Scrapy+eChart自动爬取生成网络安全词云
因为工作的原因,近期笔者开始持续关注一些安全咨询网站,一来是多了解业界安全咨询提升自身安全知识,二来也是需要从各类安全网站上收集漏洞情报。
作为安全情报领域的新手,面对大量的安全咨询,多少还是会感觉无从下手力不从心。周末闲来无事,突发奇想,如果搞个爬虫,先把网络安全类文章爬下来,然后用机器学习先对文章进行分析,自动提取文章主成分关键词,然后再根据实际需求有选择的阅读相关文章,岂不是可以节省很多时间。
如果能提取文章的关键词,还可以根据近期文章的关键词汇总了解总体的安全态势和舆情,感觉挺靠谱。
整体思路
如前文所述,思路其实很简单:
用Scrapy先去安全咨询网站上爬取文章的标题和内容
对文章的内容进行切词
使用TF-IDF算法提取关键词
将关键词保存到数据库
最后可以用可视化将近期出现的比较频繁的关键词做个展示
看起来也不会很难,文末有代码的链接。
Scrapy爬虫
Scrapy是非常常用的python爬虫框架,基于scrapy写爬虫可以节省大量的代码和时间,原理这里就不赘述了,感兴趣的同学自行科普Scrapy教程,这里只贴一张图。
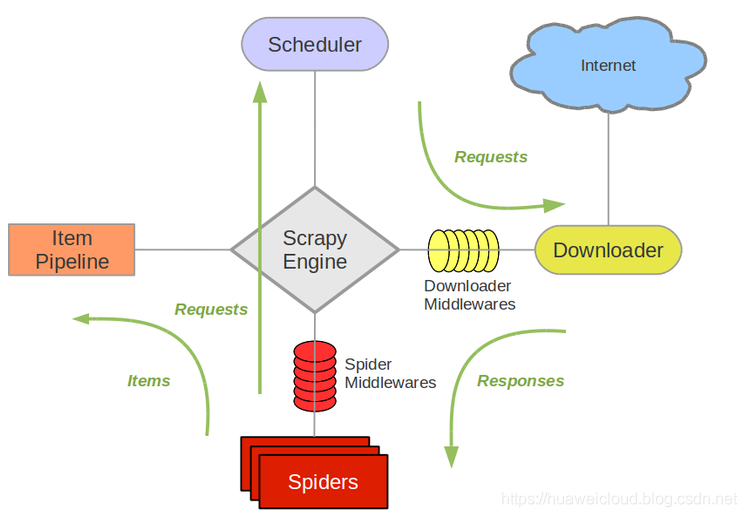
Scrapy架构
安装Scrapy
笔者基于python3.6来安装Scrapy,所以前提是你的机器已经安装好python3的环境。scrapy安装办法非常简单,使用pip可以一键安装
pip3 install scrapy装好以后,不熟悉scrapy的同学可以先看看官方示例程序熟悉一下,在cmd里执行下面的命令生成示例程序
scrapy startproject tutorial即可在当前目录自动创建一个完整的示例教程,这里我们可以看到整个爬虫的目录结构如下:
tutorial/
scrapy.cfg # deploy configuration file
tutorial/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py分析网页
本例以“E安全”网站为例,他们提供的安全咨询质量还是不错的,每天都有更新。大致看一眼网站的结构,会发现这个站点导航栏上有十多个安全咨询分类,点进去发现每个分类的url大致为https://www.easyaq.com/type/*.shtml,而每个分类下面又有相关的文章和链接若干。到这里思路就很清楚了,先遍历这几个文章分类,然后动态获取每个分类下的文章链接,之后挨个访问文章链接并把内容保存下来,下面分析一下主要的代码。
爬取网页
爬虫主体代码如下,使用scrapy的框架开发的爬虫实际的代码是非常精简的
import scrapy
from scrapy import Request, Selector
from sec_news_scrapy.items import SecNewsItem
class SecNewsSpider(scrapy.Spider):
name = "security"
allowed_domains = ["easyaq.com"]
start_urls = []
for i in range(2, 17):
req_url = 'https://www.easyaq.com/type/%s.shtml' % i
start_urls.append(req_url)
def parse(self, response):
topics = []
for sel in response.xpath('//*[@id="infocat"]/div[@class="listnews bt"]/div[@class="listdeteal"]/h3/a'):
topic = {'title': sel.xpath('text()').extract(), 'link': sel.xpath('@href').extract()}
topics.append(topic)
for topic in topics:
yield Request(url=topic['link'][0], meta={'topic': topic}, dont_filter=False, callback=self.parse_page)
def parse_page(self, response):
topic = response.meta['topic']
selector = Selector(response)
item = SecNewsItem()
item['title'] = selector.xpath("//div[@class='article_tittle']/div[@class='inner']/h1/text()").extract()
item['content'] = "".join(selector.xpath('//div[@class="content-text"]/p/text()').extract())
item['uri'] = topic['link'][0]
print('Finish scan title:' + item['title'][0])
yield item我们把网站上所有分类的url枚举出来放在start_url里面,parse是框架执行爬虫任务的入口,框架会自动访问前面start_url设置的页面,返回一个response对象,从这个对象中可以通过xpath提取有用的信息。
这里我们要从每一个类型页面的html中分析出文章的标题和访问uri,谷歌的chrome提供了很好的xpath生成工具,可以快速提取目标的xpath,在浏览器中按F12可以看到网页的html源码,找到需要提取的内容,右键可以提取xpath。
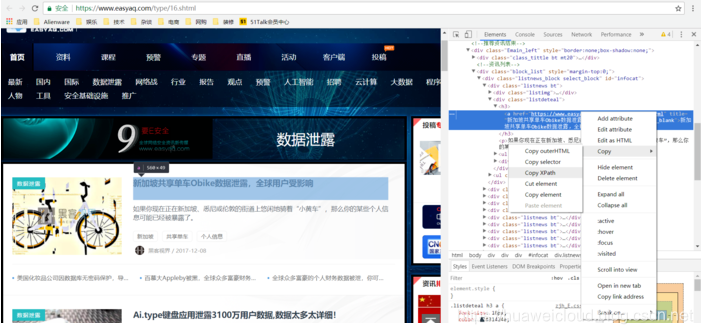
获取到文章内容的uri还没有完,我们还需要进一步访问该uri,并且把文章的内容记录下来供下一步分析,这里的parse_page函数就是用来做内容抽取的,方法同上,借助chrome的xpath分析工具很快就能提取到文章内容。
内容提取到以后,这里将内容存到Item中,Item是Scrapy框架的另一个组成部分,类似于字典类型,主要是用来定义传递数据的格式,而传递是为了下一步数据持久化。
数据持久化
Item.py
class SecNewsItem(scrapy.Item):
title = scrapy.Field()
content = scrapy.Field()
uri = scrapy.Field()
passpipeline.py
import jieba
import jieba.analyse
import pymysql
import re
def dbHandle():
conn = pymysql.connect(
host="localhost",
user="root",
passwd="1234",
charset="utf8",
db='secnews',
port=3306)
return conn
def is_figure(str):
value = re.compile(r'^\d+$')
if value.match(str):
return True
else:
return False
def save_key_word(item):
words = jieba.analyse.extract_tags(item['content'], topK=50, withWeight=True)
conn = dbHandle()
cursor = conn.cursor()
sql = "insert ignore into t_security_news_words(title, `key`, val) values (%s,%s,%s)"
try:
for word in words:
if is_figure(word[0]):
continue
cursor.execute(sql, (item['title'][0], word[0], int(word[1] * 1000)))
cursor.connection.commit()
except BaseException as e:
print("存储错误", e, "<<<<<<原因在这里")
conn.rollback()
def save_article(item):
conn = dbHandle()
cursor = conn.cursor()
sql = "insert ignore into t_security_news_article(title, content, uri) values (%s,%s,%s)"
try:
cursor.execute(sql, (item['title'][0], item['content'], item['uri']))
cursor.connection.commit()
except BaseException as e:
print("存储错误", e, "<<<<<<原因在这里")
conn.rollback()
class TutorialPipeline(object):
def process_item(self, item, spider):
save_key_word(item)
save_article(item)
return itemsettings.py
ITEM_PIPELINES = {
'sec_news_scrapy.pipelines.TutorialPipeline': 300,
}爬虫主程序中收集到的Item会传入到这里,这里有两个步骤save_key_word和save_article,后者将文章的标题、内容、uri存入到MySQL表里;这里着重介绍前者save_key_word函数。
我们的目标是自动分析文章里面跟主题相关的关键字,并且分析出每个词的权重,具体来说包含以下步骤:
切词:中文切词工具有很多,这里我选择用jieba实现
提取关键字:jieba里面已经实现好了TF/IDF的算法,我们利用该算法从每篇文章里选择top50的词汇,并且带上权重。用这种方式提取关键字还可以直接把常见的提用词过滤掉,当然jieba也支持自定义停用词
words = jieba.analyse.extract_tags(item['content'], topK=50, withWeight=True)提取关键词
数据存储:提取到需要的信息,下一步需要把信息保存到MySQL,在python3下面可以用pymysql来操作MySQL
文章列表
关键字列表
关键词可视化-词云
通过上面的程序,我们已经可以把网站上的安全咨询文章全部爬取到数据库,并且从每篇文章里面提取50个关键字。接下来我们希望把这些关键词用可视化的方式展示出来,出现频度高的关键词做高亮显示,所以很自然的想到用词云展示。
这里我们用eChart提供的echarts-wordcloud组件来做。做法非常简单,从MySQL的关键词表里统计数据,生成k-v字串用正则直接替换到html页面,当然这里更优雅的做法应该是用ajax从DB里取数据,我这里就先取个巧了。
def get_key_word_from_db():
words = {}
conn = dbHandle()
try:
with conn.cursor() as cursor:
cursor.execute(
"select `key`, sum(val) as s from t_security_news_words group by `key` order by s desc limit 300")
for res in cursor.fetchall():
words[res[0]] = int(res[1])
return words
except BaseException as e:
print("存储错误", e, "<<<<<<原因在这里")
conn.rollback()
return {}
finally:
conn.close()查看动态效果点这里,词云将词汇按照出现的频度或者权重与字体大小做关联,频度越高字体越大,从中我们可以大致感知到当前业界一些安全趋势,当然这也仅仅是一个例子。
词云可视化效果
调试技巧
python有很多IDE可选,笔者选择用pycharm,在调试scrapy程序的时候,需要用到scrapy的引擎启动,所以用默认的pycharm没法调试,需要做一些设置,如下图所示
run -> Edit Configurations
script填写scrapy安装目录里面的cmdline.py的位置;Script parameters是执行scrapy时用的参数,security是我们这个爬虫的名字;Working directory写爬虫的根目录。
配置好以后就可以直接用pycharm来启动debug了,run -> debug 'xxx'
完整的代码示例,包含echart的部分,请见github
作者:华为云享专家 菊花茶
Scrapy+eChart自动爬取生成网络安全词云的更多相关文章
- Python 爬取生成中文词云以爬取知乎用户属性为例
代码如下: # -*- coding:utf-8 -*- import requests import pandas as pd import time import matplotlib.pyplo ...
- python网络爬虫之使用scrapy自动爬取多个网页
前面介绍的scrapy爬虫只能爬取单个网页.如果我们想爬取多个网页.比如网上的小说该如何如何操作呢.比如下面的这样的结构.是小说的第一篇.可以点击返回目录还是下一页 对应的网页代码: 我们再看进入后面 ...
- Java爬取B站弹幕 —— Python云图Wordcloud生成弹幕词云
一 . Java爬取B站弹幕 弹幕的存储位置 如何通过B站视频AV号找到弹幕对应的xml文件号 首先爬取视频网页,将对应视频网页源码获得 就可以找到该视频的av号aid=8678034 还有弹幕序号, ...
- scrapy框架之CrawlSpider全站自动爬取
全站数据爬取的方式 1.通过递归的方式进行深度和广度爬取全站数据,可参考相关博文(全站图片爬取),手动借助scrapy.Request模块发起请求. 2.对于一定规则网站的全站数据爬取,可以使用Cra ...
- scrapy实现自动抓取51job并分别保存到redis,mongo和mysql数据库中
项目简介 利用scrapy抓取51job上的python招聘信息,关键词为“python”,范围:全国 利用redis的set数据类型保存抓取过的url,现实避免重复抓取: 利用脚本实现每隔一段时间, ...
- 爬虫系列5:scrapy动态页面爬取的另一种思路
前面有篇文章给出了爬取动态页面的一种思路,即应用Selenium+Firefox(参考<scrapy动态页面爬取>).但是selenium需要运行本地浏览器,比较耗时,不太适合大规模网页抓 ...
- Crawlspider的自动爬取
引子 : 如果想要爬取 糗事百科 的全栈数据的方法 ? 方法一 : 基于scrapy框架中的scrapy的递归爬取进行实现(requests模块递归回调parse方法) . 方法二 : 基于Crawl ...
- 安居客scrapy房产信息爬取到数据可视化(下)-可视化代码
接上篇:安居客scrapy房产信息爬取到数据可视化(下)-可视化代码,可视化的实现~ 先看看保存的数据吧~ 本人之前都是习惯把爬到的数据保存到本地json文件, 这次保存到数据库后发现使用mongod ...
- 如何手动写一个Python脚本自动爬取Bilibili小视频
如何手动写一个Python脚本自动爬取Bilibili小视频 国庆结束之余,某个不务正业的码农不好好干活,在B站瞎逛着,毕竟国庆嘛,还让不让人休息了诶-- 我身边的很多小伙伴们在朋友圈里面晒着出去游玩 ...
随机推荐
- CSPS模拟 79
T1 建一颗新树,倍增 T2 WARNING:竞赛图如果有环,则最小环一定为三元环 (发现这个结论的这把都稳了) 然后三元环计数,发现部分分都是为了审出题意但是不会正解的人设的.. 由于对于任意一种方 ...
- Git基础使用
前言 Git是版本控制系统,由Linux开源社区开发.与其他的版本系统相比,Git更加快速,便捷.主要是Git存储的是快照,而非差异性比较.并且绝大数操作都是访问本地文件和资源,没有网络时也可以直接提 ...
- ASP.NET Core 1.0: API的输入参数
Web API是需要接受参数的,譬如,通常用于创建数据的POST method需要接受输入数据,而用于GET method也需要接受一些可选参数,譬如:为了性能起见,控制返回数据的数量是至关重要的. ...
- SpringBoot 整合NoSql
通用配置 maven依赖 添加Spring-Web和Spring-Security依赖,使用Spring-Security是因为使用SpringBoot的Redis依赖时,必须添加Spring-Sec ...
- django学习与实践
Django简介 Django是一个由Python写成的开放源代码的Web应用框架,它最初是被用来开发管理劳伦斯出版集团旗下的一些以新闻内容为主的网站,即CMS(内容管理系统)软件. 并于2005 ...
- [ch01-03]神经网络基本原理
系列博客,原文在笔者所维护的github上:https://aka.ms/beginnerAI, 点击star加星不要吝啬,星越多笔者越努力. 前言 For things I don't know h ...
- hdu 4337 King Arthur's Knights (Hamilton)
King Arthur's KnightsTime Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Oth ...
- nyoj 92-图像有用区域 (BFS)
92-图像有用区域 内存限制:64MB 时间限制:3000ms 特判: No 通过数:4 提交数:12 难度:4 题目描述: “ACKing”同学以前做一个图像处理的项目时,遇到了一个问题,他需要摘取 ...
- Python3.7.1学习(一):redis的连接和简单使用
1.python 利用 redis 第三方库 首先安装:pip install redis 2.reids的连接 Redis使用StrictRedis对象来管理对一个redis server 的所有连 ...
- python 抓取youtube教程
前言: 相信大家很多人都看过youtube网站上的视频,网站上有很多的优质视频,清晰度也非常的高,看到喜欢的想要下载到本地,虽然也有很多方法,但是肯定没有python 来的快, 废话不多说,上代码: ...