.NET Core ORM 类库Petapoco中对分页Page添加Order By对查询的影响
介绍
最近一直在使用Petapoco+Entity Framework Core结合开发一套系统。
使用EFCore进行Code First编码,使用PMC命令生成数据库表的信息。
使用Petapoco进行数据库的常规操作。并且结合PetaPoco.SqlKata的使用,减少了编写SQL语句的工作量,对提升开发效率有很大的帮助。Petapoco对数据库的支持非常的全,包括常规的一下数据库:SQL Server,SQL Server CE,MS Access,SQLite,MySQL,MariaDB,PostgreSQL,Firebird DB和Oracle。当然SQL Server为默认的支持。PetaPoco.SqlKata支持的数据库也是非常全的,包括:SqlServer, MySql, Postgres, Firebird, SQLite, Oracle。
## 遇到的问题
在数据库操作过程中,发现每个Controller的Index页面加载的非常缓慢,加载完成大约需要5s的时间,在浏览器端等待的时间相对来说是非常长的一个时间。对于出现的问题终于有时间进行解决一下了。
先来看一下未使用Order By加载页面的耗时情况,第一个图中涉及的表的主键为guid类型,第二个图中涉及的主键为ulong类型,对于不同的主键进行分页查询时也有较大影响。
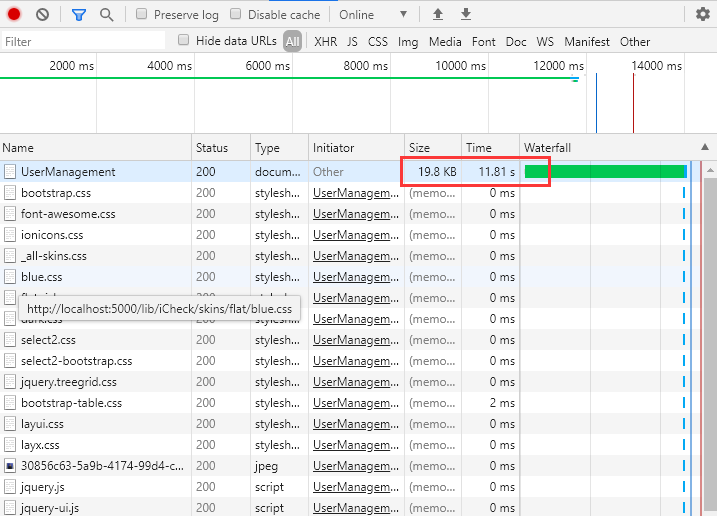
图一
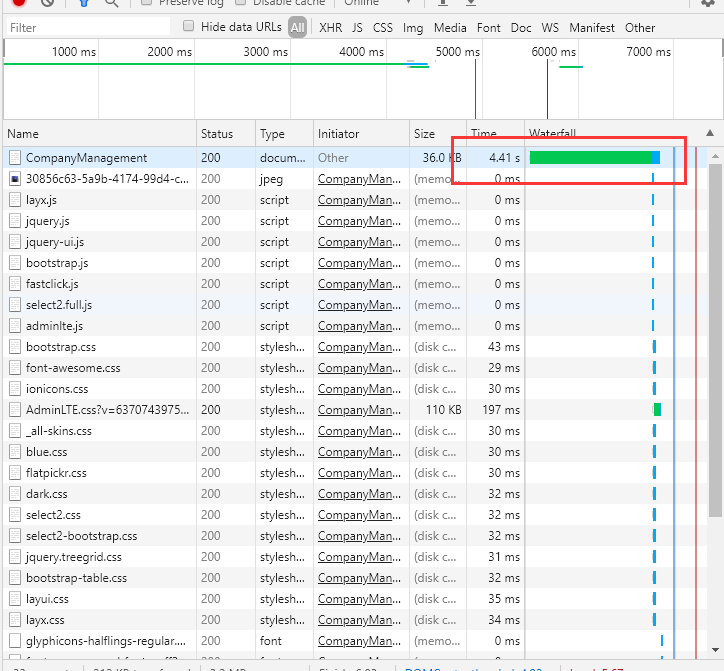
图二
优化后运行情况
使用Order by加载页面的耗时情况
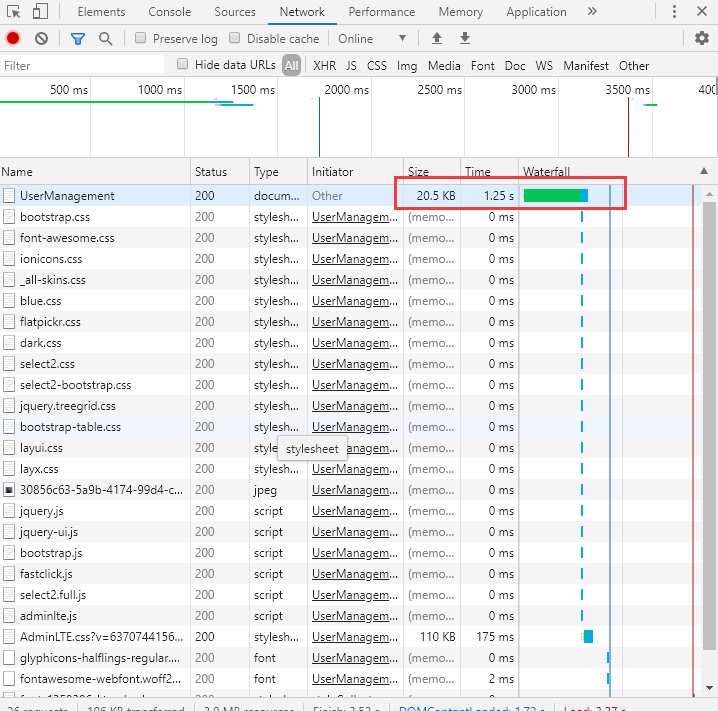
图三
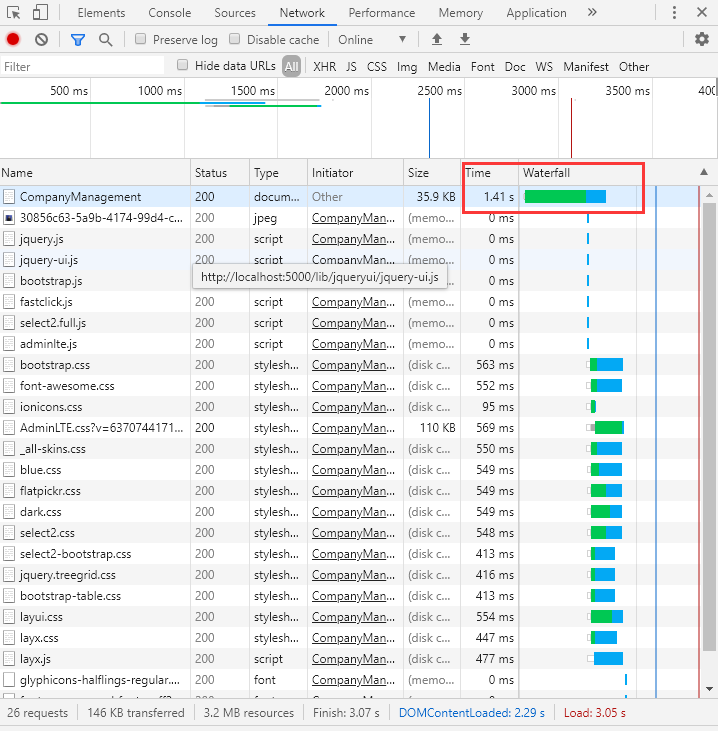
图四
## 进行验证OrderBy对时间的影响
对出现的问题,使用StopWatch进行监视运行时间的长短,使用了分页的两种方法,区别是否加Order By语句,组成成如下四种情况:
- PageAsync Order by
- PageAsync
- Page Order by
- Page
代码如下:
Stopwatch stop = new Stopwatch();
stop.Start();
var pages = await _context.PageAsync<productdto>(page, itemsPerPage, "order by id");
stop.Stop();
_logger.Information($" Order By Async查询的执行时间:{stop.Elapsed}");
stop.Restart();
var pages2 = await _context.PageAsync<productdto>(page, itemsPerPage );
stop.Stop();
_logger.Information($"Async查询的执行时间:{stop.Elapsed}");
//_logger.Information($"SQL:{_context.LastSQL}");
stop.Restart();
var ps = _context.Page<productdto>(page, itemsPerPage, "order by id");
stop.Stop();
_logger.Information($"Order By查询的执行时间:{stop.Elapsed}");
stop.Restart();
var ps2 = await _context.PageAsync<productdto>(page, itemsPerPage);
stop.Stop();
_logger.Information($"查询的执行时间:{stop.Elapsed}");
stop.Restart();
var x = _mapper.Map<page<productviewmodel>>(pages);
stop.Stop();
_logger.Information($"Mapper的执行时间:{stop.Elapsed}");
结果
运行后台输出的日志信息,可以看到对于是否加Order By对查询耗时的影响是非常大的,对是否使用异步方法对耗时也有部分的影响

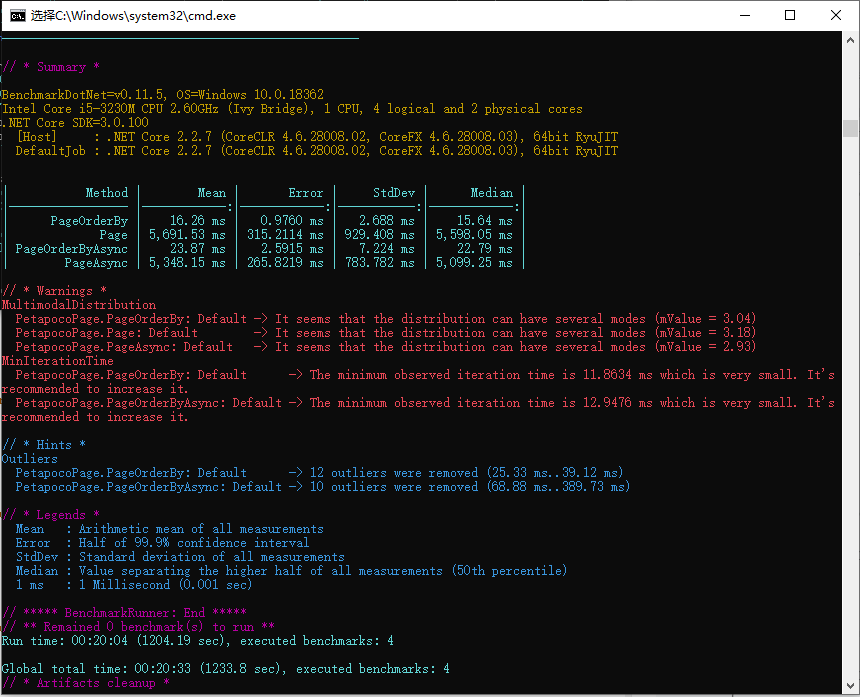
Benchmark对Page的性能测试
对于上述的四种情况再次使用Benchmark进行一次性能测试,对使用的数据表的实体类不在列出
namespace PetaPocoPageBenchMark
{
class Program
{
static void Main(string[] args)
{
var summary = BenchmarkRunner.Run<petapocopage>();
Console.WriteLine("Hello World!");
}
}
public class PetapocoPage
{
public static IDatabase Database =&gt;
new Database(DatabaseConfiguration.Build()
.UsingConnectionString(
"server=192.168.88.3;port=3306;uid=root;pwd=biobase;database=BiobaseProductionQrCode;")
.UsingProvider<mariadbdatabaseprovider>());
[Benchmark]
public void PageOrderBy()
{
Database.Page<productmanufacturelinedetaildto>(1, 20, "order by CreateDate");
}
[Benchmark]
public void Page()
{
Database.Page<productmanufacturelinedetaildto>(1, 20);
}
[Benchmark]
public void PageOrderByAsync()
{
Database.PageAsync<productmanufacturelinedetaildto>(1, 20, "order by CreateDate");
}
[Benchmark]
public void PageAsync()
{
Database.PageAsync<productmanufacturelinedetaildto>(1, 20);
}
}
}
对性能测试结果可以看到,使用Order By对性能的影响确实是非常大。
.NET Core ORM 类库Petapoco中对分页Page添加Order By对查询的影响的更多相关文章
- 微型ORM:PetaPoco 学习资料整理
github地址:https://github.com/CollaboratingPlatypus/PetaPoco petapoco 实体中字段去掉关联(类似于EF中的NotMap) 微型ORM:P ...
- .Net Core ORM选择之路,哪个才适合你 通用查询类封装之Mongodb篇 Snowflake(雪花算法)的JavaScript实现 【开发记录】如何在B/S项目中使用中国天气的实时天气功能 【开发记录】微信小游戏开发入门——俄罗斯方块
.Net Core ORM选择之路,哪个才适合你 因为老板的一句话公司项目需要迁移到.Net Core ,但是以前同事用的ORM不支持.Net Core 开发过程也遇到了各种坑,插入条数多了也特别 ...
- .NET Core 3.0或3.1 类库项目中引用 Microsoft.AspNetCore.App
本文为原创文章.首发:http://www.zyiz.net/ 在 ASP.NET Core 3.0+ web 项目中已经不需要在 .csproj 中添加对 Microsoft.AspNetCore. ...
- ORM之PetaPoco错误--VS中NUGet程序包管理安装PetaPoco
一般在Vs中使用PetaPoco的时候都是使用NuGet程序包管理来安装PetaPoco的,如果你在安装PetaPoco前设置了ConnectionString,那么PetaPoco中的T4模板会自动 ...
- 【译】微型ORM:PetaPoco【不完整的翻译】
PetaPoco是一款适用于.Net 和Mono的微小.快速.单文件的微型ORM. PetaPoco有以下特色: 微小,没有依赖项……单个的C#文件可以方便的添加到任何项目中. 工作于严格的没有装饰的 ...
- 【译】微型ORM:PetaPoco
PetaPoco是一款适用于.Net 和Mono的微小.快速.单文件的微型ORM. PetaPoco有以下特色: 微小,没有依赖项……单个的C#文件可以方便的添加到任何项目中. 工作于严格的没有装饰的 ...
- 【译】微型ORM:PetaPoco【不完整的翻译】(转)
出处:http://www.cnblogs.com/youring2/archive/2012/06/04/2532130.html PetaPoco是一款适用于.Net 和Mono的微小.快速.单文 ...
- C#轻型ORM框架PetaPoco试水
近端时间从推酷app上了解到C#轻微型的ORM框架--PetaPoco.从github Dapper 开源项目可以看到PetaPoco排第四 以下是网友根据官方介绍翻译,这里贴出来. PetaPoco ...
- 轮子来袭 vJine.Core Orm 之 01_快速体验
vJine.Core 是.Net环境下C#类库,在其包含的众多功能中ORM功能尤为突出,现简介如下. 一.支持的数据库: SQLite, MySQL, MS SQL, Oracle. 二.使用方法: ...
随机推荐
- java使用FileSystem上传文件到hadoop文件系统
import java.io.FileNotFoundException; import java.io.IOException; import java.net.URI; import org.ap ...
- OkHttp3使用教程,实现get、post请求发送,自动重试,打印响应日志。
一.创建线程安全的okhttp单例 import service.NetworkIntercepter;import service.RetryIntercepter;import okhttp3.* ...
- Aspose.Cell导出带chart图表
最终实现的效果就是这样,代码比较多,我放在了CSDN上了,是无需模板的,别听网上瞎吹,说什么要模板,地址是:https://download.csdn.net/download/chanelwtt/1 ...
- NodeManager概述(基本职能和内部架构)
概述 NodeManager是运行在单个节点上的代理,它需要与应用程序的的ApplicationMaster和集群管理者ResourceManager交互: 从ApplicationMaster上接收 ...
- Chrome 查看产品原型图
1.找到产品发的原型图 2.找到文件resources\chrome\axure-chrome-extension,修改文件的后缀为rar,然后解压 3.找到chrome的extensions,找到开 ...
- C++基础之关联容器
关联容器 关联容器和顺序容器的本质区别:关联容器是通过键存取和读取元素.顺序容器通过元素在容器中的位置顺序存储和访问元素.因此,关联容器不提供front.push_front.pop_front.ba ...
- logback.xml配置文件解析一
配置文件主要结构如下: <?xml version="1.0" encoding="utf-8"?> <configuration> & ...
- adb命令整理(持续整理)
用到过的adb命令都整理下来,省的一直百度,还不一定能找到合适的答案 获得正在运行app的包名 :adb shell dumpsys window | findstr mCurrentFocus 1. ...
- golang1.13中重要的新特新
本文索引 语言变化 数字字面量 越界索引报错的完善 工具链改进 GOPROXY GOSUMDB GOPRIVATE 标准库的新功能 判断变量是否为0值 错误处理的革新 Unwrap Is As gol ...
- Spring MVC-从零开始-@RequestMapping 注解method属性
1.@RequestMapping 处理 HTTP 的各种方法(GET, PUT, POST, DELETE PATCH) package com.jt; import org.springfram ...