JDK1.7 ConcurrentHashMap 源码浅析
概述
ConcurrentHashMap是HashMap的线程安全版本,使用了分段加锁的方案,在高并发时有比较好的性能。
本文分析JDK1.7中ConcurrentHashMap的实现。
正文
ConcurrentHashMap概述
HashMap不是线程安全的,要实现线程安全除非加锁,但这样性能很低。ConcurrentHashMap把整个HashMap数组分成了若干个Segment,每个Segment里有一个数组。添加一个Key时,需要先根据hash值计算出其所在Segment,然后再根据hash值计算出在该Segment中的位置。Segment继承自ReentrantLock,每个Segment就是一个锁。在多线程的情况下,就减少了锁竞争,提升了性能。
ConcurrentHashMap存储结构如下图所示:
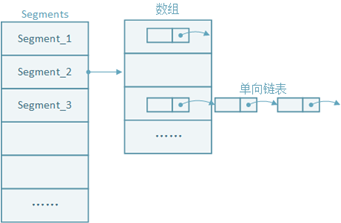
下面我们来分析源码,看数据是怎么存储的。
构造函数
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// Find power-of-two sizes best matching arguments
int sshift = 0;
int ssize = 1;
//concurrencyLevel为并发级别,这一步就是计算出大于concurrencyLevel的最小的2的N次方
//为什么不用HashMap中的Integer.highestOneBit((number - 1) << 1)来计算这个值
//我的理解是concurrencyLevel一般都比较小(默认为16),采用这种计算方法效率更高。
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
//后面根据hash计算segment位置时需要用到
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//计算每一个segment中table的length
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// create segments and segments[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
和HashMap最大的不同就是多了Segment的初始化。
Segment的Size也初始化为2的N次方,这为后面的Map整体resize以及确定一个hash值所在Segment都提供简便方法。
每个Segment中的table同HashMap中table一样,接着来看PUT时怎么计算Segment的位置。
PUT
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
//取得Key的Segment位置
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
segmentShift:在构造函数中计算出来的,假设concurrencyLevel为16,segmentShift=28(32-4)
segmentMask:15(16-1)
可见求Key所在Segment的算法和HashMap中求Key所在table中的位置一样,都是 hash & (length-1)。
所以这里Segment的length也必须是2的N次方。
hash >>> segmentShift是为了使用hash的高位进行与运算。
s.put方法,就是把Key放到Segment中table的响应位置,它的算法和HashMap中类似,只是加入了锁。
线程安全
HashMap - 非线程安全
Put一个Key时有下面这段代码:
void createEntry(int hash, K key, V value, int bucketIndex) {
//1.取得链表
Entry<K,V> e = table[bucketIndex];
//2.将新Key设置为链表的第一个
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
假设有两个线程A、B,同时进行第1步,它们获取到的e是同一个,如:x,y,z
然后线程A运行到第2步,为e添加了一个新元素a,并赋值给table[bucketIndex],此时table[bucketIndex]为:a,x,y,z
而后线程B运行到第2步,为e添加了一个新元素b,并赋值给table[bucketIndex],此时table[bucketIndex]为:b,x,y,z
所以这种情况下就会有问题,这只是其中的一个例子,所以HashMap是非线程安全的。
ConcurrentHashMap - 线程安全
Put一个Key到Table时,使用如下代码:
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
......
} finally {
unlock();
}
return oldValue;
}
可以看到put时,加入了Lock,这就保证了线程的安全性。
查看ConcurrentHashMap源代码可以发现,ConcurrentHashMap的remove、replace等有可能引起线程安全问题的地方都加了Lock。
ConcurrentHashMap的Get方法并不是完全线程安全,因为Get时没有加锁,但JDK用了很多volatile类型变量来保证在大多数情况下的线程安全。
具体怎么线程不安全,参考:深入剖析ConcurrentHashMap
总结:
ConcurrentHashMap在绝大多数情况下是线程安全的,在多线程情况下请使用ConcurrentHashMap。
参考:
1. Java 8系列之重新认识HashMap http://tech.meituan.com/java-hashmap.html
2. 深入剖析ConcurrentHashMap http://ifeve.com/java-concurrent-hashmap-2
3. jdk8之ConcurrentHashMap源码解析 http://jahu.iteye.com/blog/2331191
JDK1.7 ConcurrentHashMap 源码浅析的更多相关文章
- java并发:jdk1.8中ConcurrentHashMap源码浅析
ConcurrentHashMap是线程安全的.可以在多线程中对ConcurrentHashMap进行操作. 在jdk1.7中,使用的是锁分段技术Segment.数据结构是数组+链表. 对比jdk1. ...
- JDK1.8 ConcurrentHashMap源码阅读
1. 带着问题去阅读 为什么说ConcurrentHashMap是线程安全的?或者说 ConcurrentHashMap是如何防止并发的? 2. 字段和常量 首先,来看一下ConcurrentHa ...
- jdk1.7 ArrayList源码浅析
参考:http://www.cnblogs.com/xrq730/p/4989451.html(借鉴的有点多,哈哈) 首先介绍ArrayList的特性: 1.允许元素为空.允许重复元素 2.有序,即插 ...
- spring源码浅析——IOC
=========================================== 原文链接: spring源码浅析--IOC 转载请注明出处! ======================= ...
- Hashtable、ConcurrentHashMap源码分析
Hashtable.ConcurrentHashMap源码分析 为什么把这两个数据结构对比分析呢,相信大家都明白.首先二者都是线程安全的,但是二者保证线程安全的方式却是不同的.废话不多说了,从源码的角 ...
- ConcurrentHashMap源码阅读
1. 前言 HashMap是非线程安全的,在多线程访问时没有同步机制,并发场景下put操作可能导致同一数组下的链表形成闭环,get时候出现死循环,导致CPU利用率接近100%. HashTable是线 ...
- Android源码浅析(二)——Ubuntu Root,Git,VMware Tools,安装输入法,主题美化,Dock,安装JDK和配置环境
Android源码浅析(二)--Ubuntu Root,Git,VMware Tools,安装输入法,主题美化,Dock,安装JDK和配置环境 接着上篇,上片主要是介绍了一些安装工具的小知识点Andr ...
- JDK12 concurrenthashmap源码阅读
本文部分照片和代码分析来自文末参考资料 java8中的concurrenthashmap的方法逻辑和注解有些问题,建议看最新的JDK版本 建议阅读 concu ...
- CountDownLatch源码浅析
Cmd Markdown链接 CountDownLatch源码浅析 参考好文: JDK1.8源码分析之CountDownLatch(五) Java并发之CountDownLatch源码分析 Count ...
随机推荐
- android anr分析方法
目录(?)[+] 案例1关键词ContentResolver in AsyncTask onPostExecute high iowait 案例2关键词在UI线程进行网络数据的读写 一:什么是AN ...
- autofac 初步学习
//数据处理接口 public interface IDal<T> where T : class { void Insert (T model); void Update(T model ...
- C# ServiceStack.Redis 操作对象List
class Car { public Int32 Id { get; set; } public String Name { get; set; } static void Main(string[] ...
- 如何做一名好的web安全工程师?
在网络安全行业里面,web安全方向的人相对来说算是占大头,因为web安全初学阶段不像系统底层安全那么枯燥,而且成功hack目标网站的成就感相对也是比较强的. web安全工程师这个职位在甲方和乙方公司都 ...
- CSS打造经典鼠标触发显示选项
650) this.width=650;" border="0" alt="" src="http://img1.51cto.com/att ...
- Linux shell的标准输入、输出和错误
编译文件时,若编译过程时间长,可以将 标准错误 重定向 输出到一个文件中 2 > 1.txt 也可以通过管道 重定向 到 标准输出 2 > &1 ...
- Css transition
CSS的transition允许CSS的属性值在一定的时间区间内平滑地过渡.这种效果可以在鼠标单击.获得焦点.被点击或对元素任何改变中触发,并圆滑地以动画效果改变CSS的属性值. <!DOCTY ...
- [转] Android PhoneGap Cordova 体系结构
说明: 本文档只针对Cordova(PhoneGap)的Android端,基于Cordova2.1.0版本. 一.总体结构 Cordova的目标是用HTML,JS,来完成手机客户端的开发,并且是只开发 ...
- alipay iOS SDK
我也是醉了,进支付宝主页找都找不到,好不容易找到赶紧记下来:https://b.alipay.com/order/productDetail.htm?productId=201308060460965 ...
- 机器学习公开课笔记(3):Logistic回归
Logistic 回归 通常是二元分类器(也可以用于多元分类),例如以下的分类问题 Email: spam / not spam Tumor: Malignant / benign 假设 (Hypot ...