论文解读2——Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
背景
用ConvNet方法解决图像分类、检测问题成为热潮,但这些方法都需要先把图片resize到固定的w*h,再丢进网络里,图片经过resize可能会丢失一些信息。论文作者发明了SPP pooling(空间金字塔池化)层,让网络可以接受任意size的输入。
方法
首先思考一个问题,为什么ConvNet需要一个固定size的图片作为输入,我们知道,Conv层只需要channel固定(彩色图片3,灰度图1),但可以接受任意w*h的输入,当然输出的w*h也会跟着变化;然而,后面的FC层却需要固定长度的vector作为输入,图片size变化->conv层输出的size变化->FC层输入的vector长度变化,这就产生了错误。
怎么解决这个问题呢?作者给出的方法是在最后一层Conv层后面加上一个SPP pooling层,SPP pooling层可以将接收到的不同size的输入转换成为固定的输出,保证FC层的输入长度固定。
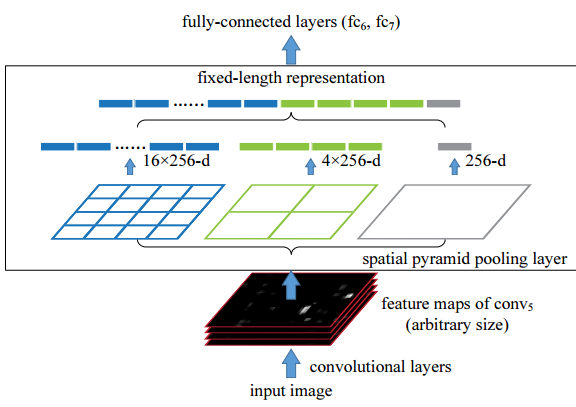
如图,SPP pooling层的原理很简单,例子如下:给定一个w*h的特征图,把其分别分成4*4、2*2、1*1的bin,在每个bin上面作pooling操作(文中使用的是max pooling),最后能得到16*256-d(256-d是最后一个conv层的输出通道数),4*256-d、1*256-d的feature vector,最后连接在一起,得到的就是21*256-d的feature vector。
可以看到,不管一开始的w和h取值多少,最后都能得到固定长度的feature vector作为FC层的输入,这样,ConvNet就能接受不同size的图片作为输入了。
总结
论文作者通过在FC层前面加上一个SPP pooling层,有效解决了ConvNet必须接受固定size的图片。
论文解读2——Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition的更多相关文章
- 深度学习论文翻译解析(九):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
论文标题:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 标题翻译:用于视觉识别的深度卷积神 ...
- SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
http://www.dengfanxin.cn/?p=403 原文地址 我对物体检测的一篇重要著作SPPNet的论文的主要部分进行了翻译工作.SPPNet的初衷非常明晰,就是希望网络对输入的尺寸更加 ...
- 目标检测--Spatial pyramid pooling in deep convolutional networks for visual recognition(PAMI, 2015)
Spatial pyramid pooling in deep convolutional networks for visual recognition 作者: Kaiming He, Xiangy ...
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition Kaiming He, Xiangyu Zh ...
- 论文阅读笔记二十五:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPPNet CVPR2014)
论文源址:https://arxiv.org/abs/1406.4729 tensorflow相关代码:https://github.com/peace195/sppnet 摘要 深度卷积网络需要输入 ...
- SPP Net(Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)论文理解
论文地址:https://arxiv.org/pdf/1406.4729.pdf 论文翻译请移步:http://www.dengfanxin.cn/?p=403 一.背景: 传统的CNN要求输入图像尺 ...
- SPP NET (Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)
1. https://www.cnblogs.com/gongxijun/p/7172134.html (SPP 原理) 2.https://www.cnblogs.com/chaofn/p/9305 ...
- 目标检测(二)SSPnet--Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognotion
作者:Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun 以前的CNNs都要求输入图像尺寸固定,这种硬性要求也许会降低识别任意尺寸图像的准确度. ...
- 论文笔记:(2019CVPR)PointConv: Deep Convolutional Networks on 3D Point Clouds
目录 摘要 一.前言 1.1直接获取3D数据的传感器 1.2为什么用3D数据 1.3目前遇到的困难 1.4现有的解决方法及存在的问题 二.本文idea 2.1 idea来源 2.2 初始思路 2.3 ...
随机推荐
- 多线程总结-同步之synchronized关键字
目录 1.为什么要使用synchronized? 2.synchronized锁什么,加锁的目的是什么? 3.代码示例 3.1锁this和临界资源对象 3.2锁class类对象 3.3 什么时候锁临界 ...
- C++ 编程技巧锦集(一)
C++刷题精髓在STL编程,还有一些函数.下面我就总结一下本人在刷题过程中,每逢遇见总要百度的内容………………(大概率因为本人刷题太少了) 1. map map<string, int> ...
- 从后端到前端之Vue(二)写个tab试试水
上一篇写了一下table,然后要写什么呢?当然是tab了.动态创建一个tab,里面放一个table,这样一个后台管理的基本功能(之一)就出来了. 好吧,这里其实只是试试水,感受一下vue的数据驱动可以 ...
- [Linxu] Ubuntu下载mysql
//下载: sudo apt install mysql-server sudo apt install mysql-client sudo apt install libmysqlclient-de ...
- Baozi Leetcode Solution 290: Word Pattern
Problem Statement Given a pattern and a string str, find if str follows the same pattern. Here follo ...
- 个人永久性免费-Excel催化剂功能第17波-批量文件改名、下载、文件夹创建等
前几天某个网友向我提出催化剂的图片功能是否可以增加导出图片功能,这个功能我一直想不明白为何有必要,图片直接在电脑里设个文件夹维护着不就可以了么?何苦还要把Excel上的图片又重新导出到文件夹中?这个让 ...
- python整型-浮点型-字符串-列表及内置函数(上)
整型 简介 # 是否可变类型: 不可变类型 # 作用:记录年龄.手机号 # 定义: age = 18 # --> 内部操作 age = int(18) # int('sada') # 报错 in ...
- Visual Studio 调试(系列文章)
调试是软件开发过程中非常重要的一个部分,它具挑战性,但是也有一定的方法和技巧. Visual Studio 调试程序有助于你观察程序的运行时行为并发现问题. 该调试器可用于所有 Visual Stud ...
- Linux系统安装Tomcat——.tar.gz版
1.rpm.deb.tar.gz的区别: rpm格式的软件包适用于基于Red Hat发行版的系统,例如Red Hat Linux.SUSE.Fedora. deb格式的软件包则是适用于基于Debian ...
- docker环境下使用gitlab,gitlab-runner 为 NetCore 持续集成
环境 Centos7.6 安装应用docker,docker-compose (我的Centos是用Hyper-V跑的分了8G的内存,阿里云2G根本跑不起来gitlab) 为了保证我的Centos环境 ...