hadoop-0.20-集群搭建___实体机通过SSH访问基于VM安装的Linux
不得不说LZ在最开始搭建hadoop的时候,由于VM中的网段配置和本地IP地址没有配置好,
所以一直都在使用 VM的共享文件夹的功能,
以至于集群搭建好之后,只有namenode主机可以实现共享的功能,
所以导入导出文件都是使用scp 命令来实现的,十分的麻烦。
这次搭建hadoop, 如果使用SSH来与集群中的各个节点进行直接通信的话,
会使得 导入导出 安装包,基于hadoop框架编写的程序,在于实体机与VM之间传输变得十分容易。
首先,以namenode为例来介绍一下,如何实现VM 的Linux 与实体机进行SSH通信的。
LZ使用的是学校的校园网络,IP是万年不变的,还与自己校园卡上的名称一一对应,
与LZ在家中使用的宽带连接的动态IP分配有很多的不同之处,所以配置起来也可能会有一定的特殊性。
1.首先要通过VM的,Virtual NetWork Editor来对 VM的网段进行设置一下,
这个工具可以创建多个虚拟的网络适配器,我们在这里面选择已经存在的VMnet0
VMnet0 的各个配置是这样的:

在这里之所以要对VMnet0进行设置,是因为LZ在创建基于VM的Linux的时候,选择的网络适配器
就是VMnet0,选择哪个适配器可以在VM->Settings->Network Adapter 里面查看到。
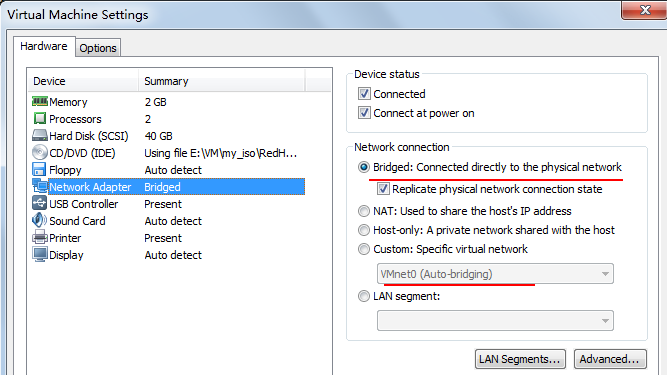
当然在虚拟机处于 running 状态或是 Suspend 状态的时候只能够查看,
只有在Shutdown的之后,才能够对VM 中的各个配置进行修改操作。
2.打开实体机的 命令提示符 窗口,输入 ifconfig 来查看实体机的IP地址。
LZ 主机IP地址假设为 125.66.66.46
以为想实现通过SSH 可以连接到 hadoop集群中的每一个结点,
所以,最好不要将 namenode的 IP地址设置为与实体机完全一致,
所以最好不要选用Host的方式,以免 每个node 的IP都和主机一致,
到时候通信起来会相当的混乱。
3.网络适配器和VM的网段选择一致以后,下面要对VM中的Linux主机IP地址进行修改了:
要持久的修改 Linux IP ,是要通过 修改文件来实现的:
vi /etc/sysconfig/network-script/ifcfg-eth0
DEVICE=eth0
IPADDR=125.66.66.66 #IP Address set NETMASK=255.255.255.0 #Mask set NETWORK=125.66.66.66 #可以没有这个,网络地址 BROADCAST=125.66.66.66 # broadcast adderss set 可以不要 GATEWAY=125.66.66.1 #Gateway address BOOTPROTO = static #IP 地址是静态的方式被引导的 ; 而不是被自动分配的
在所有的网络配置完成之后,
都需要重新启动一下网络服务才好
service network restart
关闭防火墙
service iptables stop
为了以防万一,再重新启动一下SSH服务;
顺便再看一下 22 号端口是否开启
cd /etc/init.d/ ./sshd restart netstat -antl | grep 22
然后,可以先分别在 Linux 和 实体机两个 命令台上 分别 ping 一下对方
Ping 通过之后, 可以使用SSH进行联通一下了:

选择 Connect 之后,在输入密码的话,就可以实现登陆到Linux上面了。

然后,我们使用SSH的文件传输功能将,hadoop-0.20 的安装包传入到,Linux的文件夹下面吧,
选择你想要的文件,点击Add,选择好要传入到Linux下面的文件路径即可。

接下来,同样的方式,使得实体机可以与datanode们,可以通过ssh通信之后,
把hadoop-0.20 版本的压缩包 ,通过ssh文件传输功能,传到对应的路径下,
进行解压缩、配置路径、修改配置文档、修改ssh密钥等操作,就可以很快搭建好一个hadoop的集群了。
这些内容在后续的文章中在详细介绍。
其实,最主要的思路就是,将Virtual Network Editor 中的网段 使其中的 某个VMnet*选择为 Bridge 类型的,
并且是自动获取IP,然后在创建虚拟机选择网络适配器的时候,选择先前设置好的VMnet* ,并且也选择Bridge类型的,
使得Linux 中 记录IP地址 的配置文件 中的IPADDR 与主机的IP 在前三个字段保持一致,由于集群的特殊性,不能让实体机与VM的IP一致,或是选用Host 类型的网段选择。
随后,关闭防火墙,重新刷新一下网络、SSH。互相 Ping一下,就可以了。
hadoop-0.20-集群搭建___实体机通过SSH访问基于VM安装的Linux的更多相关文章
- hadoop高可用集群搭建小结
hadoop高可用集群搭建小结1.Zookeeper集群搭建2.格式化Zookeeper集群 (注:在Zookeeper集群建立hadoop-ha,amenode的元数据)3.开启Journalmno ...
- Redis 5.0.5集群搭建
Redis 5.0.5集群搭建 一.概述 Redis3.0版本之后支持Cluster. 1.1.redis cluster的现状 目前redis支持的cluster特性: 1):节点自动发现 2):s ...
- Hadoop2.0 HA集群搭建步骤
上一次搭建的Hadoop是一个伪分布式的,这次我们做一个用于个人的Hadoop集群(希望对大家搭建集群有所帮助): 集群节点分配: Park01 Zookeeper NameNode (active) ...
- CDH 6.0.1 集群搭建 「Before install」
从这一篇文章开始会有三篇文章依次介绍集群搭建 「Before install」 「Process」 「After install」 继上一篇使用 docker 部署单机 CDH 的文章,当我们使用 d ...
- java_redis3.0.3集群搭建
redis3.0版本之后支持Cluster,具体介绍redis集群我就不多说,了解请看redis中文简介. 首先,直接访问redis.io官网,下载redis.tar.gz,现在版本3.0.3,我下面 ...
- hadoop伪分布式集群搭建与安装(ubuntu系统)
1:Vmware虚拟软件里面安装好Ubuntu操作系统之后使用ifconfig命令查看一下ip; 2:使用Xsheel软件远程链接自己的虚拟机,方便操作.输入自己ubuntu操作系统的账号密码之后就链 ...
- CDH 6.0.1 集群搭建 「After install」
集群搭建完成之后其实还有很多配置工作要做,这里我列举一些我去做的一些. 首先是去把 zk 的角色重新分配一下,不知道是不是我在配置的时候遗漏了什么在启动之后就有报警说目前只能检查到一个节点.去将 zk ...
- redis3.0.3集群搭建
redis3.0版本之后支持Cluster,具体介绍redis集群我就不多说,了解请看redis中文简介. 首先,直接访问redis.io官网,下载redis.tar.gz,现在版本3.0.3,我下面 ...
- ubuntu18.04 flink-1.9.0 Standalone集群搭建
集群规划 Master JobManager Standby JobManager Task Manager Zookeeper flink01 √ √ flink02 √ √ flink03 √ √ ...
随机推荐
- VS2010编译、调用Lua程序
一) .建立lua源代码工程,编译lua的静态库 1.下载Lua源码 http://www.lua.org/download.html a 下载后解压到一个目录下,这里假设解压到D:\lua-5.1. ...
- duck type鸭子类型
在程序设计中,鸭子类型(英语:duck typing)是动态类型的一种风格.在这种风格中,一个对象有效的语义,不是由继承自特定的类或实现特定的接口,而是由当前方法和属性的集合决定.这个概念的名字来源于 ...
- 悟透Javascript undefined,null,"",0这四个值转换为逻辑值时就是false &this关键字
话题一:undefined,null,"",0这四个值转换为逻辑值时就是false 也就是在if判断时会把上面的五个作为false来判断.但是它们的类型确是不尽相同的,如下所示. ...
- JavaScript 兼容处理IE67之 !"a"[0]
IE67对字符串进行取值需要使用charAt()方法,不能直接通过数组方式的坐标访问: <!DOCTYPE html> <html> <head> <meta ...
- 天津Uber优步司机奖励政策(1月18日~1月24日)
滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:http://www.cnblogs.com/mfry ...
- runtime/KVO等面试题
整理中... 1.KVO内部实现原则 回答:1>KVO是基于runtime机制实现的 2>当某个类的对象第一次被观察时,系统就会在运行期动态地创建该类的一个派生类,在这个派生类中重写基类中 ...
- mac svn命令
转载:Mac下svn command命令 svn help command 获取子命令说明 svn info $URL 查看工作空间信息 svn list 显示当前目录下svn记录文件列表,不访 ...
- oracle从客户端到sql语句追踪
这两天看小布老师的视频学习了一下从客户端到oracle数据库发送执行的SQL语句的跟踪,整理一下笔记. 需要用到的命令:netstat oracle端要用到的四个视图为: V$session:当前有多 ...
- Ehcache专栏
http://www.iteye.com/blogs/subjects/ehcache
- Hibernate输出SQL语句以便调试
配置方法:1.打开hibernate.cfg.xml文件编辑界面,在Properties窗口处,点击Add按钮,选择Show_SQL参数,输入值为True. *另外,如果按照同样的步骤,分别加入以下参 ...