单链表的C++实现(采用模板类)
采用模板类实现的好处是,不用拘泥于特定的数据类型。就像活字印刷术,制定好模板,就可以批量印刷,比手抄要强多少倍!
此处不具体介绍泛型编程,还是着重叙述链表的定义和相关操作。
链表结构定义
定义单链表的结构可以有4方式。如代码所示。
本文采用的是第4种结构类型
/*************************************************************************
1、复合类:在Node类中定义友元的方式,使List类可以访问结点的私有成员
*************************************************************************/
class LinkNode
{
friend class LinkList;
private:
int data;
LinkNode *next;
}; class LinkList
{
public:
//单链表具体操作
private:
LinkNode *head;
}; /*************************************************************************
2、嵌套类:在List内部定义Node类,但是Node的数据成员放在public部分,使List
和Node均可以直接访问Node的成员
*************************************************************************/
class LinkList
{
public:
//单链表具体操作
private:
class LinkNode
{
public:
int data;
LinkNode *next;
};
LinkNode *head;
}; /*************************************************************************
3、继承:在Node类中把成员定义为protected,然后让List继承Node类,这样就可以
访问Node类的成员了。
*************************************************************************/
class LinkNode
{
protected:
int data;
LinkNode *next;
}; class LinkList : public LinkNode
{
public:
//单链表具体操作
private:
LinkNode *head;
}; /*************************************************************************
4、直接用struct定义Node类,因为struct的成员默认为公有数据成员,所以可直接
访问(struct也可以指定保护类型)。
*************************************************************************/
struct LinkNode
{
int data;
LinkNode *next;
}; class LinkList
{
public:
//单链表具体操作
private:
LinkNode *head;
};
单链表的模板类定义
使用模板类需要注意的一点是template<class T>必须定义在同一个文件,否则编译器会无法识别。
如果在.h中声明类函数,但是在.cpp中定义函数具体实现, 会出错。所以,推荐的方式是直接在.h中定义。
/* 单链表的结点定义 */
template<class T>
struct LinkNode
{
T data;
LinkNode<T> *next;
LinkNode(LinkNode<T> *ptr = NULL){next = ptr;}
LinkNode(const T &item, LinkNode<T> *ptr = NULL)
//函数参数表中的形参允许有默认值,但是带默认值的参数需要放后面
{
next = ptr;
data = item;
}
}; /* 带头结点的单链表定义 */
template<class T>
class LinkList
{
public:
//无参数的构造函数
LinkList(){head = new LinkNode<T>;}
//带参数的构造函数
LinkList(const T &item){head = new LinkNode<T>(item);}
//拷贝构造函数
LinkList(LinkList<T> &List);
//析构函数
~LinkList(){Clear();}
//重载函数:赋值
LinkList<T>& operator=(LinkList<T> &List);
//链表清空
void Clear();
//获取链表长度
int Length() const;
//获取链表头结点
LinkNode<T>* GetHead() const;
//设置链表头结点
void SetHead(LinkNode<T> *p);
//查找数据的位置,返回第一个找到的满足该数值的结点指针
LinkNode<T>* Find(T &item);
//定位指定的位置,返回该位置上的结点指针
LinkNode<T>* Locate(int pos);
//在指定位置pos插入值为item的结点,失败返回false
bool Insert(T &item, int pos);
//删除指定位置pos上的结点,item就是该结点的值,失败返回false
bool Remove(int pos, T &item);
//获取指定位置pos的结点的值,失败返回false
bool GetData(int pos, T &item);
//设置指定位置pos的结点的值,失败返回false
bool SetData(int pos, T &item);
//判断链表是否为空
bool IsEmpty() const;
//打印链表
void Print() const;
//链表排序
void Sort();
//链表逆置
void Reverse();
private:
LinkNode<T> *head;
};
定位位置
/* 返回链表中第pos个元素的地址,如果pos<0或pos超出链表最大个数返回NULL */
template<class T>
LinkNode<T>* LinkList<T>::Locate(int pos)
{
int i = ;
LinkNode<T> *p = head; if (pos < )
return NULL; while (NULL != p && i < pos)
{
p = p->next;
i++;
} return p;
}
插入结点
单链表插入结点的处理如图
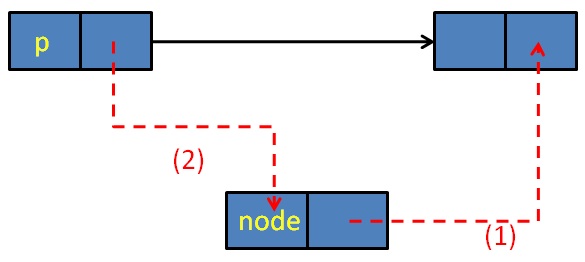
图:单链表插入操作
要在p结点后插入一个新结点node,(1)要让node的next指针指向p的next结点;(2)再让p的next指向node结点(即断开图中的黑色实线,改成红色虚线指向node)
接下来:node->next = p->next; p->next = node;
template<class T>
bool LinkList<T>::Insert(T &item, int pos)
{
LinkNode<T> *p = Locate(pos);
if (NULL == p)
return false; LinkNode<T> *node = new LinkNode<T>(item);
if (NULL == node)
{
cerr << "分配内存失败!" << endl;
exit();
}
node->next = p->next;
p->next = node;
return true;
}
删除结点
删除结点的处理如图:
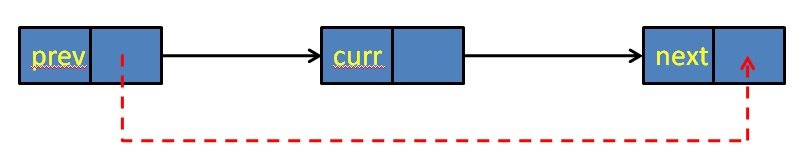
图:单链表删除
删除pos位置的结点,如果这个位置不存在结点,则返回false;
如果找到对应结点,则通过实参item输出要删除的结点的数值, 然后删除结点并返回true。
template<class T>
bool LinkList<T>::Remove(int pos, T &item)
{
LinkNode<T> *p = Locate(pos);
if (NULL == p || NULL == p->next)
return false; LinkNode<T> *del = p->next;
p->next = del->next;
item = del->data;
delete del;
return true;
}
清空链表
遍历整个链表,每次head结点的next指针指向的结点,直到next指针为空。
最后保留head结点。
template<class T>
void LinkList<T>::Clear()
{
LinkNode<T> *p = NULL; //遍历链表,每次都删除头结点的next结点,最后保留头结点
while (NULL != head->next)
{
p = head->next;
head->next = p->next; //每次都删除头结点的next结点
delete p;
}
}
求链表长度和打印链表
着两个功能的实现非常相近,都是遍历链表结点,不赘述。
template<class T>
void LinkList<T>::Print() const
{
int count = ;
LinkNode<T> *p = head;
while (NULL != p->next)
{
p = p->next;
std::cout << p->data << " ";
if (++count % == ) //每隔十个元素,换行打印
cout << std::endl;
}
} template<class T>
int LinkList<T>::Length() const
{
int count = ;
LinkNode<T> *p = head->next;
while (NULL != p)
{
p = p->next;
++count;
}
return count;
}
单链表倒置
单链表的倒置处理如图:
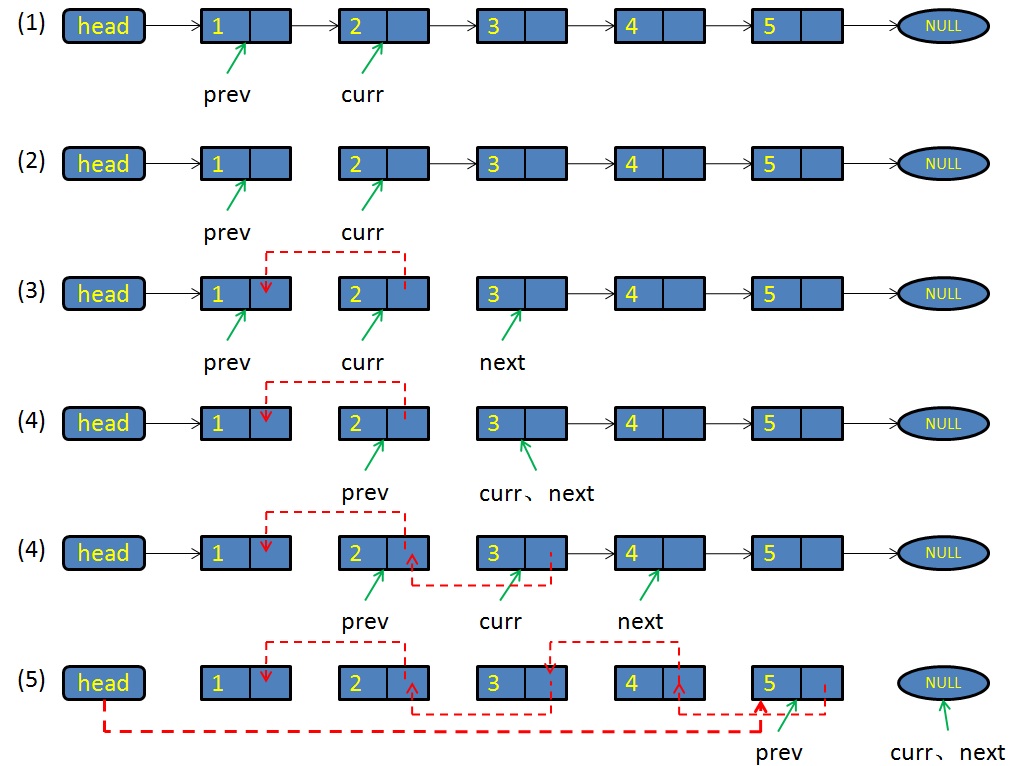
图:单链表倒置
(1)初始状态:prev = head->next; curr = prev->next;
(2)让链表的第一个结点的next指针指向空
(3)开始进入循环处理,让next指向curr结点的下一个结点;再让curr结点的next指针指向prev。即:next = curr->next; curr->next = prev;
(4)让prev、curr结点都继续向后移位。即:prev = curr; curr = next;
(5)重复(3)、(4)动作,直到curr指向空。这时循环结束,让haed指针指向prev,此时的prev是倒置后的第一个结点。即:head->next = prev;
template<class T>
void LinkList<T>::Reverse()
{
LinkNode<T> *pre = head->next;
LinkNode<T> *curr = pre->next;
LinkNode<T> *next = NULL; head->next->next = NULL;
while (curr)
{
next = curr->next;
curr->next = pre;
pre = curr;
curr = next;
} head->next = pre;
}
单链表的C++实现(采用模板类)的更多相关文章
- 数据结构-链表逆置(c++模板类实现)
链表结点类模板定义: template <class T> class SingleList; template <class T> class Node { private: ...
- 单链表数据结构 - java简单实现
链表中最简单的一种是单向链表,每个元素包含两个域,值域和指针域,我们把这样的元素称之为节点.每个节点的指针域内有一个指针,指向下一个节点,而最后一个节点则指向一个空值.如图就是一个单向链表 一个单向链 ...
- php数据结构课程---2、链表(php中 是如何实现单链表的(也就是php中如何实现对象引用的))
php数据结构课程---2.链表(php中 是如何实现单链表的(也就是php中如何实现对象引用的)) 一.总结 一句话总结: php是弱类型语言,变量即可表示数值,也可表示对象:链表节点的数据域的值就 ...
- 单链表的模板类(C++)
/*header.h*/#pragma once #include<iostream> using namespace std; template<class T> struc ...
- C++ 单链表模板类实现
单链表的C语言描述 基本运算的算法——置空表.求表的长度.取结点.定位运算.插入运算.删除运算.建立不带头结点的单链表(头插入法建表).建立带头结点的单链表(尾插入法建表),输出带头结点的单链表 #i ...
- 数据结构图文解析之:数组、单链表、双链表介绍及C++模板实现
0. 数据结构图文解析系列 数据结构系列文章 数据结构图文解析之:数组.单链表.双链表介绍及C++模板实现 数据结构图文解析之:栈的简介及C++模板实现 数据结构图文解析之:队列详解与C++模板实现 ...
- 数据结构-单链表-类定义2-C++
上一次的C++链表实现两个单链表的连接不太理想,此次听了一些视频课,自己补了个尾插法,很好的实现了两个链表的连接,当然了,我也是刚接触,可能是C++的一些语法还不太清楚,不过硬是花了一些时间尽量在数据 ...
- C++中的链表节点用模板类和用普通类来实现的区别
C++中的链表节点通常情况下类型都是一致的.因此我们可以用模板来实现. #include <iostream> using namespace std; template<typen ...
- C++实现一个单例模板类
单例模式在项目开发中使用得比较多,一个单例的模板类显得很有必要,避免每次都要重复定义一个单例类型 //非多线程模式下的一个单例模板类的实现 // template_singleton.h #inclu ...
随机推荐
- 获取Canvas当前坐标系矩阵
前言 在我的另一篇博文 Canvas坐标系转换 中,我们知道了所有的平移缩放旋转操作都会影响到画布坐标系.那在我们对画布进行了一系列操作之后,怎么再知道当前矩阵数据状态呢. 具体代码 首先请看下面的一 ...
- SQL Server-聚焦APPLY运算符(二十七)
前言 其实有些新的特性在SQL Server早就已经出现过,但是若非系统的去学习数据库你会发现在实际项目中别人的SQL其实是比较复杂的,其实利用新的SQL Server语法会更加方便和简洁,从本节开始 ...
- 【详细教程】论android studio中如何申请百度地图新版Key中SHA1值
一.写在前面 现在越来越多的API接口要求都要求提供我们的项目SHA1值,开发版目前还要求不高,但是发布版是必定要求的.而目前定位在各大APP中也较为常见,当下主流的百度地图和高德地图都在申请的时候会 ...
- 在DevExpress程序中使用GridView直接录入数据的时候,增加列表选择的功能
在我上篇随笔<在DevExpress程序中使用Winform分页控件直接录入数据并保存>中介绍了在GridView以及在其封装的分页控件上做数据的直接录入的处理,介绍情况下数据的保存和校验 ...
- IdentityServer4 使用OpenID Connect添加用户身份验证
使用IdentityServer4 实现OpenID Connect服务端,添加用户身份验证.客户端调用,实现授权. IdentityServer4 目前已更新至1.0 版,在之前的文章中有所介绍.I ...
- 简单酷炫的canvas动画
作为一个新人怀着激动而紧张的心情写了第一篇帖子还请大家多多支持,小弟在次拜谢. 驯鹿拉圣诞老人动画效果图如下 html如下: <div style="width:400px;heigh ...
- BPM配置故事之案例14-数据字典与数据联动
小明遇到了点麻烦,他昨天又收到了行政主管发来的邮件,要求把出差申请单改由H3 BPM进行,表单如下 行政主管的出差申请表 小明对表单进行了调整,设计出了一份适合在系统中使用的表单,但在"出差 ...
- Lesson 23 A new house
Text I had a letter from my sister yesterday. She lives in Nigeria. In her letter, she said that she ...
- 最新Angular2案例rebirth开源
在过去的几年时间里,Angular1.x显然是非常成功的.但由于最初的架构设计和Web标准的快速发展,逐渐的显现出它的滞后和不适应.这些问题包括性能瓶颈.滞后于极速发展的Web标准.移动化多平台应用, ...
- 【MSP是什么】MSP认证之成功的项目群管理
同项目管理相比,项目群管理是为了实现项目群的战略目标与利益,而对一组项目进行的统一协调管理. 项目群管理 项目群管理是以项目管理为核心.单个项目上进行日常性的项目管理,项目群管理是对多个项目进行的总体 ...