Explain Plan试分析
注:以下是本人对Explain Plan的试分析,有不对的地方希望大家指出。关于如何查看Oracle的解释计划请参考:https://www.cnblogs.com/xiandedanteng/p/12123819.html
例一:
执行的SQL语句:
EXPLAIN plan for
select * from hy_emp emp,hy_dept dept
where emp.deptno=dept.deptno and emp.empno=1 select * from table(dbms_xplan.display)
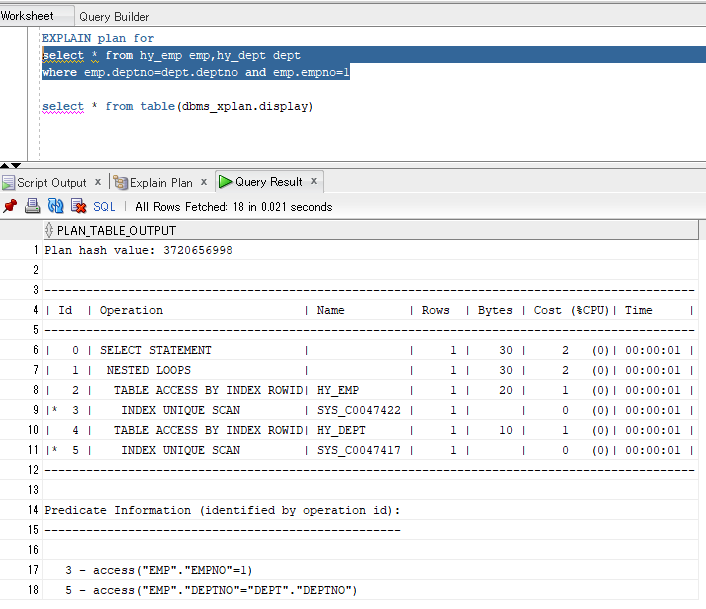
首先执行#3,在HY_EMP表进行empno=1的查找(索引唯一扫描方式);
再执行#5,在HY_DEPT表进行emp.deptno=dept.deptno的连接(索引唯一扫描方式);
然后,把两个结果集进行嵌套循环连接;
最后,把select子句里的字段带上。
例二:
执行的SQL语句:
EXPLAIN plan for select * from hy_emp emp,hy_dept dept
where emp.deptno=dept.deptno and emp.ename='Andy' select * from table(dbms_xplan.display)
截图:
分析:
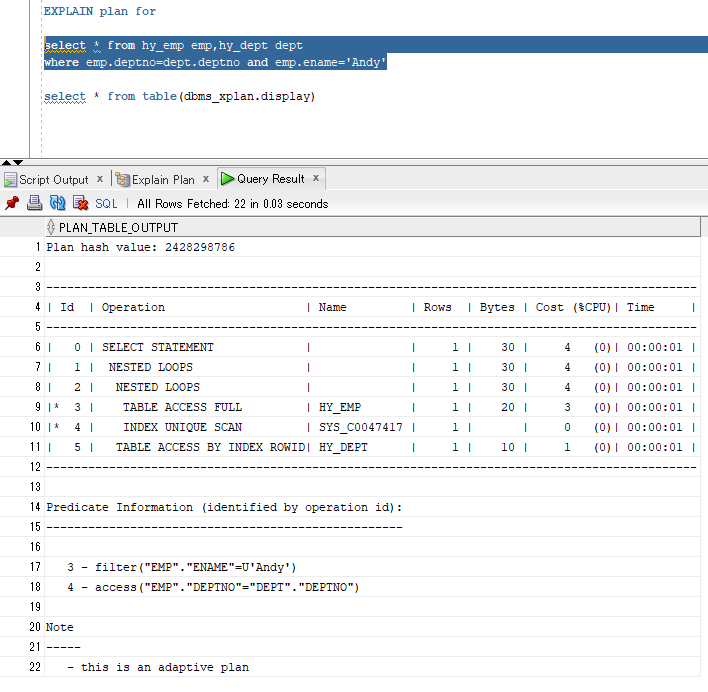
#9先执行,在emp表进行NAME=Andy的筛选,不要的数据丢弃(ENAME不是emp表的主键);
#10第二执行,在emp表查找DEPTNO能与DEPT表对应上的记录(直接去取ACCESS方式,因为DEPTNO是DEPT表的主键);
#8第三执行,将#9,#10两步得到的结果集(两者都是EMP表的子集)进行嵌套循环连接;
接下来,将#8得到的结果集与#11进行嵌套循环连接(直接去取ACCESS方式,因为DEPTNO是DEPT表的主键)
最后执行#6,把select子句都带出来。
例三:
SQL:
EXPLAIN plan for select emp.* from hy_emp emp,hy_dept dept
where emp.deptno=dept.deptno and emp.ename='Andy' select * from table(dbms_xplan.display)
截图:
解读:
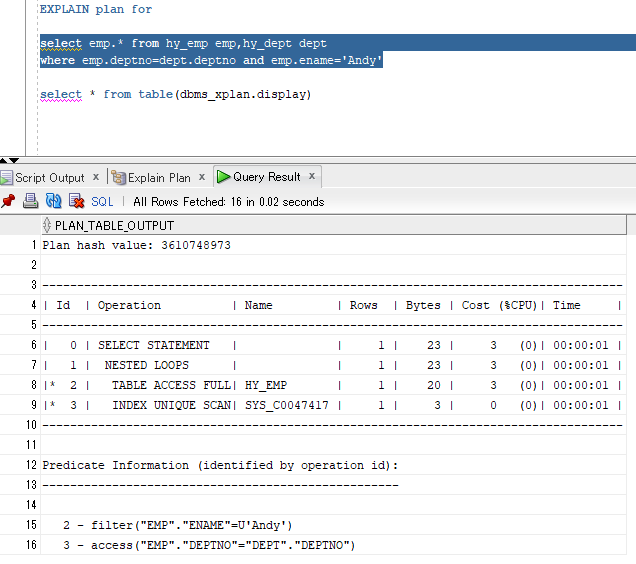
#8先执行,在emp表进行NAME=Andy的筛选,不要的数据丢弃(ENAME不是emp表的主键);
#9第二执行,在emp表查找DEPTNO能与DEPT表对应上的记录(直接去取ACCESS方式,因为DEPTNO是DEPT表的主键)
#7再执行,将#8,#9两步得到的结果集(均为emp的子集)进行嵌套循环连接;
由于select子句中只要emp表的字段,因此#7得到的结果集就是最终结果集;
最后把select子句中字段都带出来。
这一段也印证了前面关于 “#8,#9两步得到的结果集均为emp的子集” 的论断。
例四:
SQL:
EXPLAIN plan for select dept.* from hy_emp emp,hy_dept dept
where emp.deptno=dept.deptno and emp.ename='Andy' select * from table(dbms_xplan.display)
截图:
解读:
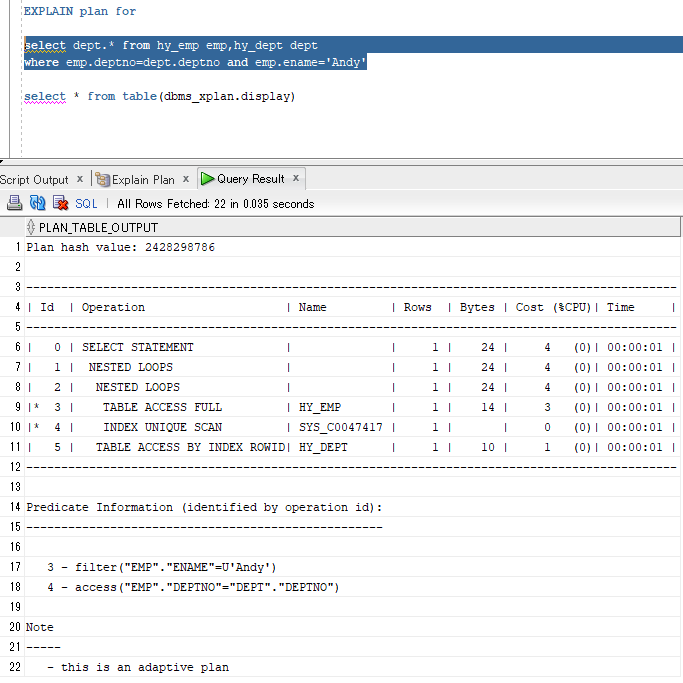
#9先执行,在emp表进行NAME=Andy的筛选,不要的数据丢弃(ENAME不是emp表的主键);
#10第二执行,在emp表查找DEPTNO能与DEPT表对应上的记录(直接去取ACCESS方式,因为DEPTNO是DEPT表的主键)
#8再执行,将#9,#10两步得到的结果集(均为emp的子集)进行嵌套循环连接;
由于select子句中需要dept表的字段,因此#8得到的结果集因为只是emp的子集不足以提供dept表的字段,还需要与dept表做一次连接;
#7执行,将#11得到的结果集(dept表的子集)与#8结果集进行嵌套循环连接;
最后带上select子句的字段。
例五:
SQL:
EXPLAIN plan for select count(*) from hy_emp emp,hy_dept dept
where emp.deptno=dept.deptno and emp.ename='Andy' select * from table(dbms_xplan.display)
截图:
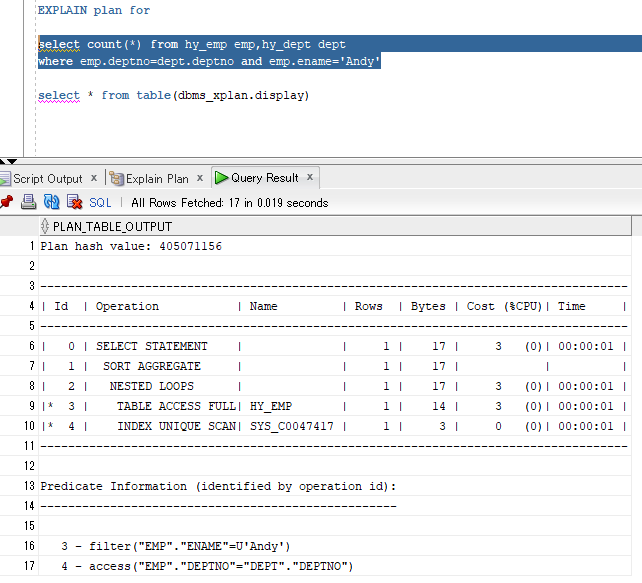
解读:
#9,#10,#8的分析和前面的同类语句类似;
因最终不需要dept表的数据,因此得到#8的结果集就够count(×)的统计了;
#7 的sort aggregate是排序聚合的意思,但这并非动作,而是代表语句类型,从cost看它也未产生消耗;
最后把select子句带出来就够了。
例六:
SQL:
EXPLAIN plan for select * from hy_emp emp,hy_dept dept
where emp.deptno=dept.deptno and emp.ename like '%in%'
order by emp.empno select * from table(dbms_xplan.display)
截图:
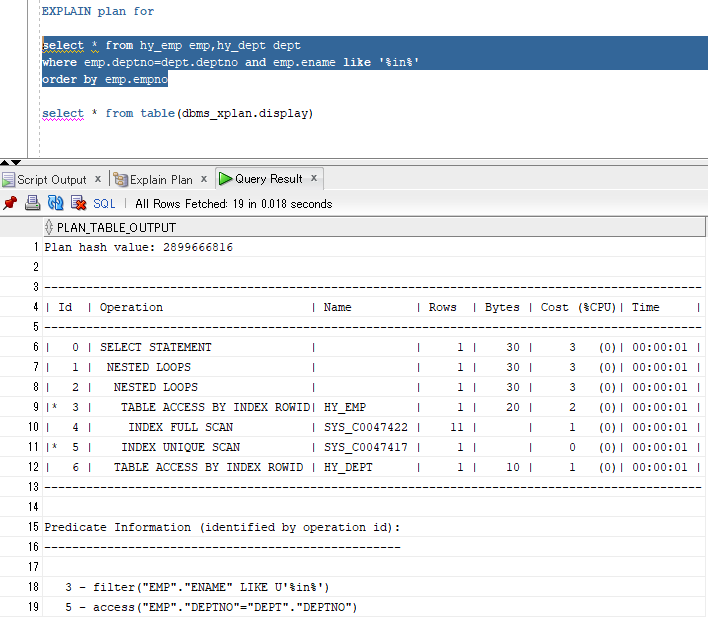
解读:
从缩进层次里来看,#10先执行,这一步走的是emp表的按empno排序(索引全扫描方式) ;
#9之后执行,在emp表进行NAME like ‘%in%’的筛选,不要的数据丢弃(ENAME不是emp表的主键);
#11再执行,在emp表查找DEPTNO能与DEPT表对应上的记录(直接去取数据(ACCESS方式),因为DEPTNO是DEPT表的主键)
#8再执行,将#9,#10两步得到的结果集(均为emp的子集)进行嵌套循环连接;
因为是select *,#8得到的结果集不足以成为最终结果集,它还要与dept表进行连接(从#8结果集找出deptno直接到dept中去找)
最后把select子句带出来。
附:以上SQL涉及到的表及其数据:
CREATE TABLE hy_emp
(
empno NUMBER(8,0) not null primary key,
ename NVARCHAR2(60) not null,
deptno NUMBER(8,0) not null,
sal NUMBER(10,0) DEFAULT 0 not null
) CREATE TABLE hy_dept
(
deptno NUMBER(8,0) not null primary key,
dname NVARCHAR2(60) not null
)
数据:
insert into hy_dept(deptno,dname) values('','Hr');
insert into hy_dept(deptno,dname) values('','Dev');
insert into hy_dept(deptno,dname) values('','Qa');
insert into hy_dept(deptno,dname) values('','Sales');
insert into hy_dept(deptno,dname) values('','Mng');
insert into hy_emp(empno,ename,deptno,sal) values('','Andy','',1000);
insert into hy_emp(empno,ename,deptno,sal) values('','Bill','',2000);
insert into hy_emp(empno,ename,deptno,sal) values('','Cindy','',3000);
insert into hy_emp(empno,ename,deptno,sal) values('','Douglas','',4000);
insert into hy_emp(empno,ename,deptno,sal) values('','Edinburg','',5000);
insert into hy_emp(empno,ename,deptno,sal) values('','Felix','',6000);
insert into hy_emp(empno,ename,deptno,sal) values('','Hellen','',7000);
insert into hy_emp(empno,ename,deptno,sal) values('','Isis','',8000);
insert into hy_emp(empno,ename,deptno,sal) values('','Jean','',9000);
insert into hy_emp(empno,ename,deptno,sal) values('','King','',10000);
insert into hy_emp(empno,ename,deptno,sal) values('','Mac','',11000);
--END-- 2019-12-31 13:47
Explain Plan试分析的更多相关文章
- 分析oracle的执行计划(explain plan)并对对sql进行优化实践
基于oracle的应用系统很多性能问题,是由应用系统sql性能低劣引起的,所以,sql的性能优化很重要,分析与优化sql的性能我们一般通过查看该sql的执行计划,本文就如何看懂执行计划,以及如何通过分 ...
- oracle用EXPLAIN PLAN 分析SQL语句
EXPLAIN PLAN 是一个很好的分析SQL语句的工具,它甚至可以在不执行SQL的情况下分析语句. 通过分析,我们就可以知道ORACLE是怎么样连接表,使用什么方式扫描表(索引扫描或全表扫描)以及 ...
- MySQL慢查询Explain Plan分析
Explain Plan 执行计划,包含了一个SELECT(后续版本支持UPDATE等语句)的执行 主要字段 id 编号,从1开始,执行的时候从大到小,相同编号从上到下依次执行. Select_typ ...
- 【转】Oracle 执行计划(Explain Plan) 说明
转自:http://blog.chinaunix.net/uid-21187846-id-3022916.html 如果要分析某条SQL的性能问题,通常我们要先看SQL的执行计划,看看SQ ...
- PLSQL_性能优化系列15_Oracle Explain Plan解析计划解读
2014-12-19 Created By BaoXinjian
- EXPLAIN PLAN获取SQL语句执行计划
一.获取SQL语句执行计划的方式 1. 使用explain plan 将执行计划加载到表plan_table,然后查询该表来获取预估的执行计划 2. 启用执行计划跟踪功能,即autotrace功能 3 ...
- Oracle 执行计划(Explain Plan)
如果要分析某条SQL的性能问题,通常我们要先看SQL的执行计划,看看SQL的每一步执行是否存在问题. 如果一条SQL平时执行的好好的,却有一天突然性能很差,如果排除了系统资源和阻塞的原因,那么基本可以 ...
- 优化器的使用oracle ---explain plan
如果要分析某条SQL的性能问题,通常我们要先看SQL的执行计划,看看SQL的每一步执行是否存在问题. 如果一条SQL平时执行的好好的,却有一天突然性能很差,如果排除了系统资源和阻塞的原因,那么基本可以 ...
- Oracle执行计划 explain plan
Rowid的概念:rowid是一个伪列,既然是伪列,那么这个列就不是用户定义,而是系统自己给加上的. 对每个表都有一个rowid的伪列,但是表中并不物理存储ROWID列的值.不过你可以像使用其它列那样 ...
随机推荐
- 6、单例模式 Singleton模式 只有一个实例 创建型模式
1.了解Singleton模式 程序在运行时,通常都会生成很多实例.例如,表示字符串的java . lang . string类的实例与字符串是- -对- -的关系,所以当有1000个字符串的时候,会 ...
- C#LeetCode刷题-双指针
双指针篇 # 题名 刷题 通过率 难度 3 无重复字符的最长子串 24.5% 中等 11 盛最多水的容器 43.5% 中等 15 三数之和 16.1% 中等 16 最接近的三数之和 3 ...
- Promise.then返回的是什么?
console.log((function cook(){ console.log('开始做饭.'); var p = new Promise(function(resolve, reject){ / ...
- [noip2002] 产生数
题目描述 给出一个整数 n (n<1030)和 k 个变换规则 (k < 15) . 规则: 一位数可变换成另一个一位数: 规则的右部不能为零. 例如:n = 234 .有规则( k=2 ...
- 【数论】莫比乌斯反演Mobius inversion
本文同步发布于作业部落,若想体验更佳,请点此查看原文.//博客园就是渣,连最基本的符号都打不出来.
- 1.MongoDB 2.7主从复制(master –> slave)环境基于时间点的恢复
(一)MongoDB恢复概述 对于任何类型的数据库,如果要将数据库恢复到过去的任意时间点,否需要有过去某个时间点的全备+全备之后的重做日志,MongoDB也不例外.使用全备将数据库恢复到固定时刻,然后 ...
- 使用CrashHandler获取应用crash信息
Android应用不可避免会发生crash,也称之为崩溃.发生原因可能是由于Android系统底层的bug,也可能是由于不充分的机型适配或者是糟糕的网络情况.当crash发生时,系统会kill掉正 ...
- Android Studio gridview 控件使用自定义Adapter, 九宫格items自适应全屏显示
先看效果图,类似于支付宝首页的效果.由于九宫格显示的帖子网上已经很多,但是像这样九宫格全屏显示的例子还不是太多.本实例的需求是九宫格全屏显示,每个子view的高度是根据全屏高度三等分之后自适应高度,每 ...
- Scala中的isInstanceOf和asInstanceOf区别
判断对象是否属于某个给定的类,可以用isInstanceOf方法:用asInstanceOf方法将引用转换为子类的引用. obj.isInstanceOf[T]就如同Java的obj instance ...
- neutron plugin 与 extension 编写流程
原文链接:neutron plugin 与 extension 编写流程 参考: 怎样写 OpenStack Neutron 的 Plugin (一)怎样写 OpenStack Neutron 的 P ...