过度拟合(overfitting)
我们之前解决过一个理论问题:机器学习能不能起作用?现在来解决另一个理论问题:过度拟合。
正如之前我们看到的,很多时候我们必须进行nonlinear transform。但是我们又无法确定Q的值。Q过小,那么Ein会很大;Q过大,就会出现过度拟合问题。如下图所示:
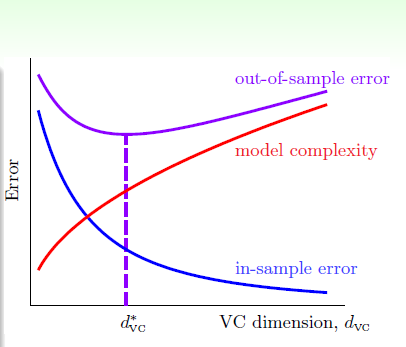
那么overfitting具体受什么因素影响呢?
现在我们又两个例子:

第一个例子的数据来源是:一个10-th的目标函数+noise;第二个例子的数据来源是:一个50-th的目标函数。现在我们用2-th函数(H2)和10-th函数(H10)分别对两个例子进行拟合。我们来预测一下结果。
我认为:对于这两个例子来说,H10效果会更好。因为无论是对于第一个例子还是第二个例子,从阶数上来说,H10都不存在overfitting问题。
下面是真正的结果:

我们可以看出,对于两个例子,都是H2效果最好。
通过这个违反直觉的例子,我们可以一窥overfitting的端倪。

通过这个学习曲线,我们可以看出,H10可以结果很好,但是是建立在N足够大的基础上;如果N很小的话,还是H2的结果好!
补充一点:对于第二个例子,明明没有noise,为什么H10表现的不如H2呢?
因为50-th的复杂度太高,H10和H2都无法准确地拟合。此时目标函数的复杂度对于H2和H10来说,就相当于noise。
我们现在认为数据点数N、noise、还有目标函数的complexity level(阶数)Q都会影响overfitting。
下面进行详细说明。

从这个目标函数中,产生数据,然后用H2和H10去拟合。什么时候我们说会发生过度拟合呢?当使用H10得到的Eout大于使用H2得到的Eout,则必然发生了过度拟合,也即:overfit measure:Eout(g10)-Eout(g2)。

对于第一幅图,Q=20。我们可以很容易看到:1)N越小,noise越大,越容易发生过度拟合。2)当N很小的时候(此处为N<80),必然会发生过度拟合;3)当N很大,noise越大,越容易发生过度拟合。 N起到决定性作用。
对于第二幅图,noise固定。我们可以很容易看到:1)N约小,Q越大,越容易发生过度拟合;2)当N很小的时候,几乎必然会发生过度拟合;
第一幅图和第二幅图有所不同:1)对于左下方那一块红色区域,因为目标函数阶数足够小的时候,肯定会发生过度拟合。然而为什么随着N增加,反而不会有过度拟合了呢?2)当阶数够大,N很小的时候,就会发生过度拟合,但是一旦N足够大(此处N>100),就不会发生过度拟合了;
我们把noise成为stochastic noise,把Q成为deterministic noise。
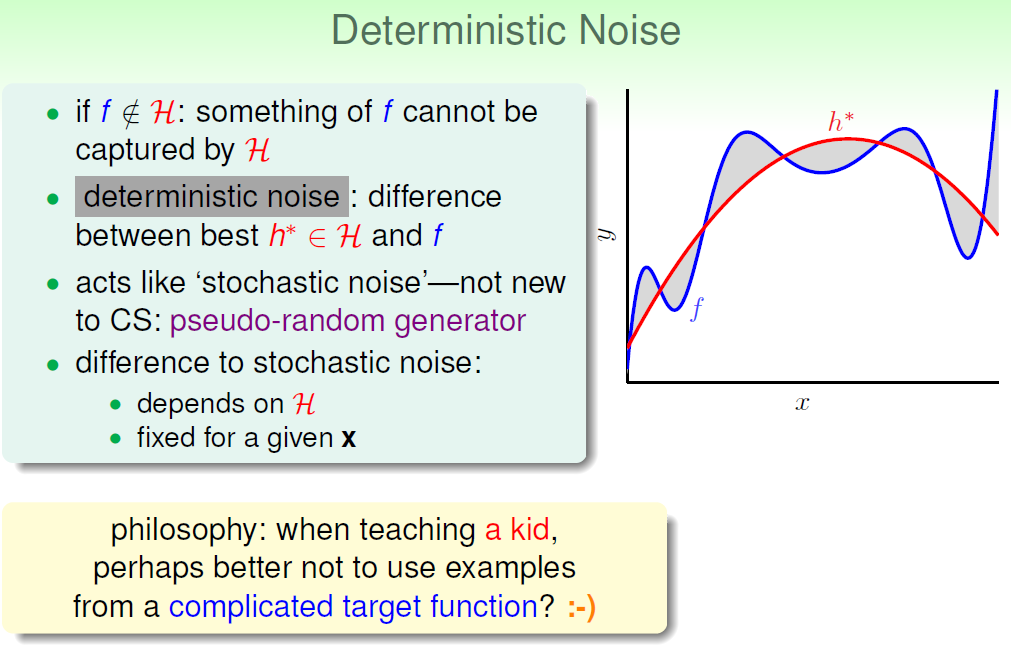
overfitting的几个影响因素,N(最重要),noise,Q。
如何解决overfitting问题呢?
我们把overfitting比作出了一起车祸,出车祸的原因可能是:开的太快了、路上有很多坑、路上的标识太少。与此对应的overfitting原因是:dvc太大(Q太大)、noise太多、数据量太少。
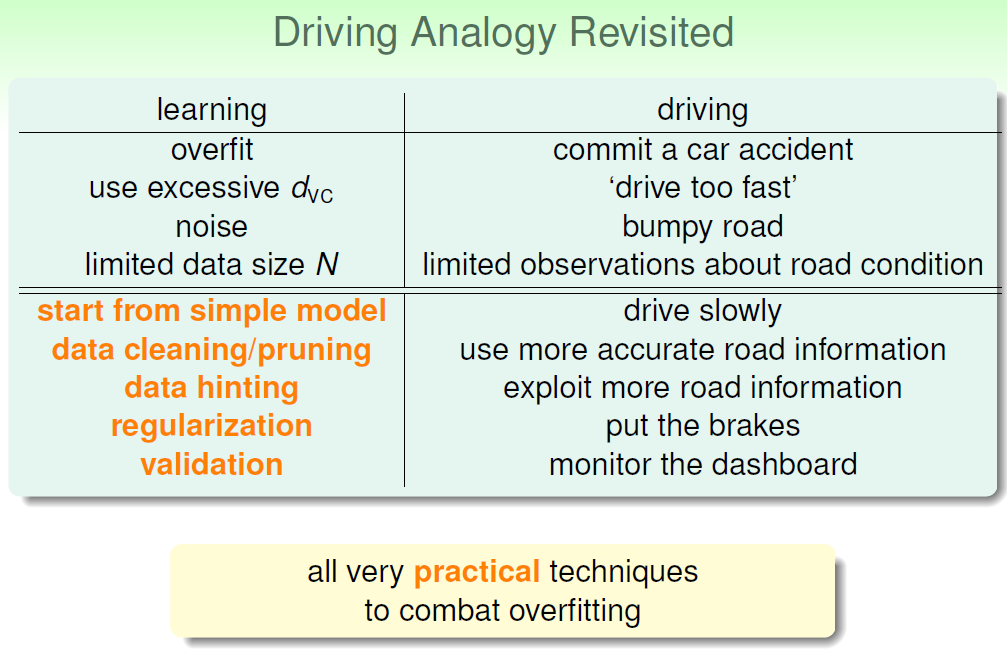
怎么避免“这起车祸”呢?可以开得慢一点,避开路面上的坑坑洼洼、或者是多获取一些路面标识。亦或者踩刹车、多看看仪表盘。
开的慢一点:从simple model开始;
避开路面坑坑洼洼:data cleaning:修正有noise的数据;data pruning:删除有noise的数据。
多获取路面标识:获取更多的数据(有可能无法实现);或者采用Data Hinting技术;
踩刹车:regularization;
看仪表盘:validation。
后两个之后会详细讲述。

过度拟合(overfitting)的更多相关文章
- overfitting(过度拟合)的概念
来自:http://blog.csdn.net/fengzhe0411/article/details/7165549 最近几天在看模式识别方面的资料,多次遇到“overfitting”这个概念,最终 ...
- 过拟合(Overfitting)和正规化(Regularization)
过拟合: Overfitting就是指Ein(在训练集上的错误率)变小,Eout(在整个数据集上的错误率)变大的过程 Underfitting是指Ein和Eout都变大的过程 从上边这个图中,虚线的左 ...
- 过度拟合(overfilting)
过拟合概念:是指分类器能够百分之百的正确分类样本数据(训练集中的样本数据),对训练集以外的数据却不能够正确分类. 原因:1:模型(算法)太过复杂,比如神经网络,算法太过精细复杂,规则太过严格,以至于任 ...
- tensorflow学习4-过拟合-over-fitting
过拟合: 真实的应用中,并不是让模型尽量模拟训练数据的行为,而是希望训练数据对未知做出判断. 模型过于复杂后,模型会积极每一个噪声的部分,而不是学习数据中的通用 趋势.当一个模型的参数比训练数据还要多 ...
- 使用 AdaBoost 元算法提高分类器性能
前言 有人认为 AdaBoost 是最好的监督学习的方式. 某种程度上因为它是元算法,也就是说它会是几种分类器的组合.这就好比对于一个问题能够咨询多个 "专家" 的意见了. 组合的 ...
- 【Todo】【转载】深度学习&神经网络 科普及八卦 学习笔记 & GPU & SIMD
上一篇文章提到了数据挖掘.机器学习.深度学习的区别:http://www.cnblogs.com/charlesblc/p/6159355.html 深度学习具体的内容可以看这里: 参考了这篇文章:h ...
- Machine Learning - 第3周(Logistic Regression、Regularization)
Logistic regression is a method for classifying data into discrete outcomes. For example, we might u ...
- Python中Gradient Boosting Machine(GBM)调参方法详解
原文地址:Complete Guide to Parameter Tuning in Gradient Boosting (GBM) in Python by Aarshay Jain 原文翻译与校对 ...
- 吴恩达-coursera-机器学习-week3
六.逻辑回归(Logistic Regression) 6.1 分类问题 6.2 假说表示 6.3 判定边界 6.4 代价函数 6.5 简化的成本函数和梯度下降 6.6 高级优化 6.7 多类别分类: ...
随机推荐
- Qt 添加外部库文件(四种方法)
Qt添加外部库文件, 一种就是直接加库文件的绝对路劲,这种方法简单,但是遇到多个库文件的时候,会很麻烦,而且,如果工程移动位置以后还需要重新配置 另一种就是相对路径了,不过Qt 编译的文件会在一个单独 ...
- 深度卷积神经网络用于图像缩放Image Scaling using Deep Convolutional Neural Networks
This past summer I interned at Flipboard in Palo Alto, California. I worked on machine learning base ...
- Mac + IDEA + JRebel破解方法.
[重要提示]---最佳人生 一.只推荐当计算机无法访问互联网时使用本破解文件. 二.如果可以访问互联网,建议直接到JRebel官网注册JRebel会员获取[正版永久免费]使用的授权码.JRebel会员 ...
- IOS判断手机型号
#define iPhone5 ([UIScreen instancesRespondToSelector:@selector(currentMode)] ? CGSizeEqualToSize(CG ...
- c#里面的namespace基础(一)
我现在感到学好C#就是就是要知道,C#的基本语法,C#的新的特点,C#能干什么! 其中我感到不管如何,NAMESPACE都是很关键的,可以说不是只对C#而言,而是整个.NET都是由NAMESPACE组 ...
- js自动判断浏览器类型跳转到手机版
//电脑版头部写法:<script language="javascript"> function is_mobile() { var regex_match = /( ...
- [LA 3887] Slim Span
3887 - Slim SpanTime limit: 3.000 seconds Given an undirected weighted graph G <tex2html_verbatim ...
- 转:MVC2表单验证失败后,直接返回View,已填写的内容就会清空,可以这样做;MVC2输出文本;MVC2输出PDF文件
ViewData.ModelState.AddModelError("FormValidator", message); foreach (string field in Requ ...
- mysql 分页存储过程 一次返回两个记录集(行的条数,以及行记录),DataReader的Read方法和NextResult方法
DELIMITER $$ USE `netschool`$$ DROP PROCEDURE IF EXISTS `fn_jk_GetCourses`$$ CREATE DEFINER=`root`@` ...
- Unit testing Cmockery 简单使用
/********************************************************************** * Unit testing Cmockery 简单使用 ...