sqlite索引的原理
引言
这篇文章,里面讲到对于一个41G大小、包含百万条记录的数据库进行查询操作,如果利用了索引,可以把操作耗时从37s降到0.2s。
那么什么是索引呢?利用索引可以加快数据库查询操作的原理是什么呢?
索引的基本原理
数据库提供了一种持久化的数据存储方式,从数据库中查询数据库是一个基本的操作,查询操作的效率是很重要的。
对于查询操作来说,如果被查询的数据已某种方式组织起来,那么查询操作的效率会极大提高。
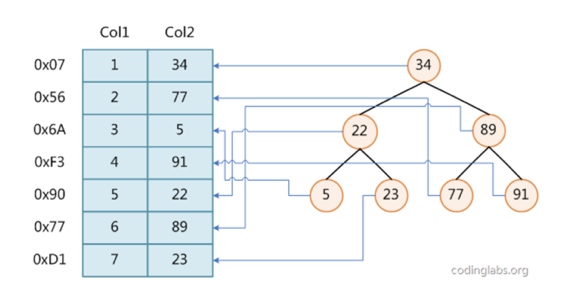
在数据库中,一条记录会有很多列。如果把这些记录按照列Col1以某种数据结构组织起来,那么列Col2一定是乱序的。
因此,数据库在原始数据之外,维护了满足特定查找算法的数据结构,指向原始数据,称之为索引。
举例来说,在下面的图中,数据库有两列Col1、Col2。在存储时,按照列Col1组织各行,比如Col1已二叉树方式组织。如果查找col1中的某一个值,利用二叉树进行二分查找,不需要遍历整个数据库。
这样一来列Col2就是乱序的。为了解决这个问题,为Col2建立了索引,即把Col2也按照某种数据结构(这里是二叉树)组织起来。这样子查找列Col2时只需要进行二分查找即可。

索引的实现
由于数据库是存储在磁盘上的,因此实现索引用的数据结构会存储在磁盘上。磁盘的IO是需要注意的问题。
- 二叉树
二叉树是一种经典的数据结构,但是并不适合进行数据库索引。
原因在于二叉树中每一个节点的度只有2,树的深度较高。在存储时,一般一个节点需要一次磁盘IO,树的深度较高,查询一个数据需要的磁盘IO次数越高,查找需要的时间越长。 B树
B树是二叉树的变种,主要区别在于每一个节点的度可以大于2,即每一个节点可以分很多叉,大大降低了树的深度。
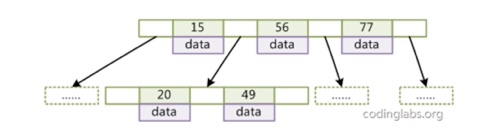 
- 每条数据表示为[key,data]
- 每个非叶子节点有(n-1)条数据n个指针组成
- 所有叶节点具有相同的深度,等于树高h
- 指针指向节点的key大于左边的记录小于右边记录
上面这些特点使得B+树的深度大大降低,并且实现了对数据的有序组织。
B+树
B+树是对B树的扩展,特点在于非叶子节点不存储data,只存储key。如果每一个节点的大小固定(如4k,正如在sqlite中那样),那么可以进一步提高内部节点的度,降低树的深度。
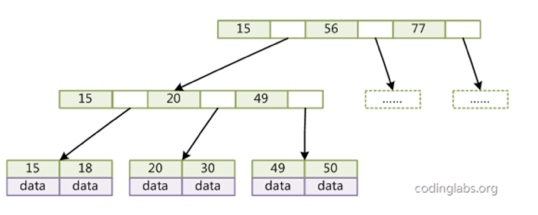 
- 非叶子节点只存储key,叶子节点不存储指针
- 每一个节点大小固定,需要一次读磁盘操作(page)
顺序访问指针的B+树
对B+树做了一点改变,每一个叶子节点增加一个指向相邻叶子节点的指针,这样子可以提高区间访问的性能。
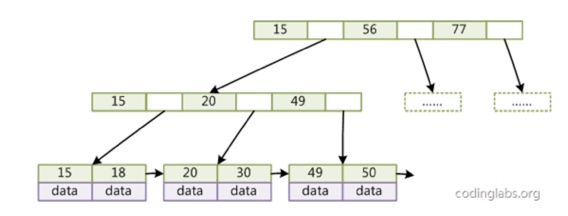 

如图,访问key在15到30的data。- 如果没有水平的指针
B+树查找找到key=15的data,在同一个块中找到key=18的data。然后进行第二次B+查找,找到key=20的data,在同一个块中找到key=30的data。 - 有水平的指针
B+树查找找到key=15的data,查找同一个块的内容,或沿着水平指针依次向右遍历。
- 如果没有水平的指针
Sqlite中数据存储方式
- 表(table)和索引(Index)都是带顺序访问指针的B+树
- table对应的B+树中,key是rowid,data是这一行其他列数据(sqlite为每一行分配了一个rowid)
- index对应的B+树种,key是需要索引的列,data是rowid
根据索引查找数据时,分两步
- 根据索引找到rowid(第一次B+树查找)
- 根据rowid查找其他列的数据(第二次B+树查找)
通过两次B+树查找避免了一次全表扫描。
1. 对某一行或某几行添加PRIMARY KEY或UNIQUE约束,那么数据库会自动为这些列创建索引
2. 指定某一列为INTEGER PRIMARY KEY,那么这一列和rowid被指定为同一列。即可以通过rowid来获取,也可以通过列名来获取。
一个例子
下面是一个数据库中一个表的统计信息,通过sqlite3_analyzer工具得到。
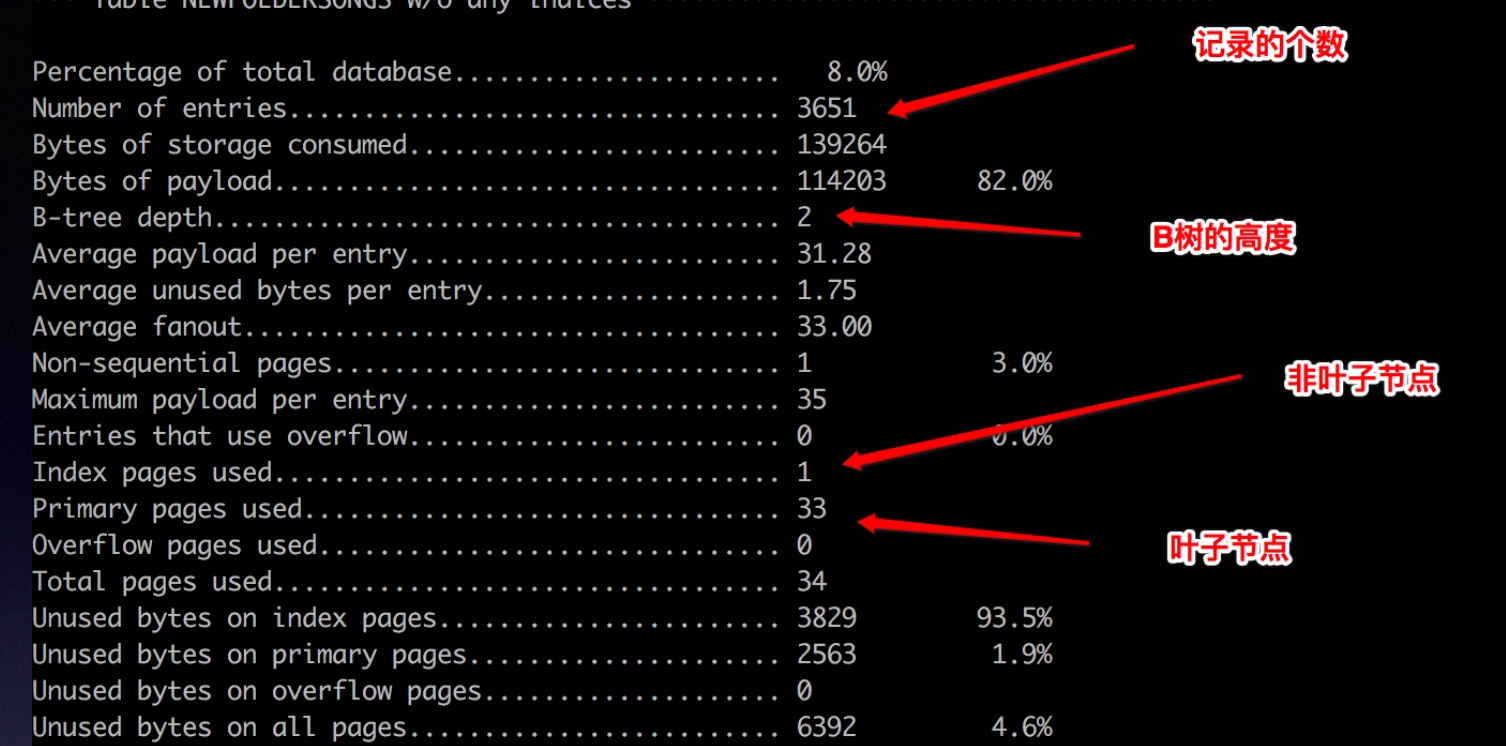 

可以看到表中一共有3651条记录,B树的深度只有2,有33个叶子节点,1个非叶子节点。因此最多只需要2次磁盘IO就可以根据rowid找到一行的数据。
利用索引提高查找效率
比如我们有这么一个表
 

benchmark
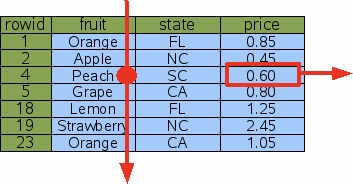
查询语句如下SELECT price FROM fruitsforsale WHERE fruit=‘Peach’
由于没有索引,因此不得不做一次全表扫描。通过顺序访问指针遍历各个记录(record),比较fruit这一列和‘peatch’是否一致,如果一致,返回这一行的price列的值。
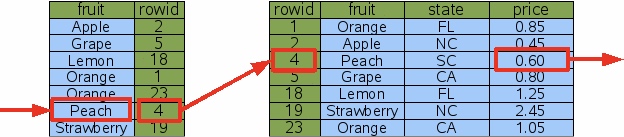
对‘fruit’列加索引
如下,运行同样的语句,可以根据索引找到目标列对应的rowid为4,然后根据rowid找到对应行,从而选出price。通过两次B+树查找避免了全表查找。这也是最简单的情况
多条索引命中
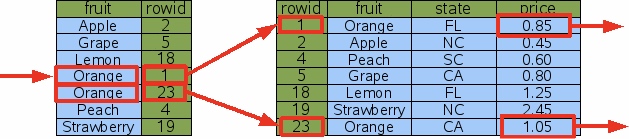
建立索引时,不要求索引是uique的,即索引表中的key可以是一样的。
如下图,索引表中有orange两条记录,找到第一条记录时,根据顺序访问指针可以轻易找到下一条索引,避免另一次B+树查找。(rowid=1和rowid=23可能位于两个不同的叶子节点中)
即这个查找索引的过程,可以通过一次B+树查和一次next操作完成,而next操作是很快的。
利用索引加快搜索和排序
在大多情况下,我们需要同时进行查找和排序操作,这时如果建立适当的索引,可以提高查找效率。
比如下面表中对fruit和state两列做了索引,运行下面的sql语句时,就不需要进行排序操作了,因为索引表是带有顺序的。SELECT price FROM fruitforsale WHERE fruit='Orange' ORDER BY state
 

解释引言中问题
在sqlite中有一个命令叫做explain query plan,可以查看sqlite是如何执行查找操作的。下面的数据库语句不是引言中的查询语句,原理一样
37s的操作(没有用索引)
 
0.2s的操作(用了索引)
 

注意detail列。不用索引时,使用的是“SCAN”这个词,即全表扫描。使用索引时,使用的是“SEARCH”这个词。
对于一个41G的表来说,进行全表扫描的代价显然是很大的。
参考链接
- 浅谈算法和数据结构: 十 平衡查找树之B树
- MySQL索引背后的数据结构及算法原理
- Query Planning(这篇是sqlite关于索引的文档)
- EXPLAIN QUERY PLAN
- MySQL单表百万数据记录分页性能优化
sqlite索引的原理的更多相关文章
- MYSQL索引结构原理、性能分析与优化
[转]MYSQL索引结构原理.性能分析与优化 第一部分:基础知识 索引 官方介绍索引是帮助MySQL高效获取数据的数据结构.笔者理解索引相当于一本书的目录,通过目录就知道要的资料在哪里, 不用一页一页 ...
- Ceph对象存储网关中的索引工作原理<转>
Ceph 对象存储网关允许你通过 Swift 及 S3 API 访问 Ceph .它将这些 API 请求转化为 librados 请求.Librados 是一个非常出色的对象存储(库)但是它无法高效的 ...
- Lucene 的索引文件锁原理
Lucene 的索引文件锁原理 2016/11/24 · IT技术 · lucene 环境 Lucene 6.0.0Java “1.8.0_111”OS Windows 7 Ultimate 线程 ...
- Mysql-如何正确的使用索引以及索引的原理
一. 介绍 二. 索引的原理 三. 索引的数据结构 四. 聚集索引与辅助索引 五. MySQL索引管理 六. 测试索引 七. 正确使用索引 八. 联合索引与覆盖索引 九. 查询优化神器-explain ...
- 【原创】MySQL(Innodb)索引的原理
引言 回想四年前,我在学习mysql的索引这块的时候,老师在讲索引的时候,是像下面这么说的 索引就像一本书的目录.而当用户通过索引查找数据时,就好比用户通过目录查询某章节的某个知识点.这样就帮助用户有 ...
- MongoDB优化,建立索引实例及索引机制原理讲解
MongoDB优化,建立索引实例及索引机制原理讲解 为什么需要索引? 当你抱怨MongoDB集合查询效率低的时候,可能你就需要考虑使用索引了,为了方便后续介绍,先科普下MongoDB里的索引机制(同样 ...
- Sql Server索引的原理与应用
SqlServer索引的原理与应用 转自:http://www.cnblogs.com/knowledgesea/p/3672099.html 索引的概念 索引的用途:我们对数据查询及处理速度已成 ...
- 【转】由浅入深探究mysql索引结构原理、性能分析与优化
摘要: 第一部分:基础知识 第二部分:MYISAM和INNODB索引结构 1.简单介绍B-tree B+ tree树 2.MyisAM索引结构 3.Annode索引结构 4.MyisAM索引与Inno ...
- 重新学习MySQL数据库4:Mysql索引实现原理
重新学习Mysql数据库4:Mysql索引实现原理 MySQL索引类型 (https://www.cnblogs.com/luyucheng/p/6289714.html) 一.简介 MySQL目前主 ...
随机推荐
- 判断一个对象是jQuery对象还是DOM对象
今天调试一段代码的时候,看到其中一个变量,想知道它到底是jquery对象还是dom对象. 虽然直接console出这个对象,看它的内部可以判断出来.但是我想有没有什么更方便的方法呢. 后来我想到了一个 ...
- Netty构建分布式消息队列实现原理浅析
在本人的上一篇博客文章:Netty构建分布式消息队列(AvatarMQ)设计指南之架构篇 中,重点向大家介绍了AvatarMQ主要构成模块以及目前存在的优缺点.最后以一个生产者.消费者传递消息的例子, ...
- Cowboy 开源 WebSocket 网络库
Cowboy.WebSockets 是一个托管在 GitHub 上的基于 .NET/C# 实现的开源 WebSocket 网络库,其完整的实现了 RFC 6455 (The WebSocket Pro ...
- 闲话RPC调用
原创文章转载请注明出处:@协思, http://zeeman.cnblogs.com 自SOA架构理念提出以来,应用程序间如何以最低耦合度通信的问题便呈现在所有架构师面前. 互联网系统的复杂度让我们不 ...
- 日向blog开发记录
一点历史关于,Sonne Blog 2016.03.25springmvc + hibernate框架搭建.2016.04.21日向blog首页.2016.04.24分页实现.2016.04.30登录 ...
- Javascript之变量作用域
分析: 无论是强类型语言c#.c++.java等语言,还是弱类型语言如Javascript,所有变量可以抽象为两种类型,即局部变量和全局变量. 全局变量:整个作用域可见. 局部变量:局部可见,退出作用 ...
- SI与EMI(一) - 反射是怎样影响EMI
Mark为期两天的EMC培训中大概分成四个时间差不多的部分,简单来说分别是SI.PI.回流.屏蔽.而在信号完整性的书籍中,也会把信号完整性分为:1.信号自身传输的问题(反射,损耗):2.信号与信号之间 ...
- Unicode和UTF-8的关系
Unicode和UTF-8都是表示编码,这个我一直都知道,但是这两个实际上是干什么用的,到底是怎么编码的,为什么有了Unicode还要UTF-8,它们之间有什么联系又有什么区别呢?这个问题一直困扰着我 ...
- SQL Saturday 北京将于7月25日举办线下活动,欢迎参加
地点:北京微软(中国)有限公司[望京利星行],三层308室 报名地址:https://onedrive.live.com/redir?page=survey&resid=f ...
- Redis数据结构详解之List(二)
序言 思来想去感觉redis中的list没什么好写的,如果单写几个命令的操作过于乏味,所以本篇最后我会根据redis中list数据类型的特殊属性,同时对比成熟的消息队列产品rabbitmq,使用red ...