FutureTask、Fork/Join、 BlockingQueue
import lombok.extern.slf4j.Slf4j; import java.util.concurrent.Callable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future; @Slf4j
public class FutureExample { static class MyCallable implements Callable<String> { @Override
public String call() throws Exception {
log.info("do something in callable");
Thread.sleep();
return "Done";
}
} public static void main(String[] args) throws Exception {
ExecutorService executorService = Executors.newCachedThreadPool();
Future<String> future = executorService.submit(new MyCallable());
log.info("do something in main");
//Thread.sleep(10000);
log.info("这里不阻塞,可以继续异步执行");
String result = future.get(); //get方法会发生阻塞,如果判断任务是否执行完成使用isDone()方法
log.info("result:{}", result);
}
}
FutureTask
import lombok.extern.slf4j.Slf4j; import java.util.concurrent.Callable;
import java.util.concurrent.FutureTask; @Slf4j
public class FutureTaskExample { public static void main(String[] args) throws Exception {
FutureTask<String> futureTask = new FutureTask<String>(new Callable<String>() {
@Override
public String call() throws Exception {
log.info("do something in callable");
Thread.sleep();
return "Done";
}
}); new Thread(futureTask).start();
log.info("do something in main");
Thread.sleep();
String result = futureTask.get();
log.info("result:{}", result);
}
}
Fork/Join
用于并行执行任务的框架,将大任务分割成小任务,最终将每个小任务的结果汇总得到大任务结果的框架。
思想和map/reduce非常像,Fork就是讲大任务分割成小任务,Join就是合并子任务的结果。
工作窃取算法
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。工作窃取的运行流程图如下:
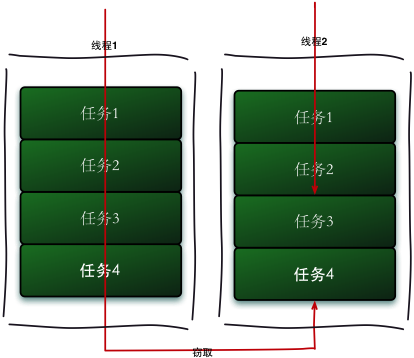
那么为什么需要使用工作窃取算法呢?假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
Fork/Join使用两个类来完成以上两件事情:
ForkJoinPool :它负责实现,包括我们的工作窃取算法,它管理工作线程和任务状态以及执行信息
ForkJoinTask:主要提供fork和join的机制
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask; @Slf4j
public class ForkJoinTaskExample extends RecursiveTask<Integer> { public static final int threshold = ;
private int start;
private int end; public ForkJoinTaskExample(int start, int end) {
this.start = start;
this.end = end;
} @Override
protected Integer compute() {
int sum = ; //如果任务足够小就计算任务
boolean canCompute = (end - start) <= threshold;
if (canCompute) {
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
// 如果任务大于阈值,就分裂成两个子任务计算
int middle = (start + end) / ;
ForkJoinTaskExample leftTask = new ForkJoinTaskExample(start, middle);
ForkJoinTaskExample rightTask = new ForkJoinTaskExample(middle + , end); // 执行子任务
leftTask.fork();
rightTask.fork(); // 等待任务执行结束合并其结果
int leftResult = leftTask.join();
int rightResult = rightTask.join(); // 合并子任务
sum = leftResult + rightResult;
}
return sum;
} public static void main(String[] args) {
ForkJoinPool forkjoinPool = new ForkJoinPool(); //生成一个计算任务,计算1+2+3+4
ForkJoinTaskExample task = new ForkJoinTaskExample(, ); //执行一个任务
Future<Integer> result = forkjoinPool.submit(task); try {
log.info("result:{}", result.get());
} catch (Exception e) {
log.error("exception", e);
}
}
}
BlockingQueue
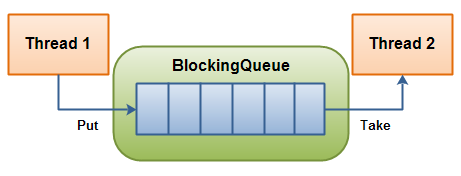
BlockingQueue是一种数据结构,支持一个线程往里存资源,另一个线程从里取资源。这正是解决生产者消费者问题所需要的
下面两幅图演示了BlockingQueue的两个常见阻塞场景:


如上图所示:当队列中填满数据的情况下,生产者端的所有线程都会被自动阻塞(挂起),直到队列中有空的位置,线程被自动唤醒。


1. ArrayBlockingQueue
基于数组的阻塞队列实现,在ArrayBlockingQueue内部,维护了一个定长数组,以便缓存队列中的数据对象,这是一个常用的阻塞队列,除了一个定长数组外,ArrayBlockingQueue内部还保存着两个整形变量,分别标识着队列的头部和尾部在数组中的位置。
ArrayBlockingQueue在生产者放入数据和消费者获取数据,都是共用同一个锁对象,由此也意味着两者无法真正并行运行,这点尤其不同于LinkedBlockingQueue
2. LinkedBlockingQueue
基于链表的阻塞队列,同ArrayListBlockingQueue类似,其内部也维持着一个数据缓冲队列(该队列由一个链表构成),当生产者往队列中放入一个数据时,队列会从生产者手中获取数据,并缓存在队列内部,而生产者立即返回;只有当队列缓冲区达到最大值缓存容量时(LinkedBlockingQueue可以通过构造函数指定该值),才会阻塞生产者队列,直到消费者从队列中消费掉一份数据,生产者线程会被唤醒,反之对于消费者这端的处理也基于同样的原理。而LinkedBlockingQueue之所以能够高效的处理并发数据,还因为其对于生产者端和消费者端分别采用了独立的锁来控制数据同步,这也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
作为开发者,我们需要注意的是,如果构造一个LinkedBlockingQueue对象,而没有指定其容量大小,LinkedBlockingQueue会默认一个类似无限大小的容量(Integer.MAX_VALUE),这样的话,如果生产者的速度一旦大于消费者的速度,也许还没有等到队列满阻塞产生,系统内存就有可能已被消耗殆尽了。
ArrayBlockingQueue和LinkedBlockingQueue是两个最普通也是最常用的阻塞队列,一般情况下,在处理多线程间的生产者消费者问题,使用这两个类足以。
使用阻塞队列解决生产者-消费者问题
FutureTask、Fork/Join、 BlockingQueue的更多相关文章
- 一文带你了解J.U.C的FutureTask、Fork/Join框架和BlockingQueue
摘要: J.U.C是Java并发编程中非常重要的工具包,今天,我们就来着重讲讲J.U.C里面的FutureTask.Fork/Join框架和BlockingQueue. 本文分享自华为云社区<[ ...
- 【转】mysql的union、left join、 right join、 inner join和视图学习
1.联合 union 进行多个查询语句时,要求多次查询的结果列数必须一样.此时,查询的结果以第一个sql语句的列名为准且union会自动去重复我们应该使用union all. 例...... 1.联合 ...
- sql之left join、right join、inner join的区别
sql之left join.right join.inner join的区别 left join(左联接) 返回包括左表中的所有记录和右表中联结字段相等的记录 right join(右联接) 返回包括 ...
- SQL表连接查询(inner join、full join、left join、right join)
SQL表连接查询(inner join.full join.left join.right join) 前提条件:假设有两个表,一个是学生表,一个是学生成绩表. 表的数据有: 一.内连接-inner ...
- SQL的inner join、left join、right join、full outer join、union、union all
主题: SQL的inner join.left join.right join.full outer join.union.union all的学习. Table A和Table B表如下所示: 表A ...
- mysql not in、left join、IS NULL、NOT EXISTS 效率问题记录
原文:mysql not in.left join.IS NULL.NOT EXISTS 效率问题记录 mysql not in.left join.IS NULL.NOT EXISTS 效率问题记录 ...
- inner join、left join、right join中where和and的作用
inner join.left join.right join中where和and的作用 .内连接(自然连接): 只有两个表相匹配的行才能在结果集中出现 2.外连接: 包括 (1)左外连接 (左边的 ...
- sql的left join 、right join 、inner join之间的区别
sql中left join .right join .inner join之间的区别 left join (左联接) 返回包括左表中的所有记录和右表中联结字段相等的记录 : right join (右 ...
- SQL中关于Join、Inner Join、Left Join、Right Join、Full Join、On、 Where区别
前言: 今天主要的内容是要讲解SQL中关于Join.Inner Join.Left Join.Right Join.Full Join.On. Where区别和用法,不用我说其实前面的这些基本SQL语 ...
随机推荐
- Html就是超文本标记语言的简写,是最基础的网页语言
Html就是超文本标记语言的简写,是最基础的网页语言. Html是通过标签来定义的语言,代码都是由标签所组成. Html代码不用区分大小写. Html代码由<html>开始</htm ...
- (转)java位运算
转自:http://aijuans.iteye.com/blog/1850655 Java 位运算(移位.位与.或.异或.非) public class Test { public static ...
- oracle锁一些知识
表级锁共具有五种模式,如下所示. 行级排他锁(Row Exclusive,简称RX锁) 当我们进行DML时会自动在被更新的表上添加RX锁,或者也可以通过执行lock命令显式的在表上添加RX锁.在该锁定 ...
- 【微信小游戏】文件系统,远程加载资源打破4M限制
一.前提 微信小游戏,对游戏包体的大小有严格是限制,上传文件大小<4M,但是本地缓存文件有50M空间,也就是说我们可以将一些资源放到网上,然后缓存到本地. 二.官方概念 文件系统 文件系统是小程 ...
- poj 3204(最小割)
题目链接:http://poj.org/problem?id=3204 思路:显然只有增大那最小割边集上的边才能增加最大流,因此,我们可以先跑一遍最大流,然后对于那些满足条件的边u->v,当且仅 ...
- 面试题思考:BS与CS的区别与联系
简单的理解: bs是浏览器(browser)和服务器(server) cs是静态客户端程序(client)和服务器(server) 区别在于,虽然同样是通过一个程序连接到服务器进行网络通讯,但是bs结 ...
- thrift框架总结,可伸缩的跨语言服务开发框架
thrift框架总结,可伸缩的跨语言服务开发框架 前言: 目前流行的服务调用方式有很多种,例如基于 SOAP 消息格式的 Web Service,基于 JSON 消息格式的 RESTful 服务等.其 ...
- 大数据技术大合集:Hadoop家族、Cloudera系列、spark、storm【转】
大数据我们都知道hadoop,可是还会各种各样的技术进入我们的视野:Spark,Storm,impala,让我们都反映不过来.为了能够更好 的架构大数据项目,这里整理一下,供技术人员,项目经理,架构师 ...
- poj1699(状态压缩dp)
可能没有完全读懂题意. 个人觉得 acca aa 答案应该是4. 然后就是dp了..这题数据量小很多方法都可以,数据也水暴力据说都能过.. 还有就是我竟然没有用扩展kmp优化下... 太无耻了,我是因 ...
- 转!!ftp的主动模式(port)与被动模式(PASV)
转自 http://www.phpweblog.net/killjin/archive/2008/01/06/2653.html ftp中主动模式(port)与被动模式(PASV) 目录 开场白 ...