Kafka存储机制(转)
转自:https://www.cnblogs.com/jun1019/p/6256514.html
Kafka存储机制
同一个topic下有多个不同的partition,每个partition为一个目录,partition命名的规则是topic的名称加上一个序号,序号从0开始。

每一个partition目录下的文件被平均切割成大小相等(默认一个文件是500兆,可以手动去设置)的数据文件,
每一个数据文件都被称为一个段(segment file),但每个段消息数量不一定相等,这种特性能够使得老的segment可以被快速清除。
默认保留7天的数据。
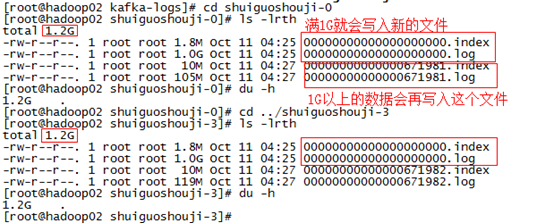
每个partition下都会有这些每500兆一个每500兆一个(当然在上面的测试中我们将它设置为了1G一个)的segment段。
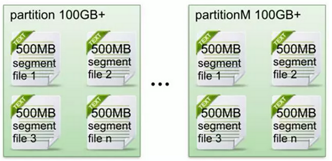
另外每个partition只需要支持顺序读写就可以了,partition中的每一个segment端的生命周期是由我们在配置文件中指定的一个参数觉得的。
比如它在默认情况下,每满500兆就会创建新的segment段(segment file),每满7天就会清理之前的数据。
它的一个特点就是支持顺序写。如下图所示:
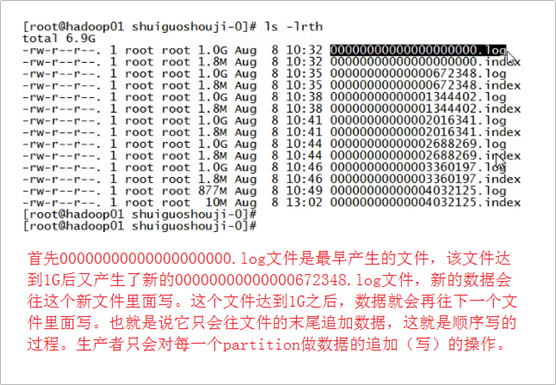
首先00000000000000000000.log文件是最早产生的文件,该文件达到1G(因为我们在配置文件里面指定的1G大小,默认情况下是500兆)
之后又产生了新的0000000000000672348.log文件,新的数据会往这个新的文件里面写,这个文件达到1G之后,数据就会再往下一个文件里面写,
也就是说它只会往文件的末尾追加数据,这就是顺序写的过程,生产者只会对每一个partition做数据的追加(写)的操作。
问题:如何保证消息消费的有序性呢?比如说生产者生产了0到100个商品,那么消费者在消费的时候安装0到100这个从小到大的顺序消费,
那么kafka如何保证这种有序性呢?难度就在于,生产者生产出0到100这100条数据之后,通过一定的分组策略存储到broker的partition中的时候,
比如0到10这10条消息被存到了这个partition中,10到20这10条消息被存到了那个partition中,这样的话,消息在分组存到partition中的时候就已经被分组策略搞得无序了。
那么能否做到消费者在消费消息的时候全局有序呢?遇到这个问题,我们可以回答,在大多数情况下是做不到全局有序的。但在某些情况下是可以做到的。 比如我的partition只有一个,这种情况下是可以全局有序的。那么可能有人又要问了,只有一个partition的话,哪里来的分布式呢?哪里来的负载均衡呢?
所以说,全局有序是一个伪命题!全局有序根本没有办法在kafka要实现的大数据的场景来做到。但是我们只能保证当前这个partition内部消息消费的有序性。 结论:一个partition中的数据是有序的吗?回答:间隔有序,不连续。 针对一个topic里面的数据,只能做到partition内部有序,不能做到全局有序。特别是加入消费者的场景后,如何保证消费者的消费的消息的全局有序性,
这是一个伪命题,只有在一种情况下才能保证消费的消息的全局有序性,那就是只有一个partition!。
Segment file是什么? 生产者生产的消息按照一定的分组策略被发送到broker中partition中的时候,这些消息如果在内存中放不下了,就会放在文件中,
partition在磁盘上就是一个目录,该目录名是topic的名称加上一个序号,在这个partition目录下,有两类文件,一类是以log为后缀的文件,
一类是以index为后缀的文件,每一个log文件和一个index文件相对应,这一对文件就是一个segment file,也就是一个段。
其中的log文件就是数据文件,里面存放的就是消息,而index文件是索引文件,索引文件记录了元数据信息。
说到segment file的索引文件和数据文件的一一对应,我们应该能想到storm中的Ack File机制,在spout发出去的时候要发一个Ack Tuple,
在下游的bolt处理完之后,它也要发一个Ack Tuple,这两个Ack Tuple里面包含了同样一份数据,这个数据叫做MessageId,它是一个对象,
这个对象里面包含两个比较重要的字段,一个是RootId,另一个是TupleId(也叫锚点Id),这个锚点Id会在我们发送数据的时候进行异或一下,
异或的结果才会发送给Ack那个Bolt。

Segment文件命名的规则:partition全局的第一个segment从0(20个0)开始,后续的每一个segment文件名是上一个segment文件中最后一条消息的offset值。 那么这样命令有什么好处呢?假如我们有一个消费者已经消费到了368776(offset值为368776),那么现在我们要继续消费的话,怎么做呢?
看上图,分2个步骤,第1步是从所有文件log文件的的文件名中找到对应的log文件,第368776条数据位于上图中的“00000000000000368769.log”这个文件中,
这一步涉及到一个常用的算法叫做“二分查找法”(假如我现在给你一个offset值让你去找,你首先是将所有的log的文件名进行排序,然后通过二分查找法进行查找,
很快就能定位到某一个文件,紧接着拿着这个offset值到其索引文件中找这条数据究竟存在哪里);第2步是到index文件中去找第368776条数据所在的位置。 索引文件(index文件)中存储这大量的元数据,而数据文件(log文件)中存储这大量的消息。 索引文件(index文件)中的元数据指向对应的数据文件(log文件)中消息的物理偏移地址。
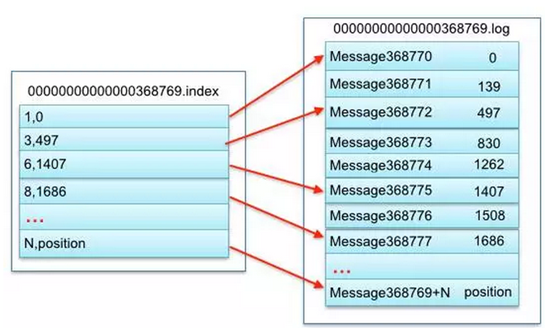
上图的左半部分是索引文件,里面存储的是一对一对的key-value,其中key是消息在数据文件(对应的log文件)中的编号,比如“1,3,6,8……”,
分别表示在log文件中的第1条消息、第3条消息、第6条消息、第8条消息……,那么为什么在index文件中这些编号不是连续的呢?
这是因为index文件中并没有为数据文件中的每条消息都建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。
这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。
但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。 其中以索引文件中元数据3,497为例,其中3代表在右边log数据文件中从上到下第3个消息(在全局partiton表示第368772个消息),
其中497表示该消息的物理偏移地址(位置)为497。
Kafka存储机制(转)的更多相关文章
- kafka存储机制
kafka存储机制 @(博客文章)[storm|大数据] kafka存储机制 一关键术语 二topic中partition存储分布 三 partiton中文件存储方式 四 partiton中segme ...
- Kafka 存储机制和副本
1.概述 Kafka 快速稳定的发展,得到越来越多开发者和使用者的青睐.它的流行得益于它底层的设计和操作简单,存储系统高效,以及充分利用磁盘顺序读写等特性,和其实时在线的业务场景.对于Kafka来说, ...
- kafka存储机制以及offset
1.前言 一个商业化消息队列的性能好坏,其文件存储机制设计是衡量一个消息队列服务技术水平和最关键指标之一.下面将从Kafka文件存储机制和物理结构角度,分析Kafka是如何实现高效文件存储,及实际应用 ...
- Kafka文件的存储机制
Kafka文件的存储机制 同一个topic下有多个不同的partition,每个partition为一个目录,partition命名的规则是topic的名称加上一个序号,序号从0开始. 每一个part ...
- kafka知识体系-kafka设计和原理分析-kafka文件存储机制
kafka文件存储机制 topic中partition存储分布 假设实验环境中Kafka集群只有一个broker,xxx/message-folder为数据文件存储根目录,在Kafka broker中 ...
- Kafka文件存储机制及partition和offset
转载自: https://yq.aliyun.com/ziliao/65771 参考: Kafka集群partition replication默认自动分配分析 如何为kafka选择合适的p ...
- Kafka文件存储机制及offset存取
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- Kafka文件存储机制那些事
Kafka是什么 Kafka是最初由Linkedin公司开发,是一个分布式.分区的.多副本的.多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx ...
- Kafka 文件存储机制那些事 - 美团技术团队
出处:https://tech.meituan.com/2015/01/13/kafka-fs-design-theory.html 自己总结: Kafka 文件存储机制_结构图:https://ww ...
随机推荐
- 关于altera fpga的io时序优化问题
chip planner中一个io的结构如下图所示 其中左边是输出部分右边是输入部分,但是会注意到两个结构:1,寄存器,2,delay模块 以下是我的推测:这两个结构是为了做时序优化时用的,在alte ...
- pyqtree
pyqtree module API Documentation Classes class Index The top spatial index to be created by the user ...
- Kubernetes Helm
Helm is a tool for managing Kubernetes charts. Charts are packages of pre-configured Kubernetes reso ...
- Eclipse的Java开发中jar导入后无法使用包内class的解决方案
请注意, 本方法只对于自己的包有效, 如果你的类内部互相调用, 此方法会失效, 需要每个类文件都进行一次CTRL+SHIFT+O进行包的导入. 如上图的一个结构, algs4.jar和stdlib.j ...
- python官网
https://www.python.org/ https://docs.python.org/2/library/pydoc.html
- 使用Navicat for Oracle新建表空间、用户及权限赋予 (转)
Navicat for Oracle是有关Oracle数据库的客户端工具.通过这个客户端,我们可以图形方式对Oracle数据库进行操作. 说明我们此次试验的Oracle数据库版本是Oracle 10G ...
- 优化html标签
借用Effective之名,开始写Effective系列,总结一些前端的心得. 有些人写页面会走向一个极端,几乎页面所有的标签都用div,究其原因,用div有很多好处,一个是div没有默认样式,不会有 ...
- elasticsearch 6.x 处理一对多关系使用场景
思考:一个用户有多篇博客,如何查询博客作者姓名中带“旺”字.博客标题中带“运”的10篇博客列表 elasticsearch关联模型: 一: 应用层做联接2个索引博客作者.博客发布先从博客作者中查询出符 ...
- 微信卡券开发,代金券修改卡券信息返回40145错误码: invalid update! Can not both set PayCell and CenterCellInfo(include: center_title, center_sub_title, center_url). hint: [DZ9rna0637ent1]
修改代金券,接口返回的数组是这样的内容 Array ( [errcode] => 40145 [errmsg] => invalid update! Can not both set ...
- couchdb的使用例子
couchdb安装 sudo apt-get install erlang sudo apt-get install libmozjs185-dev libicu-dev 下载源码,编译安装 启动以后 ...