【强化学习】DQN 算法改进
DQN 算法改进
(一)Dueling DQN
Dueling DQN 是一种基于 DQN 的改进算法。主要突破点:利用模型结构将值函数表示成更加细致的形式,这使得模型能够拥有更好的表现。下面给出公式,并定义一个新的变量:
\[
q(s_t, a_t)=v(s_t)+A(s_t, a_t)
\]
也就是说,基于状态和行动的值函数 \(q\) 可以分解成基于状态的值函数 \(v\) 和优势函数(Advantage Function)\(A\) 。由于存在:
\[
E_{a_{t}}[q(s_t, a_t)] = v(s_t)
\]
所以,如果所有状态行动的值函数不相同,一些状态行动的价值 \(q(s, a)\) 必然会高于状态的价值 \(v(s)\),当然也会有一些低于价值。于是优势函数可以表现出当前行动和平均表现之间的区别:如果优于平均表现,则优势函数为正,反之为负。
以上是概念上的分解,以下是网络结构上对应的改变:
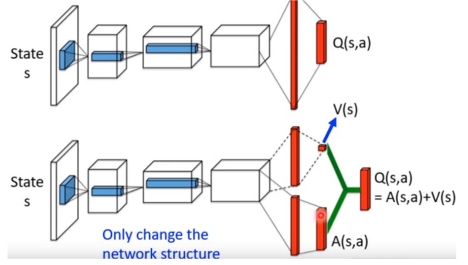
再保持主体网络不变的基础上,将原本网络中的单一输出变为两路输出,一个输出用于输出 \(v\) ,它是一个一维的标量;另一个输出用于输出 \(A\),它的维度和行动数量相同。最后将两部分加起来,就是原来的 \(q\) 值。
如果只进行以上单纯地分解,会引出另外一个问题:当 \(q\) 值一定使,\(v\) 和 \(A\) 有无穷多种可行组合,我们可以对 \(A\) 函数做限定。我们知道 \(A\) 函数地期望为 0:
\[
E_a[A(s_t, a_t)] = E_{a}[q(s_t, a_t)-v(s_t)]=v(s_t)-v(s_t)=0
\]
对 \(A\) 值进行约束,将公式变为:
\[
q(s_t, a_t) =v(s_t)+(A(s_t, a_t)- \frac{1}{|A|}\sum_{a'}A(s_t, a_t^{'}))
\]
让每一个 \(A\) 值减去当前状态下所有 \(A\) 值得平均数,就可以保证前面提到的期望值为 0 的约束,从而增加了 \(v\) 和 \(A\) 的输出稳定性。
实际意义: 将值函数分解后,每一部分的结果都具有实际意义。通过反卷积操作得到两个函数值对原始图像输入的梯度后,可以发现 \(v\) 函数对游戏中的所有关键信息都十分敏感,而 \(A\) 函数只对和行动相关的信息敏感。
(二)Priority Replay Buffer
Priority Replay Buffer 是一种针对 Replay Buffer 的改进结构。Replay Buffer 能够提高样本利用率的同时减少样本的相关性。它存在一个问题:每个样本都会以相同的频率被学习。但实际上,每个样本的难度是不同的,学习样本所得的收获也是不同的。为了使学习的潜力被充分挖掘出来,就有研究人员提出了 Priority Replay Buffer。它根据模型对当前样本的表现情况,给样本一定的权重,在采样时被采样的概率就和这个权重有关。交互时表现越差,对应权重越高,采样的概率也就越高。反之,如果表现越好,则权重也就降低,被采样的概率也就降低。这使得模型表现不好的样本可以有更高的概率被重新学习,模型会把更多精力放在这些样本上。
从算法原理来看,Priority Replay Buffer 与以往的 Replay Buffer 有两个差别:
(1)为每一个存入 Replay Buffer 的样本设定一个权重;
(2)使用这个权重完成采样过程:由于采样的复杂度较高,我们可以采用线段树数据结构来实现这个功能。
References
[1] 《强化学习精要——核心算法与 Tensorflow 实现》冯超
【强化学习】DQN 算法改进的更多相关文章
- 强化学习Q-Learning算法详解
python风控评分卡建模和风控常识(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005214003&am ...
- 强化学习-Q-Learning算法
1. 前言 Q-Learning算法也是时序差分算法的一种,和我们前面介绍的SARAS不同的是,SARSA算法遵从了交互序列,根据当前的真实行动进行价值估计:Q-Learning算法没有遵循交互序列, ...
- 强化学习——Q-learning算法
假设有这样的房间 如果将房间表示成点,然后用房间之间的连通关系表示成线,如下图所示: 这就是房间对应的图.我们首先将agent(机器人)处于任何一个位置,让他自己走动,直到走到5房 ...
- 强化学习基础算法入门 【PPT】
该部分内容来自于定期的小组讨论,源于师弟的汇报. ==============================================
- 强化学习-MDP(马尔可夫决策过程)算法原理
1. 前言 前面的强化学习基础知识介绍了强化学习中的一些基本元素和整体概念.今天讲解强化学习里面最最基础的MDP(马尔可夫决策过程). 2. MDP定义 MDP是当前强化学习理论推导的基石,通过这套框 ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- Deep Learning专栏--强化学习之MDP、Bellman方程(1)
本文主要介绍强化学习的一些基本概念:包括MDP.Bellman方程等, 并且讲述了如何从 MDP 过渡到 Reinforcement Learning. 1. 强化学习基本概念 这里还是放上David ...
- 深度学习-强化学习(RL)概述笔记
强化学习(Reinforcement Learning)简介 强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益.其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予 ...
- 强化学习(八)价值函数的近似表示与Deep Q-Learning
在强化学习系列的前七篇里,我们主要讨论的都是规模比较小的强化学习问题求解算法.今天开始我们步入深度强化学习.这一篇关注于价值函数的近似表示和Deep Q-Learning算法. Deep Q-Lear ...
随机推荐
- 大数据之路week01--自学之面向对象java(static,this指针(初稿))
函数的重载 返回值不一样会报错 java中,如果自己定义了构造函数的话,它就不会给你默认一个无参函数 如果一个属性,只进行定义,不初始化,自动补0,如果是一个布尔属性,默认是false但是如果一个局部 ...
- 8.5 NOIP 模拟测试 13
今天的考试说实话T1很简单没A,我是傻X.T2T3难得一批,但是暴力的分还是拿了! 总结一下就是:骗分过样例,暴力出奇迹!只要瞎搞就行了! 话说现在终于不像之前那么傻了,终于知道打暴力了,因为之前暴力 ...
- fcgi-2.4.1.tar.gz 和 spawn-fcgi-1.6.4.tar.gz 百度云
链接:https://pan.baidu.com/s/1nEzOkFC0-rfVMDy_BygLWg 提取码:ty0e 美好的东西都是免费滴
- Spring Cloud gateway 七 Sentinel 注解方式使用
Sentinel 注解支持 @SentinelResource 用于定义资源,并提供可选的异常处理和 fallback 配置项. @SentinelResource 注解包含以下属性: value:资 ...
- jquery ajax在 IE8/IE9 中无效
你们是不是也曾经和我以为遇到过这样的情况呢,jquery ajax在 IE8/IE9 中无效获取不到数据呢,经过熬夜找到好的东西和你们分享一下就是jQuery-ajaxTransport-XDomai ...
- Arduino 配置 ESP8266环境
Arduino 配置 ESP8266环境 将 http://arduino.esp8266.com/stable/package_esp8266com_index.json 添加到 [附加开发板管理器 ...
- shell脚本0——”一切皆文件“, 认识Shell
一.”一切皆文件“与“管道” 1)管道:grep foo /path/to/file | grep -n -k 3 | more 实际过程与我们直观认为的相反,最好通过实际过程理解.首先运行的是mor ...
- Javascript脚本语言
找组件用 id (唯一) 2.name 样式 使用分类 1 页面中 2 建JS文件 可以放在head也可以在body 工作区可以有 1 全局变量 2 由多个函数构成 标签编辑器 onChange 改变 ...
- WebSocket网络通信协议
WebSocket 协议在2008年诞生,2011年成为国际标准.所有浏览器都已经支持了. HTTP 协议有一个缺陷:通信只能由客户端发起.这种单向请求的特点,注定了如果服务器有连续的状态变化,客户端 ...
- window系统下删除多余的引导
window系统下删除多余的引导 1.首先第一步进入EFI分区删除多余系统引导,只留下需要的引导 如何进入EFI分区 a)win 搜索框输入cm, 右键以管理员运行命令行 b)输入命令 diskpar ...