hadoop之hdfs学习
简介
HDFS(Hadoop Distributed File System )Hadoop分布式文件系统。是根据google发表的论文翻版的。论文为GFS(Google File System)Google 文件系统(中文,英文)。
HDFS有很多特点:
① 保存多个副本,且提供容错机制,副本丢失或宕机自动恢复。默认存3份。
② 运行在廉价的机器上。
③ 适合大数据的处理。多大?多小?HDFS默认会将文件分割成block,64M为1个block。然后将block按键值对存储在HDFS上,并将键值对的映射存到内存中。如果小文件太多,那内存的负担会很重。
元素
1、Namenode元素:在core-site.xml中进行参数的配置
Namenode是整个文件系统的管理节点。它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表。接收用户的操作请求。
文件包括:
fsimage:元数据镜像文件。存储某一时段NameNode内存元数据信息。
edits:操作日志文件。
fstime:保存最近一次checkpoint的时间
以上这些文件是保存在linux的文件系统中。
2、SecondaryNameNode元素:在masters中进行参数的配置
SecondaryNameNode从NameNode上下载元数据信息(fsimage,edits),然后把二者合并,生成新的fsimage,在本地保存,并将其推送到NameNode,同时重置NameNode的edits.
3、Datanode元素:在hdfs-site.xml中进行参数的配置
DataNode提供真实文件数据的存储服务,它有一个文件块block的概念。
文件块(block):最基本的存储单位。对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,
划分好的每一个块称一个Block。HDFS默认Block大小是64MB,以一个256MB文件,共有256/64=4个Block.
不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占用整个数据块存储空间
Replication。多复本。默认是三个
设计模型
HDFS的设计如下图所示:
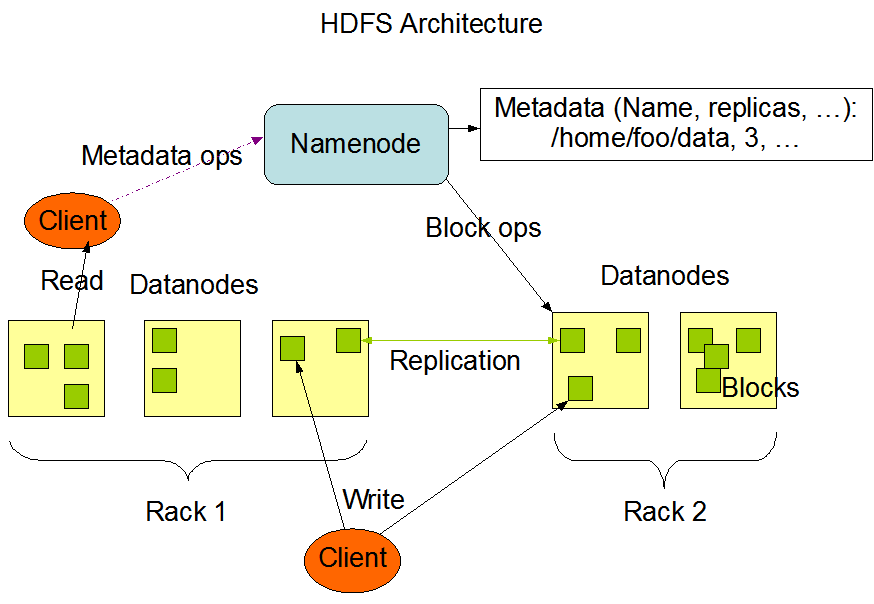
Write请求描述:client请求namenode,在namenode保存相关的元数据信息,然后client将数据写到对于的datanode,同时datanode每个block备份到其他的主机上,
Read请求描述:Client请求namenode,获取数据的元数据信息,然后client到对应的datanode读取block,如果该block数据损坏或者对应的主机出问题,client就会去其他datanode读取block。
元元数据信息:文件的大小,创建时间,位置信息以及分块信息等等
总之:不管是Write还是Read,Client都会先请求namenode,获取元数据信息以后再对Datanode进行操作
JAVA操作:
package cn.edu.hadoop.hdfs; import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.net.URI;
import java.net.URISyntaxException;
import java.net.URL; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils; public class HDFSTest {
public static String url = "hdfs://master:9000"; public static void main(String[] args) throws IOException, URISyntaxException {
//test1();
test2();
} /**
* java api操作
* @throws IOException
*/
public static void test1() throws IOException{
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
String filePath = url+"/user/file";
URL url =new URL(filePath);
InputStream in = url.openStream();
/**
* in 输入流
* out 输出流
* bufferSize 缓冲区
* close 是否关闭流
*/
IOUtils.copyBytes(in, System.out, 1024, true);
} /**
* hdfs api操作
* @throws URISyntaxException
* @throws IOException
*/
public static void test2() throws IOException, URISyntaxException{
FileSystem fileSystem = FileSystem.get(new URI(url), new Configuration());
//创建文件
fileSystem.mkdirs(new Path("/dir"));
//上传文件
FSDataOutputStream out = fileSystem.create(new Path("/dir/hello"));
FileInputStream in = new FileInputStream(new File("C:\\Users\\HeYong\\Desktop\\linux.txt"));
IOUtils.copyBytes(in, out, 1024, true); //下载文件
FSDataInputStream download = fileSystem.open(new Path("/dir/hello"));
IOUtils.copyBytes(download, System.out, 1024, true); /*
* 递归删除文件夹
*/
fileSystem.delete(new Path("/dir"), true);
}
}
hadoop之hdfs学习的更多相关文章
- hadoop之HDFS学习笔记(一)
主要内容:hdfs的整体运行机制,DATANODE存储文件块的观察,hdfs集群的搭建与配置,hdfs命令行客户端常见命令:业务系统中日志生成机制,HDFS的java客户端api基本使用. 1.什么是 ...
- hadoop之HDFS学习笔记(二)
主要内容:hdfs的核心工作原理:namenode元数据管理机制,checkpoint机制:数据上传下载流程 1.hdfs的核心工作原理 1.1.namenode元数据管理要点 1.什么是元数据? h ...
- Hadoop源码学习之HDFS(一)
Hadoop的HDFS可以分为NameNode与DataNode,NameNode存储所有DataNode中数据的元数据信息.而DataNode负责存储真正的数据(数据块)信息以及数据块的ID. Na ...
- Hadoop - HDFS学习笔记(详细)
第1章 HDFS概述 hdfs背景意义 hdfs是一个分布式文件系统 使用场景:适合一次写入,多次读出的场景,且不支持文件的修改. 优缺点 高容错性,适合处理大数据(数据PB级别,百万规模文件),可部 ...
- Hadoop Streaming框架学习2
Hadoop Streaming框架学习(二) 1.常用Streaming命令介绍 使用下面的命令运行Streaming MapReduce程序: 1: $HADOOP_HOME/bin/hadoop ...
- Hadoop Streaming框架学习(一)
Hadoop Streaming框架学习(一) Hadoop Streaming框架学习(一) 2013-08-19 12:32 by ATP_, 473 阅读, 3 评论, 收藏, 编辑 1.Had ...
- Hadoop基础-HDFS的API常见操作
Hadoop基础-HDFS的API常见操作 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 本文主要是记录一写我在学习HDFS时的一些琐碎的学习笔记, 方便自己以后查看.在调用API ...
- Hadoop权威指南学习笔记一
Hadoop简单介绍 声明:本文是本人基于Hadoop权威指南学习的一些个人理解和笔记,仅供学习參考,有什么不到之处还望指出.一起学习一起进步. 转载请注明:http://blog.csdn.net/ ...
- Hadoop源码学习笔记(6)——从ls命令一路解剖
Hadoop源码学习笔记(6) ——从ls命令一路解剖 Hadoop几个模块的程序我们大致有了点了解,现在我们得细看一下这个程序是如何处理命令的. 我们就从原头开始,然后一步步追查. 我们先选中ls命 ...
随机推荐
- 全国计算机等级考试二级教程-C语言程序设计_第16章_文件
写入一段文本到文件 #define _CRT_SECURE_NO_WARNINGS #include<stdio.h> #include<stdlib.h> main() { ...
- vb.net常用函数
当然,这些都可以从MSDN查到,但是有时候打开帮助老慢的,所以先放到这里放一放,查个函数什么的比较快一点.都是从网上搜来的.Abs(number) 取得数值的绝对值. Asc(String) 取得字符 ...
- leetcode Binary Tree Level Order Traversal python
# Definition for a binary tree node. # class TreeNode(object): # def __init__(self, x): # self.val = ...
- 简单的表单验证(js、jquery)
//javascript代码 function valForm(){ var username=document.getElementById("username"); var p ...
- mac使用小技
xcodeブラックスクリーンの解決策: 1.cd ~/Library/Developer/Xcode/DerivedData 2.rm -fr * //注释:-fr和*是分开的3.关闭模拟器,关 ...
- [转载]node.js express 4.x 安装指南,没有自动配置环境变量的问题
前几天express 推出了4.0,得知这个消息,自己尝试了一下,突然发现用以前的文档上的操作出现了各种问题.结果只能去看文档,现在在这个给大家分享下4.0版本的安装. 先说下如果需要用express ...
- PHP静态成员变量和非静态成员变量
数据成员可以分静态变量.非静态变量两种. 静态成员: 静态类中的成员加入static修饰符,即是静态成员.可以直接使用类名+静态成员名访问此静态成员,因为静态成员存在于内存,非静态成员需要实例化才会 ...
- 织梦list文章列表按权重排序
织梦的文章列表按权重排序 DEDECMS(织梦)5.6系统支持文档权重weight排序,可以在模板中使用: {dede:arclist row='10' titlelen='50' orderby=' ...
- 限制转交订单-采购直接批准PO
应用 Oracle Purchasing 层 Level Function 函数名 Funcgtion Name CUXPOXPOEPO 表单名 Form Name POXPOEPO 说明 Des ...
- flex4 日期类型字符串转日期类型(string转Date)(转)
mysql数据库中存储的日期类型通过PHP返回到flex端为字符串类型,这样在flex中进行处理时就必须要将字符串转化为Date类型.如果仅仅是 "年/月/日" 的组合,而没有涉及 ...