三张关联表,大表;单次查询耗时400s,有group by order by 如何优化
问题SQL:
select
p.person_id as personId,
p.person_name as personName,
p.native_place as nativePlace,
ci.company_name as companyName,
pp.seal_number as sealNumber,
GROUP_CONCAT(pp.major) as major,
pp.register_name as registerName
from qyt_person p
left join qyt_person_practising pp on p.person_id=pp.person_id
left join qyt_company_info ci on p.company_id=ci.company_id
group by p.person_id,pp.register_name
order by p.create_time desc
limit 1,10
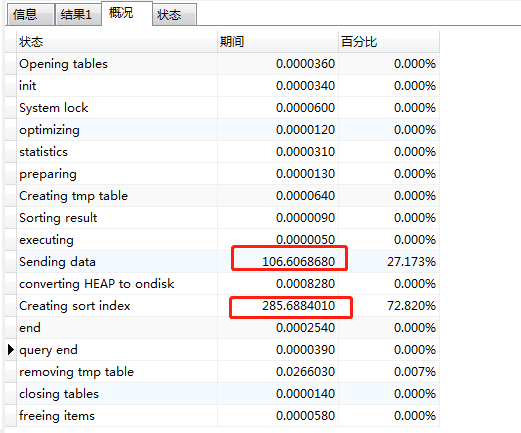
SQL总耗时393秒,通过Explain分析,发现为200万数据的表建立了临时表,且做了一次排序操作

通过查看SQL运行分析,也看出来,构造临时表耗时106秒,排序用了285秒(没索引的排序慢)
解决思路:根据业务需求再次审视如何减少数据量
1、业务需求:最新人员可以先取出来10名
2、取出来后再关联查询他们所在企业,所获证书(有索引,查询快)
3、这种小的临时表排序的耗时就可以接受了
4、SQL语句有子查询功能,可以把200万的表数据缩减为10人的小表
SQL语句如下:
select
p.person_id as personId,
p.person_name as personName,
p.native_place as nativePlace,
p.create_time as createTime,
ci.company_name as companyName,
pp.seal_number as sealNumber,
GROUP_CONCAT(pp.major) as major,
pp.register_name as registerName
from (SELECT person_id, person_name, native_place,company_id ,create_time from qyt_person order by create_time desc limit 0,10) p
left join qyt_person_practising pp on p.person_id=pp.person_id
left join qyt_company_info ci on p.company_id=ci.company_id
group by p.person_id,pp.register_name
ORDER BY p.create_time desc
limit 0,10
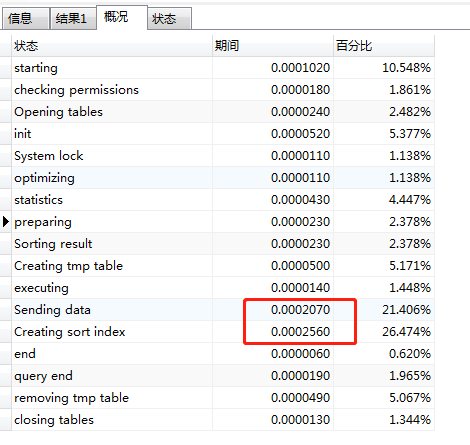
结果完美!响应时间为0.017秒
通过Explain分析,临时表就10条记录,所以处理耗时非常少

大块的时间还是损耗在构造临时表和排序上,但是这个时间必须得损失
三张关联表,大表;单次查询耗时400s,有group by order by 如何优化的更多相关文章
- mysql结构相同的三张表查询一条记录\将一张表中的数据插入另外一张表
将一张表中的数据插入另外一张表 1.两张表结构相同 insert into 表1名称 select * from 表2名称 2.两张结构不相同的表 insert into 表1名称(列名1,列名2,列 ...
- 如何优化MySQL千万级大表
很好的一篇博客,转载 如何优化MySQL千万级大表 原文链接::https://blog.csdn.net/yangjianrong1985/article/details/102675334 千万级 ...
- 走向DBA[MSSQL篇] 针对大表 设计高效的存储过程【原理篇】 附最差性能sql语句进化过程客串
原文:走向DBA[MSSQL篇] 针对大表 设计高效的存储过程[原理篇] 附最差性能sql语句进化过程客串 测试的结果在此处 本篇详解一下原理 设计背景 由于历史原因,线上库环境数据量及其庞大,很多千 ...
- switch...case...语句分析(大表跟小表何时产生)
一.switch...case...的格式 switch(表达式) { case 常量表达式1: 语句; break; case 常量表达式2: 语句; break; case 常量表达式3: 语句; ...
- Oracle中创建千万级大表归纳
从一月至今,我总共归纳了三种创建千万级大表的方案,它们是: 下面是这三种方案的对比表格: # 名称 地址 主要机制 速度 1 在Oracle中十分钟内创建一张千万级别的表 https://www.cn ...
- MySQL8.0大表秒加字段,是真的吗?
前言: 很早就听说 MySQL8.0 支持快速加列,可以实现大表秒级加字段.笔者自己本地也有8.0环境,但一直未进行测试.本篇文章我们就一起来看下 MySQL8.0 快速加列到底要如何操作. 1.了解 ...
- mysql分表和表分区详解
为什么要分表和分区? 日常开发中我们经常会遇到大表的情况,所谓的大表是指存储了百万级乃至千万级条记录的表.这样的表过于庞大,导致数据库在查询和插入的时候耗时太长,性能低下,如果涉及联合查询的情况,性能 ...
- 【mysql】mysql分表和表分区详解
为什么要分表和分区? 日常开发中我们经常会遇到大表的情况,所谓的大表是指存储了百万级乃至千万级条记录的表.这样的表过于庞大,导致数据库在查询和插入的时候耗时太长,性能低下,如果涉及联合查询的情况,性能 ...
- Django:常用字段、手动自动第三张表单、元信息
一.常用字段和非常用字段 二.手动,自动创建第三张表 三.元信息 四.defer和only 一.常用字段和非常用字段 -常用字段 AutoField int自增列,必须填入参数 primary_key ...
随机推荐
- SVN部署(基于Linux)
第一步:通过yum命令安装svnserve,命令如下: yum -y install subversion 此命令会全自动安装svn服务器相关服务和依赖,安装完成会自动停止命令运行 若需查看svn安装 ...
- 易错、经典问题:return不可返回指向栈内存的指针
预备知识:内存的分类 C/C++程序占用的内存分为两大类:静态存储区与动态存储区.其示意图如下所示: 数据保存在静态存储区与动态存储区的区别就是:静态存储区在编译-链接阶段已经确定了,程序运行过程中不 ...
- javascript语言学习
本课将和大家一起学习简单的js dom 操作,涵盖DOM API以及JQuery的方法. 相关简介 JavaScript一种直译式脚本语言,是一种动态类型.弱类型.基于原型的语 ...
- Python3+RobotFramework+pycharm环境搭建
我的环境为 python3.6.5+pycharm 2019.1.3+robotframework3.1.2 1.安装python3.x 略 之后在cmd下执行:pip install robot ...
- jquery mutilselect 插件添加中英文自动补全
jquery mutilselect默认只能根据设置的option来进行自动提示 $.each(availableTags, function(key, value) { $('#channels') ...
- “无处不在” 的系统核心服务 —— ActivityManagerService 启动流程解析
本文基于 Android 9.0 , 代码仓库地址 : android_9.0.0_r45 系列文章目录: Java 世界的盘古和女娲 -- Zygote Zygote 家的大儿子 -- System ...
- ESP8266开发之旅 网络篇④ Station——ESP8266WiFiSTA库的使用
1. 前言 在前面的篇章中,博主给大家讲解了ESP8266的软硬件配置以及基本功能使用,目的就是想让大家有个初步认识.并且,博主一直重点强调 ESP8266 WiFi模块有三种工作模式: St ...
- 七、springBoot 简单优雅是实现文件上传和下载
前言 好久没有更新spring Boot 这个项目了.最近看了一下docker 的知识,后期打算将spring boot 和docker 结合起来.刚好最近有一个上传文件的工作呢,刚好就想起这个脚手架 ...
- 解决IDEA下SpringBoot启动没有Run Dashboard并找回
前两天看到别人SpringBoot启动服务,启动器是长这样的 而我的呢?是这样的 Run Dashboard 它是一个代替Run窗口的一个更好清晰简洁的一个启动器. 如果我们需要启动多个窗口时,Run ...
- Java IO编程——字符流与字节流
在java.io包里面File类是唯一 一个与文件本身有关的程序处理类,但是File只能够操作文件本身而不能够操作文件的内容,或者说在实际的开发之中IO操作的核心意义在于:输入与输出操作.而对于程序而 ...