巨杉Tech | Hbase迁移至SequoiaDB 实战
背景
在传统银行 IT 架构中,联机交易与统计分析系统往往采用不同的技术与物理设备,通过定期执行的 ETL 将联机交易数据向分析系统中迁移。而作为数据服务资源池,同一份数据可能被不同类型的微服务共享访问。当一些联机交易与审计类业务针对同一份数据同时运行时,必须保证请求在完全隔离的物理环境中执行,做到交易分析业务无干扰。
HBase 是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,善于处理大数据场景,具备以下特点:
表规模大,亿级别行,上百万列
面向列存储,列独立检索
但是 HBase 在使用中也存在下面的一些问题:
HBase 只能做简单的 key-value 查询,无法实现复杂的统计 SQL
HBase 不支持多索引
运维复杂。Hadoop 作为一套完整大数据分析体系框架,操作比较复杂,出现问题难以定位
为了解决上述问题,在典型的数据中台和服务平台业务中,用户需要选择一个可弹性扩展的分布式关系型数据库,以满足以下需求:
标准SQL支持
支持高并发
多索引中支持
易维护等需求
SequoiaDB 巨杉数据库是计算存储分离架构,这种分布式架构一方面可以提供针对数据表的无限横向水平扩张,另一方面在计算层通过提供不同类型数据库实例的方式,100%兼容 MySQL,PostgreSQL 与 SparkSQL协议与语法。除了结构化数据外,SequoiaDB 巨杉数据库可以在同一集群支持包括 JSON 和 S3 对象存储、以及Posix文件系统在内的非结构化数据,使整个数据库面向上层的微服务架构应用提供了完整的数据服务资源池。
SequoiaDB 支持复杂 SQL 查询、支持多索引、支持高并发,并且作为开源分布式数据库运维简单便捷。到目前为止,已有大量用户从 HBase 迁移至 SequoiaDB,本文将与大家分享从 HBase 迁移数据至 SequoiaDB 的操作实战。
1 导出HBase数据
先用 Hive 把 HBase 数据导出为 csv 文件。Hbase 数据结构如下: 
图1 Hbase数据结构 整合HBase和hive, 创建hive外部表进行关联
hive 创建外部表关联 Hbase 参考语句
CREATE EXTERNAL TABLE hbase_user(
id string,
name string,
phone string,
birthday string,
id_number string,
gender string,
email string,
address string
) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:name,info:phone,info:birthday,info:id_number,info:gender,info:email,i nfo:address") # 指定映射关系,:key为rowkey
TBLPROPERTIES ("hbase.table.name" = "user"); # 指定要映射的hbase表名
整合效果如下所示
hive (default)> select * from hbase_user limit ;
OK
hbase_user.id hbase_user.name hbase_user.phone hbase_user.birthday hbase_user.id_number hbase_user.gender hbase_user.email hbase_user.address
0004928c7287408085403c6ec4cd3c12 刘英 -- M maojuan@yahoo.com 黑龍江省晶市徐汇六盘水街J座
导出 hive 表中的数据到 csv
# hive表导出csv参考语句
insert overwrite local directory '/tmp/data/hbase_hive_export_user' row format delimited # 指定行分割符
fields terminated by ',' # 执行的列分割符
select * from hbase_user;
导出的数据如下图所示,为 csv 格式
[hadoop@node hbase_hive_export_user.csv]$ tail -2f 000000_0
ffdca61d22b74462aefdcb948d819542,边志强,,--,52062819960928857X,M,ming52@gmail.com,内蒙古自治区太原县浔阳史街P座
ffdf82a4e2f84c3a9c99e726153d9496,傅玉华,,--,,M,yanhe@hotmail.com,辽宁省兵县山亭深圳路h座
2 通过CSV文件导入到SequoiaDB中
sdbimprt 是 SequoiaDB 的数据导入工具,它可以将 JSON 格式或 csv 格式的数据导入到 SequoiaDB 数据库中。
将 HBase 导出的 csv 文件导入到 SequoiaDB 中,导入的命令如下:
sdbimprt --hosts=localhost: --type=csv --file=user.csv -c users -l employee --fields='id string,name string,phone string,birthday string,id_number string,gender string,email string,address string'
其中集合空间名称为users,集合名称为 employee,执行结果如下:
$ sdbimprt --hosts=localhost: --type=csv --file=user.csv -c users -l employee --fields='id string,name string,phone string,birthday string,id_number string,gender string,email string,address string'
parsed records:
parse failure:
sharding records:
sharding failure:
imported records:
import failure:
3 在SequoiaDB 的MySQL层创建HBase对应映射表
CREATE TABLE `employee` (
`id` int() DEFAULT NULL,
`name` varchar() COLLATE utf8mb4_bin DEFAULT NULL,
`phone` int() DEFAULT NULL,
`birthday` datetime DEFAULT NULL,
`id_number` int() DEFAULT NULL,
`gender` varchar() COLLATE utf8mb4_bin DEFAULT NULL,
`email` varchar() COLLATE utf8mb4_bin DEFAULT NULL,
`address` int() DEFAULT NULL
) ENGINE=SEQUOIADB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
4 在SequoiaDB 的SAC图形化界面查看数据导入情况
SAC 图形化界面是 SequoiaDB 巨杉数据库自研的一款图形化工具,具备自动化部署集群、配置主机及集群信息、监控主机及集群状态、查看集群数据等等功能,可大幅度提高数据库管理效率。
图2 SAC图形化界面功能展示
登录到 SequoiaDB 存储引擎层,查看数据量为24282,数据导入成功完毕。
#sdb
> db = new Sdb("localhost", )
> db.users.employee.count()
Takes .002236s.
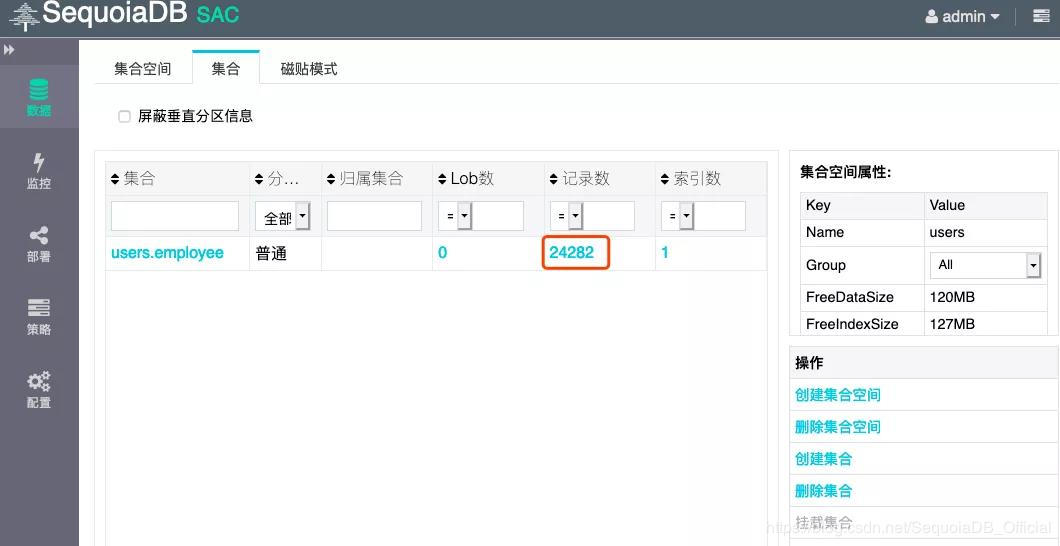
图3 SAC图形化界面SequoiaDB存储引擎层查看数据示意图
同时,在 SequoiaDB 对应的 MySQL 实例层,可以查看到对应数据是24282
$ /opt/sequoiasql/mysql/bin/mysql -h 127.0.0.1 -P -u root
...
mysql> use users;
Database changed
mysql> show tables;
+-----------------+
| Tables_in_users |
+-----------------+
| employee |
+-----------------+
row in set (0.00 sec)
mysql> select count(*) from employee;
+----------+
| count(*) |
+----------+
| |
+----------+
row in set (0.00 sec)
在SequoiaDB 的 SAC 图形化界面中,查看 MySQL 实例层,得出数据条数为24282
图4 SAC界面MySQL实例层查询数据示意图
5 在SequoiaDB 中执行多索引查询验证
在 SequoiaDB 的 mysql 实例层创建多个索引
mysql> ALTER TABLE `employee` ADD INDEX index_id (`id`);
mysql> ALTER TABLE `employee` ADD INDEX index_email (`name`);
在SequoiaDB的mysql实例层,执行多个索引查询:
mysql> select count(*) from employee where name="xiuyingxia";
+----------+
| count(*) |
+----------+
| |
+----------+
row in set (0.00 sec)
从 HBase 迁移数据至 SequoiaDB,并且在 SequoiaDB 的 SAC 界面可以分别从底层存储引擎层和 MySQL 的实例层查看到对应导入的数据,并且支持多索引查询。
总结
SequoiaDB 支持复杂 SQL 查询、支持多索引、支持高并发,作为开源分布式数据库运维简单便捷。Hbase 迁移至 SequoiaDB,可以先通过 hive 导出数据文件 csv 格式,然后通过 SequoiaDB 的导入工具 sdbimprt 导入到 SequoiaDB 中。
巨杉Tech | Hbase迁移至SequoiaDB 实战的更多相关文章
- HBase数据迁移到Kafka实战
1.概述 在实际的应用场景中,数据存储在HBase集群中,但是由于一些特殊的原因,需要将数据从HBase迁移到Kafka.正常情况下,一般都是源数据到Kafka,再有消费者处理数据,将数据写入HBas ...
- 巨杉Tech | 使用 SequoiaDB 分布式数据库搭建JIRA流程管理系统
介绍 JIRA是Atlassian公司出品的项目与事务跟踪工具,被广泛应用于缺陷跟踪.客户服务.需求收集.流程审批.任务跟踪.项目跟踪和敏捷管理等工作领域.很多企业与互联网公司都在使用Jira作为内部 ...
- 巨杉Tech|SequoiaDB 巨杉数据库高可用容灾测试
数据库的高可用是指最大程度地为用户提供服务,避免服务器宕机等故障带来的服务中断.数据库的高可用性不仅仅体现在数据库能否持续提供服务,而且也体现在能否保证数据的一致性. SequoiaDB 巨杉数据库作 ...
- 巨杉Tech | 微服务趋势下的数据库设计与应用简析
周五(7月12日)巨杉数据库参与了由得到App主办八里庄技术沙龙活动,分享主题是关于分布式数据库架构与实战. 以下就是根据巨杉数据库现场分享的内容进行的分享实录整理. 巨杉数据库简介 巨杉,专注新一代 ...
- 巨杉Tech | 十分钟快速搭建 Wordpress 博客系统
介绍 很多互联网应用程序开发人员第一个接触到的网站项目就是博客系统.而全球使用最广的Wordpress常常被用户用来快速搭建个人博客网站.默认情况下,Wordpress一般在后台使用MySQL关系型数 ...
- 【巨杉数据库SequoiaDB】巨杉Tech | 巨杉数据库数据高性能数据导入迁移实践
SequoiaDB 一款自研金融级分布式数据库产品,支持标准SQL和分布式事务功能.支持复杂索引查询,兼容 MySQL.PGSQL.SparkSQL等SQL访问方式.SequoiaDB 在分布式存储功 ...
- 巨杉Tech | SequoiaDB虚机镜像正式上线
数据库云化架构需求 随着云架构的发展和流行,在业务和应用进行“云化”的过程中,云数据库因为在整体架构中的重要地位,在云化改造中的重要性不言而喻.云数据库需要满足这些技术要求,除了在功能上的具体提升,在 ...
- 巨杉Tech | SequoiaDB数据域及存储规划
1 背景近年来,企业的各项业务发展迅猛,客户数目不断增加,后台服务系统压力也越来越大,系统的各项硬件资源也变得非常紧张.因此,在技术风险可控的基础上,希望引入大数据技术,利用大数据技术优化现有IT系统 ...
- 【巨杉数据库SequoiaDB】巨杉Tech | 分布式数据库千亿级超大表优化实践
01 引言 随着用户的增长.业务的发展,大型企业用户的业务系统的数据量越来越大,超大数据表的性能问题成为阻碍业务功能实现的一大障碍.其中,流水表作为最常见的一类超大表,是企业级用户经常碰到的性能瓶颈. ...
随机推荐
- Python3 反射
反射 python面向对象中的反射:通过字符串的形式操作对象相关的属性 hasattr(obj,name) # hasattr(obj, name) # 判断一个对象是否有指定的属性name,返回Tr ...
- 洛谷 P3628 特别行动队
洛谷题目页面传送门 题意见洛谷. 这题一看就是DP... 设\(dp_i\)表示前\(i\)个士兵的最大战斗力.显然,最终答案为\(dp_n\),DP边界为\(dp_0=0\),状态转移方程为\(dp ...
- React预备知识点
1.react中的状态提升 react的状态提升就是用户对子组件操作,子组件不改变自己的状态,而是通过自己的props把操作改变的数据传递给父组件,改变父组件的状态,从而改变受父组件控制的所有子组件的 ...
- 数据结构与算法—二叉排序树(java)
前言 前面介绍学习的大多是线性表相关的内容,把指针搞懂后其实也没有什么难度.规则相对是简单的. 再数据结构中树.图才是数据结构标志性产物,(线性表大多都现成api可以使用),因为树的难度相比线性表大一 ...
- [HNOI2009]双递增序列(动态规划,序列dp)
感觉这个题还蛮难想的. 首先状态特别难想.设\(dp[i][j]\)表示前i个数,2序列的长度为j的情况下,2序列的最后一个数的最小值. 其中1序列为上一个数所在的序列,2序列为另外一个序列. 这样设 ...
- python学习之路(3)---列表
列表定义: 列表就是一个数据的集合,列表是可以重复的,可以对存储的数据进行增删改查, 列表的写法: list_name = ['ljwang','wangwu'] 列表的嵌套 a = ['1',['2 ...
- ip地址、域名、DNS、URL的区别与联系
IP:每个连接到Internet上的主机都会分配一个IP地址,此ip是该计算机在互联网上的逻辑地址的唯一标识,计算机之间的访问就是通过IP地址来进行的.写法:十进制的形式,用“.”分开,叫做“点分十进 ...
- c11标准
在编译器vs13及其以上可以使用 编译器对语言的一种优化 1.变量初始化 int a=0,a(10),a{10};定义a的值的三种方式 2.nullptr 相当于c的null 有类型 更加的安全 3. ...
- Spring Boot 默认指标从哪来?
了解有关 Spring Boot 默认指标及其来源的更多信息. 您是否注意到 Spring Boot 和 Micrometer 为您的应用生成的所有默认指标? 如果没有 - 您可以将 actuator ...
- ArcMap和ArcGIS Pro加载百度地图
前面发布了两篇我用ArcBruTile开发用于ArcMap加载百度地图的插件ArcBruTileBaidu,放在网上后评论和反响还不错,还有两位大学同学通过百度搜索居然搜到我本人!文章和技术介绍也被网 ...