机器学习:Python中如何使用支持向量机(SVM)算法
(简单介绍一下支持向量机,详细介绍尤其是算法过程可以查阅其他资)
在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别、分类(异常值检测)以及回归分析。
其具有以下特征:
(1)SVM可以表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值。而其他分类方法都采用一种基于贪心学习的策略来搜索假设空间,这种方法一般只能获得局部最优解。
(2) SVM通过最大化决策边界的边缘来实现控制模型的能力。尽管如此,用户必须提供其他参数,如使用核函数类型和引入松弛变量等。
from sklearn import svm
import numpy as np
import matplotlib.pyplot as plt #准备训练样本
x=[[1,8],[3,20],[1,15],[3,35],[5,35],[4,40],[7,80],[6,49]]
y=[1,1,-1,-1,1,-1,-1,1] ##开始训练
clf=svm.SVC() ##默认参数:kernel='rbf'
clf.fit(x,y) #print("预测...")
#res=clf.predict([[2,2]]) ##两个方括号表面传入的参数是矩阵而不是list ##根据训练出的模型绘制样本点
for i in x:
res=clf.predict(np.array(i).reshape(1, -1))
if res > 0:
plt.scatter(i[0],i[1],c='r',marker='*')
else :
plt.scatter(i[0],i[1],c='g',marker='*') ##生成随机实验数据(15行2列)
rdm_arr=np.random.randint(1, 15, size=(15,2))
##回执实验数据点
for i in rdm_arr:
res=clf.predict(np.array(i).reshape(1, -1))
if res > 0:
plt.scatter(i[0],i[1],c='r',marker='.')
else :
plt.scatter(i[0],i[1],c='g',marker='.')
##显示绘图结果
plt.show()
结果如下图:
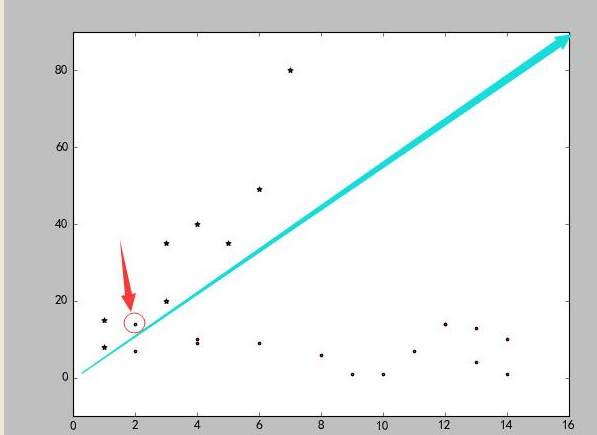
从图上可以看出,数据明显被蓝色分割线分成了两类。但是红色箭头标示的点例外,所以这也起到了检测异常值的作用。
2.在上面的代码中提到了kernel='rbf',这个参数是SVM的核心:核函数
重新整理后的代码如下:
from sklearn import svm
import numpy as np
import matplotlib.pyplot as plt ##设置子图数量
fig, axes = plt.subplots(nrows=2, ncols=2,figsize=(7,7))
ax0, ax1, ax2, ax3 = axes.flatten() #准备训练样本
x=[[1,8],[3,20],[1,15],[3,35],[5,35],[4,40],[7,80],[6,49]]
y=[1,1,-1,-1,1,-1,-1,1]
'''
说明1:
核函数(这里简单介绍了sklearn中svm的四个核函数,还有precomputed及自定义的) LinearSVC:主要用于线性可分的情形。参数少,速度快,对于一般数据,分类效果已经很理想
RBF:主要用于线性不可分的情形。参数多,分类结果非常依赖于参数
polynomial:多项式函数,degree 表示多项式的程度-----支持非线性分类
Sigmoid:在生物学中常见的S型的函数,也称为S型生长曲线 说明2:根据设置的参数不同,得出的分类结果及显示结果也会不同 '''
##设置子图的标题
titles = ['LinearSVC (linear kernel)',
'SVC with polynomial (degree 3) kernel',
'SVC with RBF kernel', ##这个是默认的
'SVC with Sigmoid kernel']
##生成随机试验数据(15行2列)
rdm_arr=np.random.randint(1, 15, size=(15,2)) def drawPoint(ax,clf,tn):
##绘制样本点
for i in x:
ax.set_title(titles[tn])
res=clf.predict(np.array(i).reshape(1, -1))
if res > 0:
ax.scatter(i[0],i[1],c='r',marker='*')
else :
ax.scatter(i[0],i[1],c='g',marker='*')
##绘制实验点
for i in rdm_arr:
res=clf.predict(np.array(i).reshape(1, -1))
if res > 0:
ax.scatter(i[0],i[1],c='r',marker='.')
else :
ax.scatter(i[0],i[1],c='g',marker='.') if __name__=="__main__":
##选择核函数
for n in range(0,4):
if n==0:
clf = svm.SVC(kernel='linear').fit(x, y)
drawPoint(ax0,clf,0)
elif n==1:
clf = svm.SVC(kernel='poly', degree=3).fit(x, y)
drawPoint(ax1,clf,1)
elif n==2:
clf= svm.SVC(kernel='rbf').fit(x, y)
drawPoint(ax2,clf,2)
else :
clf= svm.SVC(kernel='sigmoid').fit(x, y)
drawPoint(ax3,clf,3)
plt.show()
结果如图:
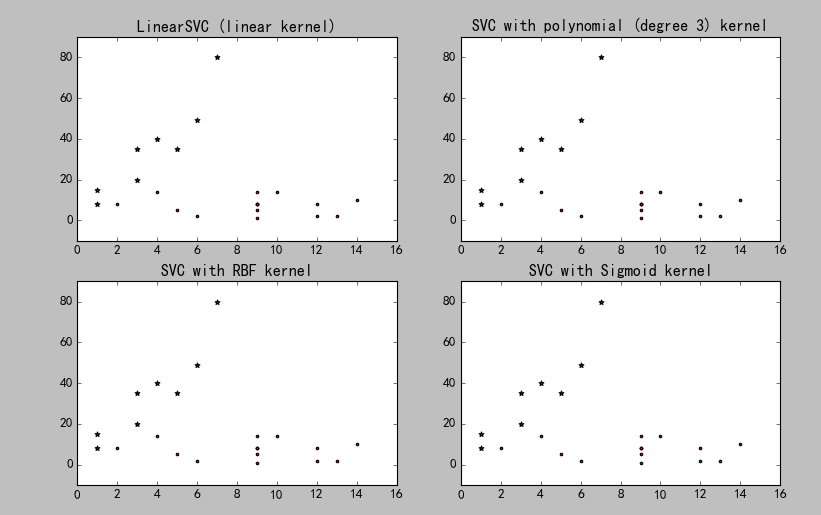
由于样本数据的关系,四个核函数得出的结果一致。在实际操作中,应该选择效果最好的核函数分析。
3.在svm模块中还有一个较为简单的线性分类函数:LinearSVC(),其不支持kernel参数,因为设计思想就是线性分类。如果确定数据
可以进行线性划分,可以选择此函数。跟kernel='linear'用法对比如下:
from sklearn import svm
import numpy as np
import matplotlib.pyplot as plt ##设置子图数量
fig, axes = plt.subplots(nrows=1, ncols=2,figsize=(7,7))
ax0, ax1 = axes.flatten() #准备训练样本
x=[[1,8],[3,20],[1,15],[3,35],[5,35],[4,40],[7,80],[6,49]]
y=[1,1,-1,-1,1,-1,-1,1] ##设置子图的标题
titles = ['SVC (linear kernel)',
'LinearSVC'] ##生成随机试验数据(15行2列)
rdm_arr=np.random.randint(1, 15, size=(15,2)) ##画图函数
def drawPoint(ax,clf,tn):
##绘制样本点
for i in x:
ax.set_title(titles[tn])
res=clf.predict(np.array(i).reshape(1, -1))
if res > 0:
ax.scatter(i[0],i[1],c='r',marker='*')
else :
ax.scatter(i[0],i[1],c='g',marker='*')
##绘制实验点
for i in rdm_arr:
res=clf.predict(np.array(i).reshape(1, -1))
if res > 0:
ax.scatter(i[0],i[1],c='r',marker='.')
else :
ax.scatter(i[0],i[1],c='g',marker='.') if __name__=="__main__":
##选择核函数
for n in range(0,2):
if n==0:
clf = svm.SVC(kernel='linear').fit(x, y)
drawPoint(ax0,clf,0)
else :
clf= svm.LinearSVC().fit(x, y)
drawPoint(ax1,clf,1)
plt.show()
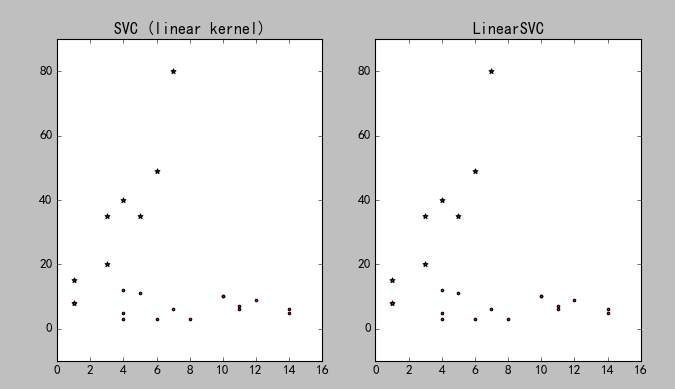
结果如图所示:
机器学习:Python中如何使用支持向量机(SVM)算法的更多相关文章
- 一步步教你轻松学支持向量机SVM算法之案例篇2
一步步教你轻松学支持向量机SVM算法之案例篇2 (白宁超 2018年10月22日10:09:07) 摘要:支持向量机即SVM(Support Vector Machine) ,是一种监督学习算法,属于 ...
- 一步步教你轻松学支持向量机SVM算法之理论篇1
一步步教你轻松学支持向量机SVM算法之理论篇1 (白宁超 2018年10月22日10:03:35) 摘要:支持向量机即SVM(Support Vector Machine) ,是一种监督学习算法,属于 ...
- 4、2支持向量机SVM算法实践
支持向量机SVM算法实践 利用Python构建一个完整的SVM分类器,包含SVM分类器的训练和利用SVM分类器对未知数据的分类, 一.训练SVM模型 首先构建SVM模型相关的类 class SVM: ...
- Spark机器学习系列之13: 支持向量机SVM
Spark 优缺点分析 以下翻译自Scikit. The advantages of support vector machines are: (1)Effective in high dimensi ...
- spark机器学习从0到1支持向量机SVM(五)
分类 分类旨在将项目分为不同类别. 最常见的分类类型是二元分类,其中有两类,通常分别为正数和负数. 如果有两个以上的类别,则称为多类分类. spark.mllib支持两种线性分类方法:线性支持 ...
- 吴恩达机器学习笔记(六) —— 支持向量机SVM
主要内容: 一.损失函数 二.决策边界 三.Kernel 四.使用SVM (有关SVM数学解释:机器学习笔记(八)震惊!支持向量机(SVM)居然是这种机) 一.损失函数 二.决策边界 对于: 当C非常 ...
- 机器学习(四):通俗理解支持向量机SVM及代码实践
上一篇文章我们介绍了使用逻辑回归来处理分类问题,本文我们讲一个更强大的分类模型.本文依旧侧重代码实践,你会发现我们解决问题的手段越来越丰富,问题处理起来越来越简单. 支持向量机(Support Vec ...
- python中的MRO和C3算法
一. 经典类和新式类 1.python多继承 在继承关系中,python子类自动用友父类中除了私有属性外的其他所有内容.python支持多继承.一个类可以拥有多个父类 2.python2和python ...
- 机器学习-Python中训练模型的保存和再使用
模型保存 BP:model.save(save_dir) SVM: from sklearn.externals import joblib joblib.dump(clf, save_dir) 模型 ...
随机推荐
- 解决 Windows instance 时间不同步问题 - 每天5分钟玩转 OpenStack(153)
这是 OpenStack 实施经验分享系列的第 3 篇. 问题描述 通过上一节部署出来的 Windows instance 有时候会发现操作系统时间总是慢 8 个小时,即使手工调整好时间和时区,下次 ...
- web移动端Fixed在Input获取焦点时ios下产生的BUG及处理
1.现象 可以看到下面两张图,图1搜索框为fixed固定在顶部,滚动没有任何问题. 图2当光标进入搜索框时,ios自作聪明的把光标定位到中间,并且fixed属性被自动修改成了absolute.此时注意 ...
- 《javascript个人理解,个人整理。》
万事开头难. 本人做前端工程师,已几年,没有特别大的,已文字方式去做总结. 前段时间,早已经想好,但是迟迟没有去下笔!好在现在陆陆续续的写下去. 我知道这是一个很大的工程,但是我还是想做下去,不为别的 ...
- jQuery_第四章_思维图
---------------------------------------------------------------------------------------------------- ...
- githup教程
http://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b000/瘳雪峰-Git教程http://w ...
- Python从入门到放弃之迭代器
迭代器是Python2.1中新加入的接口(PEP 234),说明如下: The iterator provides a 'get next value' operation that produces ...
- 【2017年新篇章】 .NET 面试题汇总(二)
本次给大家介绍的是我收集以及自己个人保存一些.NET面试题第二篇 第一篇文章请到这里:[2017年新篇章] .NET 面试题汇总(一) 简介 此次包含的不止是.NET知识,也包含少许前端知识以及.ne ...
- angular 2 animate 笔记
好久没有在这里写点笔记了.时隔已久,angular1 去 angular2 咯 笔记来源:https://angular.cn/docs/ts/latest/guide/animations.html ...
- Docker存储驱动之Btrfs简介
简介 Btrfs是下一代的copy-on-write文件系统,它支持很多高级特性,使其更加适合Docker.Btrfs合并在内核主线中,并且它的on-disk-format也逐渐稳定了.不过,它的很多 ...
- 禁止linux被ping
cho "net.ipv4.icmp_echo_ignore_all=1" >> /etc/sysctl.conf sysctl -p 生效 开启ping功能: 删除/ ...