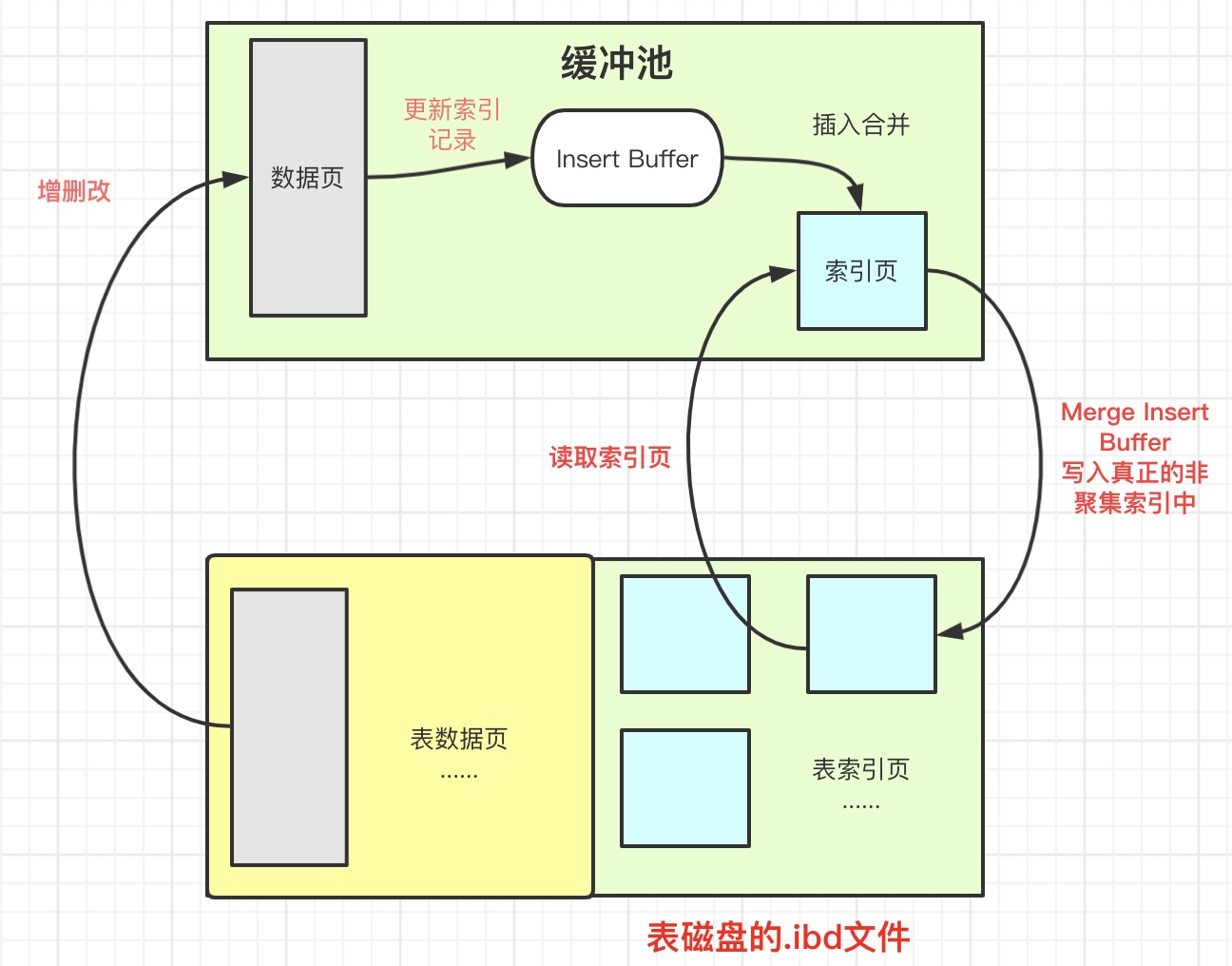
首先对于非聚集索引的插入或更新操作,不是每一次直接插入到索引页中,而是先判断插入的非聚集索引页是否在缓冲池中。
若在,则直接插入;若不在,则先放入到一个Insert Buffer对象中。
给外部的感觉好像是树已经插入非聚集的索引的叶子节点,而其实是存放在其他位置了
以一定的频率和情况进行Insert Buffer和辅助索引页子节点的merge(合并)操作,通常会将多个插入操作一起进行merge,这就大大的提升了非聚集索引的插入性能。
Insert Buffer的使用要求:
- 索引是非聚集索引
- 索引不是唯一(unique)的
只有满足上面两个必要条件时,InnoDB存储引擎才会使用Insert Buffer来提高插入性能。
那为什么必须满足上面两个条件呢?
第一点索引是非聚集索引就不用说了,人家聚集索引本来就是顺序的也不需要你
第二点必须不是唯一(unique)的,因为在写入Insert Buffer时,数据库并不会去判断插入记录的唯一性。如果再去查找肯定又是离散读取的情况了,这样InsertBuffer就失去了意义。
Insert Buffer信息查看
我们可以使用命令SHOW ENGINE INNODB STATUS来查看Insert Buffer的信息:
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 7545, free list len 3790, seg size 11336,
8075308 inserts,7540969 merged sec, 2246304 merges
...
使用命令后,我们会看到很多信息,这里我们只看下INSERT BUFFER 的:
seg size 代表当前Insert Buffer的大小 11336*16KB
free listlen 代表了空闲列表的长度
size 代表了已经合并记录页的数量
Inserts 代表了插入的记录数
merged recs 代表了合并的插入记录数量
merges 代表合并的次数,也就是实际读取页的次数
merges:merged recs大约为1∶3,代表了Insert Buffer 将对于非聚集索引页的离散IO逻辑请求大约降低了2/3
Insert Buffer的问题
说了这么多针对于Insert Buffer的好处,但目前Insert Buffer也存在一个问题:
即在写密集的情况下,插入缓冲会占用过多的缓冲池内存(innodb_buffer_pool),默认最大可以占用到1/2的缓冲池内存。
占用了过大的缓冲池必然会对其他缓冲池操作带来影响
Insert Buffer的优化
MySQL5.5之前的版本中其实都叫做Insert Buffer,之后优化为 Change Buffer 可以看做是 Insert Buffer 的升级版。
插入缓冲( Insert Buffer)这个其实只针对 INSERT 操作做了缓冲,而Change Buffer 对INSERT、DELETE、UPDATE都进行了缓冲,所以可以统称为写缓冲,其可以分为:
Insert Buffer
Delete Buffer
Purgebuffer
总结:
Insert Buffer到底是个什么?
其实Insert Buffer的数据结构就是一棵B+树。
在MySQL 4.1之前的版本中每张表有一棵Insert Buffer B+树
目前版本是全局只有一棵Insert Buffer B+树,负责对所有的表的辅助索引进行Insert Buffer
这棵B+树存放在共享表空间ibdata1中
以下几种情况下 Insert Buffer会写入真正非聚集索引,也就是所说的Merge Insert Buffer
- 当辅助索引页被读取到缓冲池中时
- Insert Buffer Bitmap页追踪到该辅助索引页已无可用空间时
- Master Thread线程中每秒或每10秒会进行一次Merge Insert Buffer的操作
一句话概括下:
Insert Buffer 就是用于提升非聚集索引页的插入性能的,其数据结构类似于数据页的一个B+树,物理存储在共享表空间ibdata1中 。
重要,知识点:InnoDB的插入缓冲的更多相关文章
- InnoDB Insert Buffer(插入缓冲)
InnoDB Insert Buffer(插入缓冲) 每个存储存储引擎自身都有自己的特性(决定性能以及更高可靠性),而InnoDB的关键特性有: 插入缓冲(Insert Buffer)-->Ch ...
- InnoDB Insert Buffer(插入缓冲 转)
一,插入缓冲(Insert Buffer/Change Buffer):提升插入性能 只对于非聚集索引(非唯一)的插入和更新有效,对于每一次的插入不是写到索引页中,而是先判断插入的非聚集索引页是否在缓 ...
- 【InnoDB】插入缓存,两次写,自适应hash索引
InnoDB存储引擎的关键特性包括插入缓冲.两次写(double write).自适应哈希索引(adaptive hash index).这些特性为InnoDB存储引擎带来了更好的性能和更高的可靠性. ...
- Mysql中Innodb大量插入数据时SQL语句的优化
innodb优化后,29小时入库1300万条数据 参考:http://blog.51yip.com/mysql/1369.html 对于Myisam类型的表,可以通过以下方式快速的导入大量的数据: A ...
- 关于Mysql表InnoDB下插入速度慢的解决方案
最近做了 server_log 日志数据库记录,仅仅插入,由平台来获取数据进行分析的需求. 但是内部反馈插入数据库记录非常耗时,我就很纳闷了,一个insert怎么会 30-50ms 呢?按说应该在 0 ...
- innodb 乐观插入因空间不够导致失败,进入悲观插入阶段,这个空间的大小限制
btr_cur_optimistic_insert{ ... /*检查分裂页时是否有足够的空间预留给未来记录的update*/ if (leaf && !zip_size && ...
- 敲黑板:InnoDB的Double Write,你必须知道
世界上最快的捷径,就是脚踏实地,本文已收录[架构技术专栏]关注这个喜欢分享的地方. 前序 InnoDB引擎有几个重点特性,为其带来了更好的性能和可靠性: 插入缓冲(Insert Buffer) 两次写 ...
- MySQL(3)-日志
3. InnoDB日志 3.1 InnoDB架构 分为 内存区域架构 buffer pool log buffer 磁盘区域架构 redo log undo log 2.1.1 内存区域架构 1)Bu ...
- (转)mysql各个主要版本之间的差异
原文:http://blog.csdn.net/z1988316/article/details/8095407 一.各版本的常用命令差异 show innodb status\G mysql-5 ...
随机推荐
- How to write Chinese in LaTeX
Add the following package to the preamble. \usepackage{xeCJK} Write Chinese in your latex editor. Co ...
- throw throws try catch finally return
throw throw 语句用于抛出异常,例如 throw new EOFException(). throws 当使用throw 语句抛出checked 异常后,可以不用捕获异常并处理,而是使用 ...
- mysql-3-orderby
#进阶3:排序查询 /* 语法: SELECT FROM WHERE ORDER BY ASC|DESC */ USE myemployees; #案例1:查询员工信息,按工资从高到低排 SELECT ...
- Win10系统下的MySQL5.7.24版本(解压版)详细安装教程
进入MySQL官网下载压缩包 MySQL官网:https://www.mysql.com/ 将页面拉到最底,点击MySQL Community Server 跳转到下载页面,默认选择是最新版MySQL ...
- iNeuOS工业互联平台,在“智慧”楼宇、园区等领域的应用
目 录 1. 概述... 1 2. 平台演示... 2 3. 硬件网关... 2 4. 平台接入硬件网关... 4 1. 概述 " ...
- 066 01 Android 零基础入门 01 Java基础语法 08 Java方法 02 带参有返回值方法
066 01 Android 零基础入门 01 Java基础语法 08 Java方法 04 带参有返回值方法 本文知识点:带参有返回值方法 说明:因为时间紧张,本人写博客过程中只是对知识点的关键步骤进 ...
- 063 01 Android 零基础入门 01 Java基础语法 08 Java方法 01 无参无返回值方法
063 01 Android 零基础入门 01 Java基础语法 08 Java方法 01 无参无返回值方法 本文知识点:无参无返回值方法 无参无返回值方法 案例 为什么使用方法?--方便复杂问题调用 ...
- Java知识系统回顾整理01基础01第一个程序06Eclipse使用技巧
一.批量修改 ALT+SHIFT+R 二.快速输入主方法 1. 敲入main 2. alt+/ 三.快速输入System.out.println 1. 敲入syso 2. alt+/ 四.快速输入fo ...
- 03 sublime text3下配置Java的编译运行环境
参考如下文章,加入了自己的干货: https://blog.csdn.net/qq_38295511/article/details/81140069 https://blog.csdn.net/qq ...
- 剑指Offer(三):从尾到头打印链表
一.前言 刷题平台:牛客网 二.题目 输入一个链表,返回一个反序的链表. 1.思路 通常,这种情况下,我们不希望修改原链表的结构.返回一个反序的链表,这就是经典的"后进先出",我们 ...