hive join的三种优化方式
原网址:https://blog.csdn.net/liyaohhh/article/details/50697519
hive在实际的应用过程中,大部份分情况都会涉及到不同的表格的连接,
例如在进行两个table的join的时候,利用MR的思想会消耗大量的内存,磁盘的IO,大幅度的影响性能,因为shuffle真的好令人担心啊,总之,就是各种问题都是由他产生的。
下面介绍一下涉及hive在join的时候的优化方式。
第一:在map端产生join
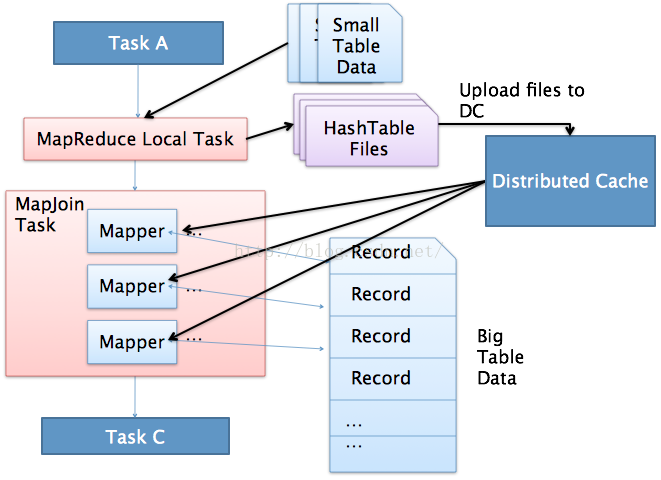
mapJoin的主要意思就是,当链接的两个表是一个比较小的表和一个特别大的表的时候,我们把比较小的table直接放到内存中去,然后再对比较大的表格进行map操作。
join就发生在map操作的时候,每当扫描一个大的table中的数据,就要去去查看小表的数据,哪条与之相符,继而进行连接。
这里的join并不会涉及reduce操作。map端join的优势就是在于没有shuffle,真好。在实际的应用中,我们这样设置:
set hive.auto.convert.join=true;
这样设置,hive就会自动的识别比较小的表,继而用mapJoin来实现两个表的联合。
看看下面的两个表格的连接。这里的dept相对来讲是比较小的。我们看看会发生什么,如图所示:

注意看啦,这里的第一句话就是运行本地的map join任务,继而转存文件到XXX.hashtable下面,在给这个文件里面上传一个文件进行map join,之后才运行了MR代码去运行计数任务。
说白了,在本质上map join根本就没有运行MR进程,仅仅是在内存就进行了两个表的联合。具体运行如下图:
第二:common join
common join也叫做shuffle join,reduce join操作。这种情况下生再两个table的大小相当,但是又不是很大的情况下使用的。
具体流程就是在map端进行数据的切分,一个block对应一个map操作,然后进行shuffle操作,把对应的block shuffle到reduce端去,再逐个进行联合,
这里优势会涉及到数据的倾斜,大幅度的影响性能有可能会运行speculation,
这块儿在后续的数据倾斜会讲到。因为平常我们用到的数据量小,所以这里就不具体演示了。
第三:SMBJoin
smb是sort merge bucket操作,首先进行排序,继而合并,然后放到所对应的bucket中去,bucket是hive中和分区表类似的技术,就是按照key进行hash,相同的hash值都放到相同的buck中去。在进行两个表联合的时候。我们首先进行分桶,在join会大幅度的对性能进行优化。也就是说,在进行联合的时候,是table1中的一小部分和table1中的一小部分进行联合,table联合都是等值连接,相同的key都放到了同一个bucket中去了,那么在联合的时候就会大幅度的减小无关项的扫描。

具体的看看一个例子:
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
create table emp_info_bucket(ename string,deptno int)
partitioned by (empno string)
clustered by(deptno) into 4 buckets;
insert overwrite table emp_info_bucket
partition (empno=7369)
select ename ,deptno from emp
create table dept_info_bucket(deptno string,dname string,loc string)
clustered by (deptno) into 4 buckets;
insert overwrite table dept_info_bucket
select * from dept;
select * from emp_info_bucket emp join dept_info_bucket dept
on(emp.deptno==dept.deptno);//正常的情况下,应该是启动smbjoin的但是这里的数据量太小啦,还是启动了mapjoin
hive join的三种优化方式的更多相关文章
- oracle Hash Join及三种连接方式
在Oracle中,确定连接操作类型是执行计划生成的重要方面.各种连接操作类型代表着不同的连接操作算法,不同的连接操作类型也适应于不同的数据量和数据分布情况. 无论是Nest Loop Join(嵌套循 ...
- hive命令的三种执行方式
hive命令的3种调用方式 方式1:hive –f /root/shell/hive-script.sql(适合多语句) hive-script.sql类似于script一样,直接写查询命令就行 不 ...
- Spark SQL join的三种实现方式
引言 join是SQL中的常用操作,良好的表结构能够将数据分散到不同的表中,使其符合某种规范(mysql三大范式),可以最大程度的减少数据冗余,更新容错等,而建立表和表之间关系的最佳方式就是join操 ...
- 061 hive中的三种join与数据倾斜
一:hive中的三种join 1.map join 应用场景:小表join大表 一:设置mapjoin的方式: )如果有一张表是小表,小表将自动执行map join. 默认是true. <pro ...
- Hive metastore三种配置方式
http://blog.csdn.net/reesun/article/details/8556078 Hive的meta数据支持以下三种存储方式,其中两种属于本地存储,一种为远端存储.远端存储比较适 ...
- Hive总结(八)Hive数据导出三种方式
今天我们再谈谈Hive中的三种不同的数据导出方式. 依据导出的地方不一样,将这些方式分为三种: (1).导出到本地文件系统. (2).导出到HDFS中: (3).导出到Hive的还有一个表中. 为了避 ...
- Hive中的三种不同的数据导出方式介绍
问题导读:1.导出本地文件系统和hdfs文件系统区别是什么?2.带有local命令是指导出本地还是hdfs文件系统?3.hive中,使用的insert与传统数据库insert的区别是什么?4.导出数据 ...
- hive 数据导出三种方式
今天我们再谈谈Hive中的三种不同的数据导出方式.根据导出的地方不一样,将这些方式分为三种:(1).导出到本地文件系统:(2).导出到HDFS中:(3).导出到Hive的另一个表中.为了避免单纯的文字 ...
- Sort merge join、Nested loops、Hash join(三种连接类型)
目前为止,典型的连接类型有3种: Sort merge join(SMJ排序-合并连接):首先生产driving table需要的数据,然后对这些数据按照连接操作关联列进行排序:然后生产probed ...
随机推荐
- 启动图。引导页以及EAIntroView的使用
ios启动图: 1242 x 2208 (6plus) R5.5位置 750 x 1334 (6) R4.7位置 640 x 960 (4/4s) 2x ...
- LA3983 捡垃圾的机器人
Problem C - Robotruck Background This problem is about a robotic truck that distributes mail package ...
- [SoapUI] SOAP UI-Groovy Useful Commands
Hi All, I have posted the SOAPUI and Groovy useful commands that may help you in your testing. Below ...
- 让你大开眼界的10款Android界面设计
根据调查显示, iOS与Android的市场份额差距正越来越大.Android设备正在成为手机应用市场的主力军.如何从设计层面创造一个优美的app界面来吸引用户已然成为广大App开发者们必做的功课之一 ...
- spring.net 继承
. <object id="parent" type="Bll.Parent, HRABLL" > <property name=" ...
- RAW编程接口
LWIP移植好之后,就要使用它提供的API接口来编写程序.
- pagespeed模块安装——Nginx、Tengine
1.安装好nginx或者tengine 2.下载pagespeed模块并且解压 sudo mkdir -p /usr/local/tengine/modules wget https://github ...
- StackExchange.Redis实现Redis发布订阅
由于ServiceStack.Redis最新版已经收费,所以现在大家陆陆续续都换到StackExchange.Redis上了,关于StackExchange.Redis详细可以参看Github htt ...
- 选项“6”对 /langversion 无效;必须是 ISO-1、ISO-2、3、4、5 或 Default
部署MVC的时候,因为服务器.NET版本是4.5.1,所以在vs将.NET版本降到4.5.1的时候发布报错. 原因:C#6降到C#5导致 解决办法:修改web.config配置 ,编译选项改为comp ...
- after modifying system headers, please delete the module cache at
5down votefavorite 2 I don't know how I modified a iOS SDK file, but Xcode say I did. Here is what t ...