Google的PageRank及其Map-reduce应用(日志五)
上一篇:Hadoop的安装(日志四)
1,算法的原理解释:
如下图所示,G就是传说中的谷歌矩阵,这个矩阵是n*n型号的,n表示共计有n个网页。
如矩阵中所示:
11位置处的元素,是表示第一个网页指向的第一个网页的比例值。
12元素,第二个网页指向第一个网页的比例值。
所谓的比例值,这个名称是我给取的,意思就是指向的链接占据所有链接的比例,例如,1网页指向了2,3,4网页,那么其1指向2网页的比例值就为1/3。
按照上面的原理,解析所有的链接,便得到了一个Google矩阵。
Google论文中有:
下面的公式之中α的取值范围是0在1之间任意取值,用于更加方便和精准的计算收敛的q。
至于q=Gq,由于G本身是一个矩阵,所以这个公式其实就是一个线性变换的过程。初始的时候,q可以取任意的值,例如(1,1,1,1,1),但需要注意的是,其维数,一定是要和网页个数相同的。不断对q进行线性变换,最终变换得到的q会收敛于q,而这个就是q表示最终排名的向量。
以上便是上面算法的所有原理解释。

2,例题(及其java实现):
1)A网页有链接指向B,C,D,E
2)B网页有链接指向A,D
3)C网页有链接指向A,D
4)D网页有链接指向C
5)E网页有链接指向A,C
A 请写出这个网页链接结构的Google矩阵
B 手动或编程计算这5个页面的PR值
Google矩阵:

代码实现:这个代码实现,是本人一步步探索出来的,给出的注释比较详细,应该好理解,但其中还所许多需要优化的地方,看上去依旧很low b,请不要见怪哈。
主要原理,就是利用二维数组实现矩阵的运算,搞定了这个,一切就简单。
package com.cgtz.main;
/**
* @author Administrator
*
*/public class HelloWorld {
public static void main(String[] args) {
//原始矩阵
double[][] sMatrix=new double[][]{
{0, 0.5, 0.5, 0, 0.5},
{0.25 , 0 , 0 , 0, 0},
{0.25 , 0 , 0 , 1, 0.5},
{0.25 , 0.5, 0.5 ,0 , 0},
{0.25 , 0 , 0 , 0 , 0}
};
//单位矩阵
double uMatrix[][]=new double[][]{
{1, 0, 0, 0, 0},
{0 , 1 , 0 , 0, 0},
{0 , 0 , 1 , 0, 0},
{0 , 0, 0 ,1 , 0},
{0 , 0 , 0 , 0 , 1}
};
double qMatrix[]=new double[]{
1,1,1,1,1
};
double gMatrix[][]=new double[5][5];
gMatrix=getGMatrix(sMatrix,uMatrix);
printMatrix(gMatrix);
double[] lastQMatrix=getLastQMatrix(gMatrix, qMatrix);
for (int i = 0; i < lastQMatrix.length; i++) {
System.out.println(lastQMatrix[i]);
}
}
//计数,可以调试时使用,也可以用来确定整个迭代的循环进行了多少次
static int count=0;
//整个方法,就是得出最后的排名向量,是一个核心的方法
private static double[] getLastQMatrix(double[][] gMatrix, double[] qMatrix) {
//每迭代一次,count的次数就加上一。
count+=1;
/**
创建一个临时的数组,次数组的的长度和需要线性变换的向量的长度相同,此数组可以当成数学中的一个向量。
整个temp向量的作用就是用来存放最原始的特征向量,以便与最终的向量进行比较
*/
double[] temp=new double[qMatrix.length];
//
for (int i = 0; i < temp.length; i++) {
temp[i]=qMatrix[i];
}
System.out.println("temp[1]---1:"+temp[0]);
/**
下面的嵌套的for循环,是用来q特征向量与G矩阵进行相乘,特征新的向量,需要说明的是,这里其实就是五维空间到五维空间的映射。
*/
for (int i = 0; i < gMatrix.length; i++) {
double newQ=0;
for (int j = 0; j < qMatrix.length; j++) {
double tempValue=gMatrix[i][j]*qMatrix[j];
System.out.println("tempValue:"+tempValue);
newQ+=tempValue;
}
qMatrix[i]=newQ;
System.out.println("----------------");
}
//打印出迭代一次之后得到新的排名向量
System.out.println("第"+count+"次迭代得到的矩阵。。。");
for (int s = 0; s < temp.length; s++) {
System.out.println("qMatrix---"+qMatrix[s]);
}
/**
下面的运算,是求两个向量之间的距离,
公式为:
*/
double distace=0;
double sDistance=0;
System.out.println("temp.length:"+temp.length);
System.out.println("temp[1]---2:"+temp[0]);
for (int i = 0; i < temp.length; i++) {
double x=temp[i]-qMatrix[i];
double x2=java.lang.StrictMath.pow(x,2);
sDistance+=x2;
}
distace=Math.sqrt(sDistance);
System.out.println("第"+count+"次迭代sDistance:"+sDistance);
//这里自己任意取一个合适的distance来确定多大距离时停止迭代
if(distace<0.0001){
for (int i = 0; i < temp.length; i++) {
System.out.println(qMatrix[i]);
}
return qMatrix;
}else{
getLastQMatrix(gMatrix,qMatrix);
}
return qMatrix;
}
public static void printMatrix(double[][] matrix){
for (int i = 0; i < matrix.length; i++) {
for (int j = 0; j < matrix.length; j++) {
System.out.print(matrix[i][j]+"--");
}
System.out.println();
}
}
private static double[][] getGMatrix(double[][] sMatrix, double[][] uMatrix) {
double gMatrix[][]=new double[5][5];
for(int i=0;i<sMatrix.length;i++){
for(int j=0;j<sMatrix.length;j++){
gMatrix[i][j]=(0.5)*sMatrix[i][j];
}
}
for(int i=0;i<uMatrix.length;i++){
for(int j=0;j<uMatrix.length;j++){
gMatrix[i][j]+=(0.5)*(0.2)*uMatrix[i][j];
}
}
return gMatrix; } }
计算的结果:
第14次迭代得到的矩阵。。。
qMatrix—2.8735992663233403E-5
qMatrix—4.620592012663504E-6
qMatrix—3.089895664396781E-5
qMatrix—1.604329405333448E-5
qMatrix—4.620592012663504E-6
由结果可知,c的网页的排名最高。
3,当网页数量较多的时候,就使用分布式计算的方案:
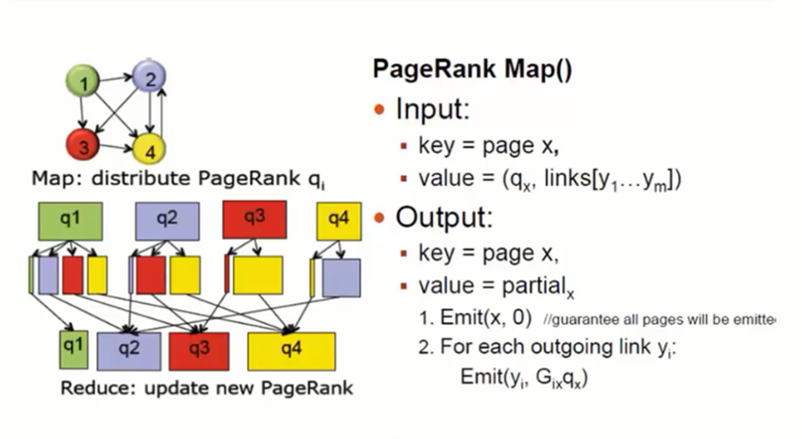
原理见下面的图片:
每个网页乘以对应的分向量,而后变得到了新的q,即为变换之后的q
4,Google的分词技术:
Google的PageRank及其Map-reduce应用(日志五)的更多相关文章
- Google的分布式计算模型Map Reduce map函数将输入分割成key/value对
http://www.nowamagic.net/librarys/veda/detail/1768 上一篇 大规模分布式数据处理平台Hadoop的介绍 中提到了Google的分布式计算模型Map R ...
- map reduce
作者:Coldwings链接:https://www.zhihu.com/question/29936822/answer/48586327来源:知乎著作权归作者所有,转载请联系作者获得授权. 简单的 ...
- 用通俗易懂的大白话讲解Map/Reduce原理
Hadoop简介 Hadoop就是一个实现了Google云计算系统的开源系统,包括并行计算模型Map/Reduce,分布式文件系统HDFS,以及分布式数据库Hbase,同时Hadoop的相关项目也很丰 ...
- 分布式基础学习(2)分布式计算系统(Map/Reduce)
二. 分布式计算(Map/Reduce) 分 布式式计算,同样是一个宽泛的概念,在这里,它狭义的指代,按Google Map/Reduce框架所设计的分布式框架.在Hadoop中,分布式文件 系统,很 ...
- Hadoop简介(1):什么是Map/Reduce
看这篇文章请出去跑两圈,然后泡一壶茶,边喝茶,边看,看完你就对hadoop整体有所了解了. Hadoop简介 Hadoop就是一个实现了Google云计算系统的开源系统,包括并行计算模型Map/Red ...
- 生动有趣地讲解Map/Reduce基本原理
Hadoop简介 Hadoop就是一个实现了Google云计算系统的开源系统,包括并行计算模型Map/Reduce,分布式文件系统HDFS,以及分布式数据库Hbase,同时Hadoop的相关项目也很丰 ...
- 分布式基础学习【二】 —— 分布式计算系统(Map/Reduce)
二. 分布式计算(Map/Reduce) 分布式式计算,同样是一个宽泛的概念,在这里,它狭义的指代,按Google Map/Reduce框架所设计的分布式框架.在Hadoop中,分布式文件系统,很大程 ...
- python基础——map/reduce
python基础——map/reduce Python内建了map()和reduce()函数. 如果你读过Google的那篇大名鼎鼎的论文“MapReduce: Simplified Data Pro ...
- hadoop入门级总结二:Map/Reduce
在上一篇博客:hadoop入门级总结一:HDFS中,简单的介绍了hadoop分布式文件系统HDFS的整体框架及文件写入读出机制.接下来,简要的总结一下hadoop的另外一大关键技术之一分布式计算框架: ...
随机推荐
- 分块编码(Transfer-Encoding: chunked)
参考链接: HTTP 协议中的 Transfer-Encoding 分块传输编码 一.背景: 持续连接的问题:对于非持续连接,浏览器可以通过连接是否关闭来界定请求或响应实体的边界:而对于持续连接,这种 ...
- 《Django By Example》第十二章 中文 翻译 (个人学习,渣翻)
书籍出处:https://www.packtpub.com/web-development/django-example 原作者:Antonio Melé (译者注:第十二章,全书最后一章,终于到这章 ...
- line-height属性总结
line-height属性的继承性: 子元素不设置line-height时, 在父元上设置带单位的值和百分比时会先计算父元素的line-height大小然后继承过来,在父元素上设置无单位的数值时,子 ...
- 各位Coder看过来
为了丰富博客内容,也为了解决一些实际的问题,现准备出一系列博文,内容为各位回复评论指明需要的知识点,将在近期为你解决并提供还算精要的讲解:评论内容要求 Coder:+需要的技术内容.技术内容不限领域, ...
- Myeclipse快捷键以及使用技巧大全-来自网络
1. 打开MyEclipse 6.0.1,然后"window"→"Preferences" 2. 选择"java",展开,"Edi ...
- MYSQL数据库导入大数据量sql文件失败的解决方案
1.在讨论这个问题之前首先介绍一下什么是"大数据量sql文件". 导出sql文件.选择数据库-----右击选择"转储SQL文件"-----选择"结构和 ...
- TCP基础知识 复习
前言 说来惭愧,大二时候学的计算机网络好多都不太记得了,不过还好有认真学过,捡起来也挺快的,就是对于现在业界中使用的网络算法的不是很懂: 1 TCP报文段结构 1.1 序号和确认号 序号,是报文段首字 ...
- Hbuilder开发移动App(1)
奇妙的前端,奇妙的js 众所周知,自从js有nodejs后,前端人员可以华丽的转身,去开发高并发非阻塞的服务端程序, 随着html5的出现,伴随一些amazing的特性,h5开发app的技术越发的成熟 ...
- 网站启用gzip压缩
gzip压缩启用不启用还是要看实际情况的,启用gzip后可以相应的减轻带宽压力但是同时也会增加cpu的压力(压缩解压),相反的如果不启用那么cpu压力也会相应的减少,具体情况具体分析. Linux开启 ...
- js原型二
function Box(name,age){ this.name = name; this.age = age; this.family = ['哥哥',‘姐姐’,‘妹妹’]: } Box.prot ...