SQL Server 2016 ->> T-SQL新特性
1) TRUNCATE表分区而不是整表
CREATE TABLE dbo.TruncatePartitionTest
(
PrtCol INT,
Col2 NVARCHAR(300)
)
ON [myPS1](PrtCol)
GO INSERT dbo.TruncatePartitionTest
VALUES(1,'AAA'), (11,'AAA'), (100,'AAA'), (101,'AAA')
GO -- TRUNCATE partitions 1 to 2
TRUNCATE TABLE dbo.TruncatePartitionTest
WITH (PARTITIONS(1 TO 2));
GO SELECT * FROM dbo.TruncatePartitionTest
GO TRUNCATE TABLE dbo.TruncatePartitionTest
GO INSERT dbo.TruncatePartitionTest
VALUES(1,'AAA'), (11,'AAA'), (100,'AAA'), (101,'AAA')
GO -- TRUNCATE partition 1
TRUNCATE TABLE dbo.TruncatePartitionTest
WITH (PARTITIONS(1));
GO SELECT * FROM dbo.TruncatePartitionTest
GO TRUNCATE TABLE dbo.TruncatePartitionTest
GO INSERT dbo.TruncatePartitionTest
VALUES(1,'AAA'), (11,'AAA'), (100,'AAA'), (101,'AAA')
GO -- TRUNCATE partitions 1 and 2
TRUNCATE TABLE dbo.TruncatePartitionTest
WITH (PARTITIONS(1,2));
GO SELECT * FROM dbo.TruncatePartitionTest
GO
2) 新的查询提示NO_PERFORMANCE_SPOOL
为了试验这个新的查询提示关键字,我对一个查询语句启用和不启用这个查询提示后的IO统计数据进行一个对比。
添加了NO_PERFORMANCE_SPOOL的语句和IO统计数据
SET STATISTICS IO ON
GO SELECT *
FROM [dbo].[vwPO]
WHERE PODATE BETWEEN '2012-01-01' AND '2014-01-31'
OPTION (NO_PERFORMANCE_SPOOL);
(5448 row(s) affected)
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Address'. Scan count 5, logical reads 49038, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'PurchaseOrder'. Scan count 5, logical reads 9267, physical reads 0, read-ahead reads 0, lob logical reads 17936, lob physical reads 0, lob read-ahead reads 0.
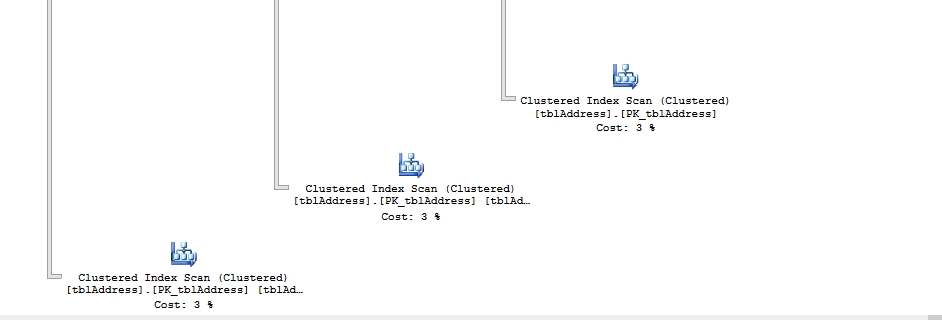
未添加查询提示
SET STATISTICS IO ON
GO SELECT *
FROM [dbo].[vwPO]
WHERE PODATE BETWEEN '2012-01-01' AND '2014-01-31';
(5448 row(s) affected)
Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 1, logical reads 24864, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'tblAddress'. Scan count 5, logical reads 15, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
lob read-ahead reads 0.
Table 'tblPurchaseOrder'. Scan count 5, logical reads 9267, physical reads 0, read-ahead reads 0, lob logical reads 17936, lob physical reads 0, lob read-ahead reads 0.
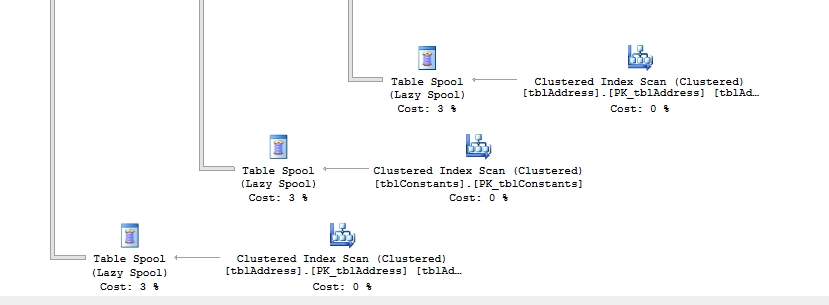
其实最后两者在时间上的差别基本没有,做法上的最大差别也显而易见且可想而知。SPOOL操作符的特点就是创建Work table来供后面的操作符使用。而既然禁用了SPOOL操作符也就意味着不使用Work table,这样上面的IO Statistics结果也反映了这一点。但是并不意味着这是好事。不使用work table意味着后面每次都需要扫描表,这种开销也蛮大的。这个例子里面因为涉及扫描的表小所以差异微乎其微。在我看来,这个功能在现实中的使用场景很少见。只能说有比没有好。本来执行计划的东西非不得已都是让SQL SERVER自己决定。微软宣称这个查询提示可以大大改善高并发场景下使用了SPOOL的查询语句性能。这点我承认。但是,在我看来,这是属于治标不治本的做法。一般使用到SPOOL的语句,很大可能是因为没有适用的索引,所以根本原因很可能是缺乏可用的索引。其次,适用了这个提示可能导致过多的表扫描,性能上未必有提升。真正应该考虑的是审查语句是否存在改写的可能性来降低复杂性从而改变执行计划使得预建的索引得以使用最终获得最优的执行计划,以及是否需要stage数据来解决高并发问题。
3) DROP IF EXISTS 语句
以前要DROP某张表某个存储过程总是需要IF EXISTS(SELECT * FROM sys.objects WHERE name = '' AND .....),现在终于有更加简洁的做法来实现。
DROP <TABLE|PROCEDURE|VIEW|FUNCTION|TRIGGER> IF EXISTS <name>
它可以作用于下面这些数据库对象
|
AGGREGATE |
PROCEDURE |
TABLE |
|
ASSEMBLY |
ROLE |
TRIGGER |
|
VIEW |
RULE |
TYPE |
|
DATABASE |
SCHEMA |
USER |
|
DEFAULT |
SECURITY POLICY |
VIEW |
|
FUNCTION |
SEQUENCE |
|
|
INDEX |
SYNONYM |
4) 在使用DBCC CHECKTABLE和DBCC CHECKDB这种语句的时候可以使用MAXDOP语句来避免对系统性能造成过多的影响,因为如果有业务关键作业正在工作,而服务器的处理器核心数不多,DBCC CHECKTABLE容易导致频繁的上下文切换。
5)可以使用sp_set_session_context 来设置会话级别的上下文以及使用SESSION_CONTEXT来查看某个会话级别主键的上下文内容。
EXEC sp_set_session_context 'user_id', 4;
SELECT SESSION_CONTEXT(N'user_id');
6)sp_execute_external_script 存储过程支持在SQL SERVER 2016中执行R语言脚本以及通过CREATE EXTERNAL RESOURCE POOL来为R语言创建资源池
7)COMPRESS和DECOMPRESS函数可以使用GZIP压缩算法压缩字符串和使用ZIP算法解压缩字符串
8)新的函数DATEDIFF_BIGINT和DATEDIFF作用是一样,不过区别是返回值是BIGINT,这样在处理millisecond这样的情况是就可以支持更长的时间差。新的函数AT TIME ZONE则可以输出带有时区的datetimeoffset。
SELECT getdate() AT TIME ZONE 'China Standard Time'; -- from select * from sys.time_zone_info
9)两个新的字符串函数 STRING_SPLIT和 STRING_ESCAPE。前者是个表函数,输入text和分隔符就可以分割字符串变成表返回。问题是分隔符只支持1个字符长度的字符。而后者是为了帮助json格式的数据转义特殊字符,比如斜杠。
10)新的数据库选项MIXED_PAGE_ALLOCATION 可以指定数据库是否默认情况下是否首先对索引分配混合分区,SQL SERVER 2016以前的版本某人情况下是分配混合分区先。
SQL Server 2016 ->> T-SQL新特性的更多相关文章
- Sql Server 2016新功能之 Row-Level Security
Sql Server 2016 有一个新功能叫 Row-Level Security ,大概意思是行版本的安全策略(原来我是个英语渣_(:з」∠)_) 直接上例子.这个功能相当通过对表添加一个函数作为 ...
- 数据库技术丛书:SQL Server 2016 从入门到实战(视频教学版) PDF
1:书籍下载方式: SQL Server2016从入门到实战 PDF 下载 链接:https://pan.baidu.com/s/1sWZjdud4RosPyg8sUBaqsQ 密码:8z7w 学习 ...
- SQL Server 2016 Failover Cluster + ALwaysOn
SQL Server 2016 Failover Cluster + ALwaysOn 环境的搭建 近期公司为了提高服务的可用性,就想到了部署AlwaysOn,之前的环境只是部署了SQL Server ...
- SQL Server 2016白皮书
随着SQL Server 2016正式版发布日临近,相关主要特性通过以下预览学习: Introducing Microsoft SQL Server 2016 e-bookSQL Server 201 ...
- SQL Server ->> 深入探讨SQL Server 2016新特性之 --- Temporal Table(历史表)
原文:SQL Server ->> 深入探讨SQL Server 2016新特性之 --- Temporal Table(历史表) 作为SQL Server 2016(CTP3.x)的另一 ...
- SQL Server 2016新特性:列存储索引新特性
SQL Server 2016新特性:列存储索引新特性 行存储表可以有一个可更新的列存储索引,之前非聚集的列存储索引是只读的. 非聚集的列存储索引支持筛选条件. 在内存优化表中可以有一个列存储索引,可 ...
- SQL Server 2016最值得关注的10大新特性
全程加密技术(Always Encrypted) 全程加密技术(Always Encrypted)支持在SQL Server中保持数据加密,只有调用SQL Server的应用才能访问加密数据.该功能支 ...
- SQL Server ->> 深入探讨SQL Server 2016新特性之 --- Row-Level Security(行级别安全控制)
SQL Server 2016 CPT3中包含了一个新特性叫Row Level Security(RLS),允许数据库管理员根据业务需要依据客户端执行脚本的一些特性控制客户端能够访问的数据行,比如,我 ...
- SQL Server 2016新特性:DROP IF EXISTS
原文:SQL Server 2016新特性:DROP IF EXISTS 在我们写T-SQL要删除某个对象(表.存储过程等)时,一般会习惯先用IF语句判断该对象是否存在,然后DROP,比如: 旧 ...
- SQL Server 2016新特性:Live Query Statistics
SSMS可以提供可以查看正在执行的计划.live query plan可以查看一个查询的执行过程,从一个查询计划操作到另外一个查询计划操作.live query plan提供了整体的查询运行进度和操作 ...
随机推荐
- 初学SSM遇到的BUG
一.SpringMVC部分 1.参数绑定 1.1简单类型绑定 参数类型推荐使用包装数据类型,因为基础数据类型不可以为null 整形:Integer.int 字符串:String 单精度:Float.f ...
- CSS生成小三角
前言:小三角的应用场景:鼠标移动到某个按钮上面,查看信息详情时,信息详情弹出框有时候会需要一个小三角. 代码如下: <div id='triangle'></div> #tri ...
- jquery 部分函数源码解析
JSON.stringify源码(在看extend文档的时候看到) var object1 = { apple: 0, banana: {weight: 52, price: 100}, cherry ...
- wDatepicker97的用法(点击事件联动)
1.在使用wdatepicker的时候用户需要选中然后联动其他的下拉,看了插件的文档,研究了一下 <input type="text" id="date" ...
- Android使用7牛云存储
第一次使用这个云存储,话说7牛云存储大有来头!区别于国内外其他云存储,七牛自行研发的全分布式架构解决了其他云存储单一数据中心架构可能存在的风险,同时首创双向加速特性对数据上传下载均加速,使得数据访问速 ...
- 【c++】访问控制
1. 类内的访问控制 在基类中,public和private具有普通的含义:用户(即基类的对象)可以访问public成员(包括函数.数据),而不能访问private成员.private只能被基类的成 ...
- Codeforces 494E. Sharti
Description 有一个 \(n*n\) 的矩形,给出 \(m\) 个子矩形,这些矩形内部的点都是白色的,其余的点都是黑色,每一次你可以选择一个变长不超过 \(k\) 的正方形,满足这个正方形的 ...
- php根据IP获取所在省份-百度api接口
这里用的file_put_contents,你也可以用别的,直接怼代码: //拼接传递的参数 $getData = array( 'query' => '127.0.0.1', 'resourc ...
- [转].NET Core dotnet 命令大全
本文转自:http://www.cnblogs.com/linezero/p/dotnet.html https://docs.microsoft.com/en-us/dotnet/articles/ ...
- java 的数据库操作--JDBC
一.java与数据库的交互 1.jdbc:java data base connectivity,java数据库连接.java的JDBC操作主要通过操作两个类进行连接操作:Connection 和 S ...