Solr4.8.0源码分析(20)之SolrCloud的Recovery策略(一)
Solr4.8.0源码分析(20)之SolrCloud的Recovery策略(一)
题记:
我们在使用SolrCloud中会经常发现会有备份的shard出现状态Recoverying,这就表明SolrCloud的数据存在着不一致性,需要进行Recovery,这个时候的SolrCloud建索引是不会写入索引文件中的(每个shard接受到update后写入自己的ulog中)。关于Recovery的内容包含三篇,本文是第一篇介绍Recovery的原因以及总体流程。
1. Recovery的起因
Recovery一般发生在以下三个时候:
- SolrCloud启动的时候,主要由于在建索引的时候发生意外关闭,导致一些shard的数据与leader不一致,那么在启动的时候刚起的shard就会从leader那里同步数据。
- SolrCloud在进行leader选举中出现错误,一般出现在leader宕机引起replica进行选举成leader过程中。
- SolrCloud在进行update时候,由于某种原因leader转发update至replica没有成功,会迫使replica进行recoverying进行数据同步。
前面两种情况暂时不介绍,本文先介绍下第三种情况。大致原理如下图所示:
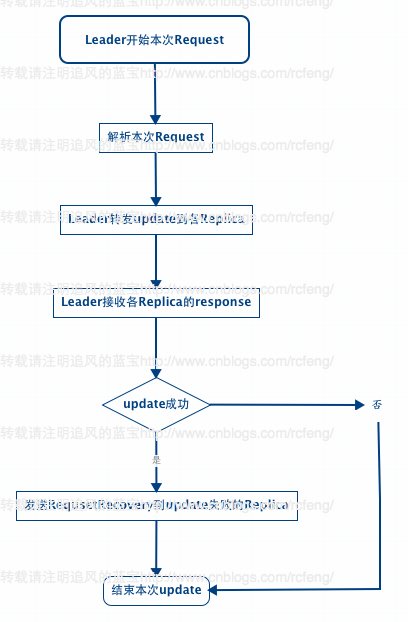
之前在<Solr4.8.0源码分析(15) 之 SolrCloud索引深入(2)>中讲到,不管update请求发送到哪个shard 分片中,最后在solrcloud里面进行分发的顺序都是从Leader发往Replica。Leader接受到update请求后先将document放入自己的索引文件以及update写入ulog中,然后将update同时转发给各个Replica分片。这就流程在就是之前讲到的add的索引链过程。
那么在索引链的add过程完毕后,SolrCloud会再依次调用finish()函数用来接受每一个Replica的响应,检查Replica的update操作是否成功。如果一旦有一个Replica没有成功,就会向update失败的Replica发送RequestRecovering命令强迫该分片进行Recoverying。
private void doFinish() {
// TODO: if not a forward and replication req is not specified, we could
// send in a background thread
cmdDistrib.finish();
List<Error> errors = cmdDistrib.getErrors();
// TODO - we may need to tell about more than one error...
// if its a forward, any fail is a problem -
// otherwise we assume things are fine if we got it locally
// until we start allowing min replication param
if (errors.size() > 0) {
// if one node is a RetryNode, this was a forward request
if (errors.get(0).req.node instanceof RetryNode) {
rsp.setException(errors.get(0).e);
} else {
if (log.isWarnEnabled()) {
for (Error error : errors) {
log.warn("Error sending update", error.e);
}
}
}
// else
// for now we don't error - we assume if it was added locally, we
// succeeded
}
// if it is not a forward request, for each fail, try to tell them to
// recover - the doc was already added locally, so it should have been
// legit
for (final SolrCmdDistributor.Error error : errors) {
if (error.req.node instanceof RetryNode) {
// we don't try to force a leader to recover
// when we cannot forward to it
continue;
}
// TODO: we should force their state to recovering ??
// TODO: do retries??
// TODO: what if its is already recovering? Right now recoveries queue up -
// should they?
final String recoveryUrl = error.req.node.getBaseUrl();
Thread thread = new Thread() {
{
setDaemon(true);
}
@Override
public void run() {
log.info("try and ask " + recoveryUrl + " to recover");
HttpSolrServer server = new HttpSolrServer(recoveryUrl);
try {
server.setSoTimeout(60000);
server.setConnectionTimeout(15000);
RequestRecovery recoverRequestCmd = new RequestRecovery();
recoverRequestCmd.setAction(CoreAdminAction.REQUESTRECOVERY);
recoverRequestCmd.setCoreName(error.req.node.getCoreName());
try {
server.request(recoverRequestCmd);
} catch (Throwable t) {
SolrException.log(log, recoveryUrl
+ ": Could not tell a replica to recover", t);
}
} finally {
server.shutdown();
}
}
};
ExecutorService executor = req.getCore().getCoreDescriptor().getCoreContainer().getUpdateShardHandler().getUpdateExecutor();
executor.execute(thread);
}
}
2. Recovery的总体流程
Replica接收到来自Leader的RequestRecovery命令后就会开始进行RecoveryStrategy线程,然后进行Recovery。总体流程如下图索引:
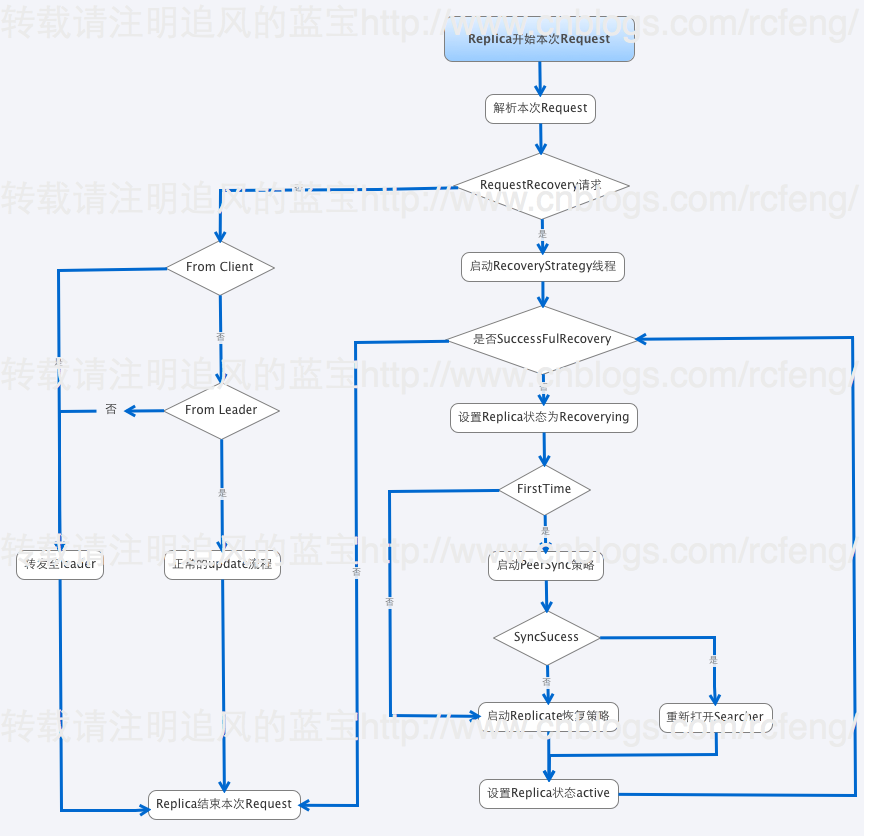
- 在RequestRecovery请求判断中,我例举了一部分(不是全部)请求命令,这是正常的索引链过程。
- 如果接受到的是RequestRecovery命令,那么本分片就会启动RecoveryStrategy线程来进行Recovery。
// if true, we are recovering after startup and shouldn't have (or be receiving) additional updates (except for local tlog recovery)
boolean recoveringAfterStartup = recoveryStrat == null; recoveryStrat = new RecoveryStrategy(cc, cd, this);
recoveryStrat.setRecoveringAfterStartup(recoveringAfterStartup);
recoveryStrat.start();
recoveryRunning = true;
- 分片会设置分片的状态recoverying。需要指出的是如果一旦检测到本分片成为了leader,那么Recovery过程就会退出。因为Recovery是从leader中同步数据的。
zkController.publish(core.getCoreDescriptor(), ZkStateReader.RECOVERING);
- 这里要判断下firsttime是否为true(在重启分片的时候会检查之前是否进行replication且没做完就被关闭了),firsttime是控制是否先进入PeerSync Recovery策略的,如果为false则跳过PeerSync进入Replicate。
if (recoveringAfterStartup) {
// if we're recovering after startup (i.e. we have been down), then we need to know what the last versions were
// when we went down. We may have received updates since then.
recentVersions = startingVersions;
try {
if ((ulog.getStartingOperation() & UpdateLog.FLAG_GAP) != 0) {
// last operation at the time of startup had the GAP flag set...
// this means we were previously doing a full index replication
// that probably didn't complete and buffering updates in the
// meantime.
log.info("Looks like a previous replication recovery did not complete - skipping peer sync. core="
+ coreName);
firstTime = false; // skip peersync
}
} catch (Exception e) {
SolrException.log(log, "Error trying to get ulog starting operation. core="
+ coreName, e);
firstTime = false; // skip peersync
}
}
- 最后进行选择进入是PeerSync策略和Replicate策略,在<Solr In Action 笔记(4) 之 SolrCloud分布式索引基础>中简单提到过两者的区别。关于具体的不同将在后面两节详细介绍。
- Peer sync, 如果中断的时间较短,recovering node只是丢失少量update请求,那么它可以从leader的update log中获取。这个临界值是100个update请求,如果大于100,就会从leader进行完整的索引快照恢复。
- Replication, 如果节点下线太久以至于不能从leader那进行同步,它就会使用solr的基于http进行索引的快照恢复。
- 最后设置分片的状态为active。并判断是否是sucessfulrrecovery,如果否则会多出尝试Recovery。
总结:
本文主要介绍了Recovery的起因以及Recovery过程,由于是简述所以内容较简单,主要提到了两种不同的Recovery策略,后续两文种将分别详细介绍。
Solr4.8.0源码分析(20)之SolrCloud的Recovery策略(一)的更多相关文章
- Solr4.8.0源码分析(21)之SolrCloud的Recovery策略(二)
Solr4.8.0源码分析(21)之SolrCloud的Recovery策略(二) 题记: 前文<Solr4.8.0源码分析(20)之SolrCloud的Recovery策略(一)>中提 ...
- Solr4.8.0源码分析(24)之SolrCloud的Recovery策略(五)
Solr4.8.0源码分析(24)之SolrCloud的Recovery策略(五) 题记:关于SolrCloud的Recovery策略已经写了四篇了,这篇应该是系统介绍Recovery策略的最后一篇了 ...
- Solr4.8.0源码分析(23)之SolrCloud的Recovery策略(四)
Solr4.8.0源码分析(23)之SolrCloud的Recovery策略(四) 题记:本来计划的SolrCloud的Recovery策略的文章是3篇的,但是没想到Recovery的内容蛮多的,前面 ...
- Solr4.8.0源码分析(22)之SolrCloud的Recovery策略(三)
Solr4.8.0源码分析(22)之SolrCloud的Recovery策略(三) 本文是SolrCloud的Recovery策略系列的第三篇文章,前面两篇主要介绍了Recovery的总体流程,以及P ...
- Solr4.8.0源码分析(25)之SolrCloud的Split流程
Solr4.8.0源码分析(25)之SolrCloud的Split流程(一) 题记:昨天有位网友问我SolrCloud的split的机制是如何的,这个还真不知道,所以今天抽空去看了Split的原理,大 ...
- Solr4.8.0源码分析(14)之SolrCloud索引深入(1)
Solr4.8.0源码分析(14) 之 SolrCloud索引深入(1) 上一章节<Solr In Action 笔记(4) 之 SolrCloud分布式索引基础>简要学习了SolrClo ...
- Solr4.8.0源码分析(15) 之 SolrCloud索引深入(2)
Solr4.8.0源码分析(15) 之 SolrCloud索引深入(2) 上一节主要介绍了SolrCloud分布式索引的整体流程图以及索引链的实现,那么本节开始将分别介绍三个索引过程即LogUpdat ...
- Solr4.8.0源码分析(17)之SolrCloud索引深入(4)
Solr4.8.0源码分析(17)之SolrCloud索引深入(4) 前面几节以add为例已经介绍了solrcloud索引链建索引的三步过程,delete以及deletebyquery跟add过程大同 ...
- Solr4.8.0源码分析(16)之SolrCloud索引深入(3)
Solr4.8.0源码分析(16)之SolrCloud索引深入(3) 前面两节学习了SolrCloud索引过程以及索引链的前两步,LogUpdateProcessorFactory和Distribut ...
随机推荐
- 构建ASP.NET MVC4+EF5+EasyUI+Unity2.x注入的后台管理系统(29)-T4模版
原文:构建ASP.NET MVC4+EF5+EasyUI+Unity2.x注入的后台管理系统(29)-T4模版 这讲适合所有的MVC程序 很荣幸,我们的系统有了体验的地址了.演示地址 之前我们发布了一 ...
- Android 官方文档:(二)应用清单 —— 2.2 <action>标签
syntax: <action android:name="string" /> contained in: <intent-filter> descrip ...
- [RxJS] Transformation operator: map and mapTo
We made our first operator called multiplyBy, which looks a bit useful, but in practice we don't nee ...
- css 权威指南笔记(三)结合css和XHTML
link rel stylesheet alternate stylesheet(候选样式表) title type media all screen print ..... 内联样式
- CentOS 6.7编译安装PHP 5.6
1.准备编译环境 yum install gcc gcc-c++ pcre* openssl* gd-devel* libxml2-devel bzip2-devel libcurl-devel 2. ...
- Asp.net Mvc 第二回 UrlRouting
一.什么是UrlRouting 你可以使用UrlRouting来配置一些URL的映射,使用户可以按你的规则来访问网站. 使用UrlRouting,一定要规定URL模式,它包括一个位置标识,它将在你请求 ...
- WPF 媒体播放器(MediaElement)实例,实现进度和音量控制
WPF 视频音频播放控件MediaElement实现进度控制,音量控制实例 说明: 1.Volume控制音量的大小,double类型,并且实现了属性依赖,可以用来双向绑定:在 0 和 1. 之间的线性 ...
- 使用Sqlite数据库存储数据
1.Sql基本命令 1.1.创建表 表是有行和列组成的,列称为字段,行称为记录. 使用CREATE命令来创建表: 1 CREATE TABLE tab_student (studentId INTEG ...
- HTTP could not register URL http://+:8000/.... Your process does not have access rights to this namespace
windows 7, Visual Studio 2013 在托管 Windows 服务中承载 WCF 服务时报错: HTTP could not register URL http://+:8000 ...
- IOS 多线程,线程同步的三种方式
本文主要是讲述 IOS 多线程,线程同步的三种方式,更多IOS技术知识,请登陆疯狂软件教育官网. 一般情况下我们使用线程,在多个线程共同访问同一块资源.为保护线程资源的安全和线程访问的正确性. 在IO ...