雪花算法【分布式ID问题】【刘新宇】
分布式ID
1 方案选择
UUID
UUID是通用唯一识别码(Universally Unique Identifier)的缩写,开放软件基金会(OSF)规范定义了包括网卡MAC地址、时间戳、名字空间(Namespace)、随机或伪随机数、时序等元素。利用这些元素来生成UUID。
UUID是由128位二进制组成,一般转换成十六进制,然后用String表示。
550e8400-e29b-41d4-a716-446655440000
UUID的优点:
- 通过本地生成,没有经过网络I/O,性能较快
- 无序,无法预测他的生成顺序。(当然这个也是他的缺点之一)
UUID的缺点:
- 128位二进制一般转换成36位的16进制,太长了只能用String存储,空间占用较多。
- 不能生成递增有序的数字
数据库主键自增
大家对于唯一标识最容易想到的就是主键自增,这个也是我们最常用的方法。例如我们有个订单服务,那么把订单id设置为主键自增即可。
单独数据库 记录主键值
业务数据库分别设置不同的自增起始值和固定步长,如
第一台 start 1 step 9 第二台 start 2 step 9 第三台 start 3 step 9
优点:
- 简单方便,有序递增,方便排序和分页
缺点:
- 分库分表会带来问题,需要进行改造。
- 并发性能不高,受限于数据库的性能。
- 简单递增容易被其他人猜测利用,比如你有一个用户服务用的递增,那么其他人可以根据分析注册的用户ID来得到当天你的服务有多少人注册,从而就能猜测出你这个服务当前的一个大概状况。
- 数据库宕机服务不可用。
Redis
熟悉Redis的同学,应该知道在Redis中有两个命令Incr,IncrBy,因为Redis是单线程的所以能保证原子性。
优点:
- 性能比数据库好,能满足有序递增。
缺点:
- 由于redis是内存的KV数据库,即使有AOF和RDB,但是依然会存在数据丢失,有可能会造成ID重复。
- 依赖于redis,redis要是不稳定,会影响ID生成。
雪花算法-Snowflake
Snowflake是Twitter提出来的一个算法,其目的是生成一个64bit的整数:
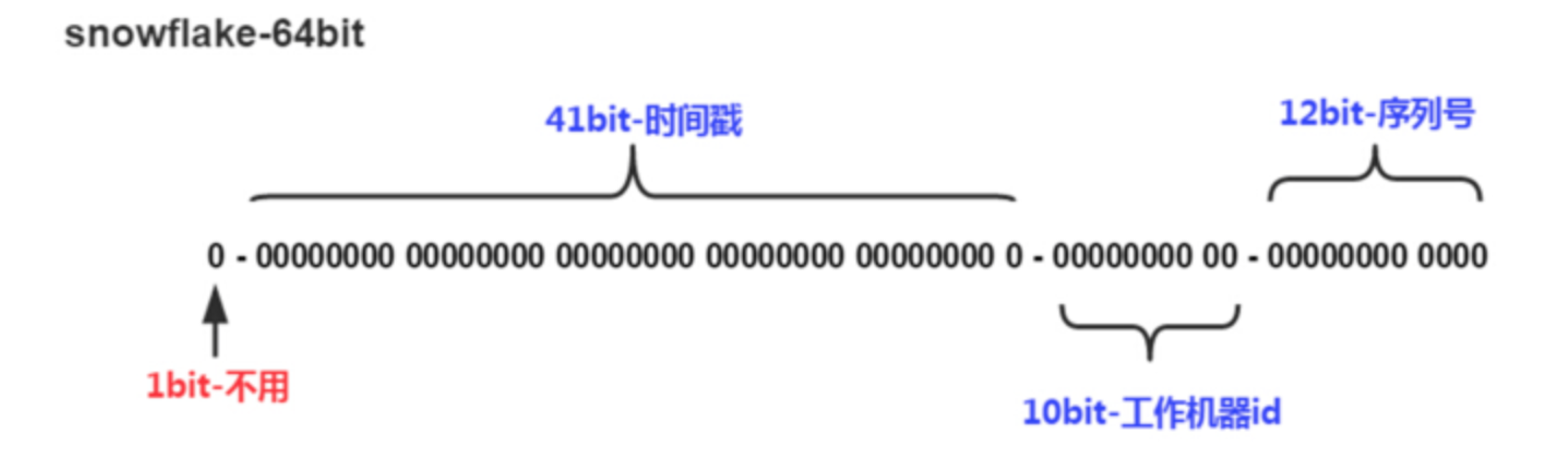
- 1bit:一般是符号位,不做处理
- 41bit:用来记录时间戳,这里可以记录69年,如果设置好起始时间比如今年是2018年,那么可以用到2089年,到时候怎么办?要是这个系统能用69年,我相信这个系统早都重构了好多次了。
- 10bit:10bit用来记录机器ID,总共可以记录1024台机器,一般用前5位代表数据中心,后面5位是某个数据中心的机器ID
- 12bit:循环位,用来对同一个毫秒之内产生不同的ID,12位可以最多记录4095个,也就是在同一个机器同一毫秒最多记录4095个,多余的需要进行等待下毫秒。
上面只是一个将64bit划分的标准,当然也不一定这么做,可以根据不同业务的具体场景来划分,比如下面给出一个业务场景:
- 服务目前QPS10万,预计几年之内会发展到百万。
- 当前机器三地部署,上海,北京,深圳都有。
- 当前机器10台左右,预计未来会增加至百台。
这个时候我们根据上面的场景可以再次合理的划分62bit,QPS几年之内会发展到百万,那么每毫秒就是千级的请求,目前10台机器那么每台机器承担百级的请求,为了保证扩展,后面的循环位可以限制到1024,也就是2^10,那么循环位10位就足够了。
机器三地部署我们可以用3bit总共8来表示机房位置,当前的机器10台,为了保证扩展到百台那么可以用7bit 128来表示,时间位依然是41bit,那么还剩下64-10-3-7-41-1 = 2bit,还剩下2bit可以用来进行扩展。

时钟回拨
因为机器的原因会发生时间回拨,我们的雪花算法是强依赖我们的时间的,如果时间发生回拨,有可能会生成重复的ID,在我们上面的nextId中我们用当前时间和上一次的时间进行判断,如果当前时间小于上一次的时间那么肯定是发生了回拨,算法会直接抛出异常.
使用雪花算法
# Twitter's Snowflake algorithm implementation which is used to generate distributed IDs.
# https://github.com/twitter-archive/snowflake/blob/snowflake-2010/src/main/scala/com/twitter/service/snowflake/IdWorker.scala import time
import logging class InvalidSystemClock(Exception):
"""
时钟回拨异常
"""
pass # 64位ID的划分
WORKER_ID_BITS = 5
DATACENTER_ID_BITS = 5
SEQUENCE_BITS = 12 # 最大取值计算
MAX_WORKER_ID = -1 ^ (-1 << WORKER_ID_BITS) # 2**5-1 0b11111
MAX_DATACENTER_ID = -1 ^ (-1 << DATACENTER_ID_BITS) # 移位偏移计算
WOKER_ID_SHIFT = SEQUENCE_BITS
DATACENTER_ID_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS
TIMESTAMP_LEFT_SHIFT = SEQUENCE_BITS + WORKER_ID_BITS + DATACENTER_ID_BITS # 序号循环掩码
SEQUENCE_MASK = -1 ^ (-1 << SEQUENCE_BITS) # Twitter元年时间戳
TWEPOCH = 1288834974657 logger = logging.getLogger('flask.app') class IdWorker(object):
"""
用于生成IDs
""" def __init__(self, datacenter_id, worker_id, sequence=0):
"""
初始化
:param datacenter_id: 数据中心(机器区域)ID
:param worker_id: 机器ID
:param sequence: 其实序号
"""
# sanity check
if worker_id > MAX_WORKER_ID or worker_id < 0:
raise ValueError('worker_id值越界') if datacenter_id > MAX_DATACENTER_ID or datacenter_id < 0:
raise ValueError('datacenter_id值越界') self.worker_id = worker_id
self.datacenter_id = datacenter_id
self.sequence = sequence self.last_timestamp = -1 # 上次计算的时间戳 def _gen_timestamp(self):
"""
生成整数时间戳
:return:int timestamp
"""
return int(time.time() * 1000) def get_id(self):
"""
获取新ID
:return:
"""
timestamp = self._gen_timestamp() # 时钟回拨
if timestamp < self.last_timestamp:
logging.error('clock is moving backwards. Rejecting requests until {}'.format(self.last_timestamp))
raise InvalidSystemClock if timestamp == self.last_timestamp:
self.sequence = (self.sequence + 1) & SEQUENCE_MASK
if self.sequence == 0:
timestamp = self._til_next_millis(self.last_timestamp)
else:
self.sequence = 0 self.last_timestamp = timestamp new_id = ((timestamp - TWEPOCH) << TIMESTAMP_LEFT_SHIFT) | (self.datacenter_id << DATACENTER_ID_SHIFT) | \
(self.worker_id << WOKER_ID_SHIFT) | self.sequence
return new_id def _til_next_millis(self, last_timestamp):
"""
等到下一毫秒
"""
timestamp = self._gen_timestamp()
while timestamp <= last_timestamp:
timestamp = self._gen_timestamp()
return timestamp if __name__ == '__main__':
worker = IdWorker(1, 2, 0)
print(worker.get_id())
雪花算法【分布式ID问题】【刘新宇】的更多相关文章
- 分布式雪花算法获取id
实现全局唯一ID 一.采用主键自增 最常见的方式.利用数据库,全数据库唯一. 优点: 1)简单,代码方便,性能可以接受. 2)数字ID天然排序,对分页或者需要排序的结果很有帮助. 缺点: 1)不同数据 ...
- snowflake 雪花算法 分布式实现全局id生成
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID. 这种方案大致来说是一种以划分命名空间(UUID也算,由于比较常见,所以单独分析)来生成ID的一种算法,这种方案 ...
- 分布式系统为什么不用自增id,要用雪花算法生成id???
1.为什么数据库id自增和uuid不适合分布式id id自增:当数据量庞大时,在数据库分库分表后,数据库自增id不能满足唯一id来标识数据:因为每个表都按自己节奏自增,会造成id冲突,无法满足需求. ...
- 雪花算法生成ID
前言我们的数据库在设计时一般有两个ID,自增的id为主键,还有一个业务ID使用UUID生成.自增id在需要分表的情况下做为业务主键不太理想,所以我们增加了uuid作为业务ID,有了业务id仍然还存在自 ...
- php实现雪花算法(ID递增)
雪花算法简单描述: 最高位是符号位,始终为0,不可用. 41位的时间序列,精确到毫秒级,41位的长度可以使用69年.时间位还有一个很重要的作用是可以根据时间进行排序. 10位的机器标识,10位的长度最 ...
- JWT验证机制【刘新宇】【Django REST framework中使用JWT】
JWT 在用户注册或登录后,我们想记录用户的登录状态,或者为用户创建身份认证的凭证.我们不再使用Session认证机制,而使用Json Web Token认证机制. 什么是JWT Json web t ...
- 缓存的有效期和淘汰策略【Redis和其他缓存】【刘新宇】
缓存有效期与淘汰策略 有效期 TTL (Time to live) 设置有效期的作用: 节省空间 做到数据弱一致性,有效期失效后,可以保证数据的一致性 Redis的过期策略 过期策略通常有以下三种: ...
- Python软件定时器APScheduler使用【软件定时器,非操作系统定时器,软件可控的定时器】【用途:定时同步数据库和缓存等】【刘新宇】
APScheduler使用 APScheduler (advanceded python scheduler)是一款Python开发的定时任务工具. 文档地址 https://apscheduler. ...
- 模拟电磁曲射炮_H题 方案分析【2019年电赛】【刘新宇qq522414928】
请查看我的有道云笔记: 文档:电磁曲射炮分析.note链接:http://note.youdao.com/noteshare?id=26f6b6febc04a8983d5efce925e92e21
随机推荐
- 你竟然没用 Maven 构建项目?
一年前,当我和小伙伴小龙一起做一个外包项目的时候,受到了严重的鄙视.我那时候还不知道 Maven,所以搭建项目用的还是最原始的方式,小龙不得已在导入项目的时候花了很长时间去下载项目依赖的开源类库. 出 ...
- MyBatis从入门到精通(五):MyBatis 注解方式的基本用法
最近在读刘增辉老师所著的<MyBatis从入门到精通>一书,很有收获,于是将自己学习的过程以博客形式输出,如有错误,欢迎指正,如帮助到你,不胜荣幸! 1. @Select 注解 1.1 使 ...
- git常用总结
git 基本配置 安装git yum -y install git git全局配置 git config --global user.name "lsc" #配置git使用用户 g ...
- 【Go】使用压缩文件优化io (二)
原文链接: https://blog.thinkeridea.com/201907/go/compress_file_io_optimization2.html 上一篇文章<使用压缩文件优化io ...
- Python连载21-collections模块
一.collections模块 1.函数namedtuple (1)作用:tuple类型,是一个可命名的tuple (2)格式:collections(列表名称,列表) (3)返回值:一个含有列表的 ...
- 一套简单的web即时通讯——第三版
前言 接上版,本次版本做了如下优化: 1.新增同意.拒绝添加好友后做线上提示: 2.新增好友分组,使用工具生成后台API,新增好友分组功能,主要功能有:添加分组.重命名分组名称.删除分组 3.新增好友 ...
- 机器学习读书笔记(五)AdaBoost
一.Boosting算法 .Boosting算法是一种把若干个分类器整合为一个分类器的方法,在boosting算法产生之前,还出现过两种比较重要的将多个分类器整合为一个分类器的方法,即boostrap ...
- HDU 4057:Rescue the Rabbit(AC自动机+状压DP)***
http://acm.hdu.edu.cn/showproblem.php?pid=4057 题意:给出n个子串,串只包含‘A’,'C','G','T'四种字符,你现在需要构造出一个长度为l的串,如果 ...
- HDU 5773:The All-purpose Zero(贪心+LIS)
http://acm.hdu.edu.cn/showproblem.php?pid=5773 The All-purpose Zero Problem Description ?? gets an ...
- 安装Win10,ERROR_0x8007025D问题解决
Windows10安装的时候,出现ERROR CODE:0x8007025D 大概提示为:windows 无法安装所需的文件.请确保安装所需的所有文件可用,并重新启动安装. 本人在出现这个问题的原因, ...