python---tornado补充(异步非阻塞)
一:正常访问(同一线程中多个请求是同步阻塞状态)
import tornado.ioloop
import tornado.web
import tornado.websocket
import datetime,time class MainHandler(tornado.web.RequestHandler):
def get(self):
self.write("main")class IndexHandler(tornado.web.RequestHandler):
def get(self):
time.sleep()
self.write("index") st ={
"template_path": "template",#模板路径配置
"static_path":'static',
} #路由映射 匹配执行,否则404
application = tornado.web.Application([
("/main",MainHandler),
("/index",IndexHandler),
],**st) if __name__=="__main__":
application.listen() #io多路复用
tornado.ioloop.IOLoop.instance().start()
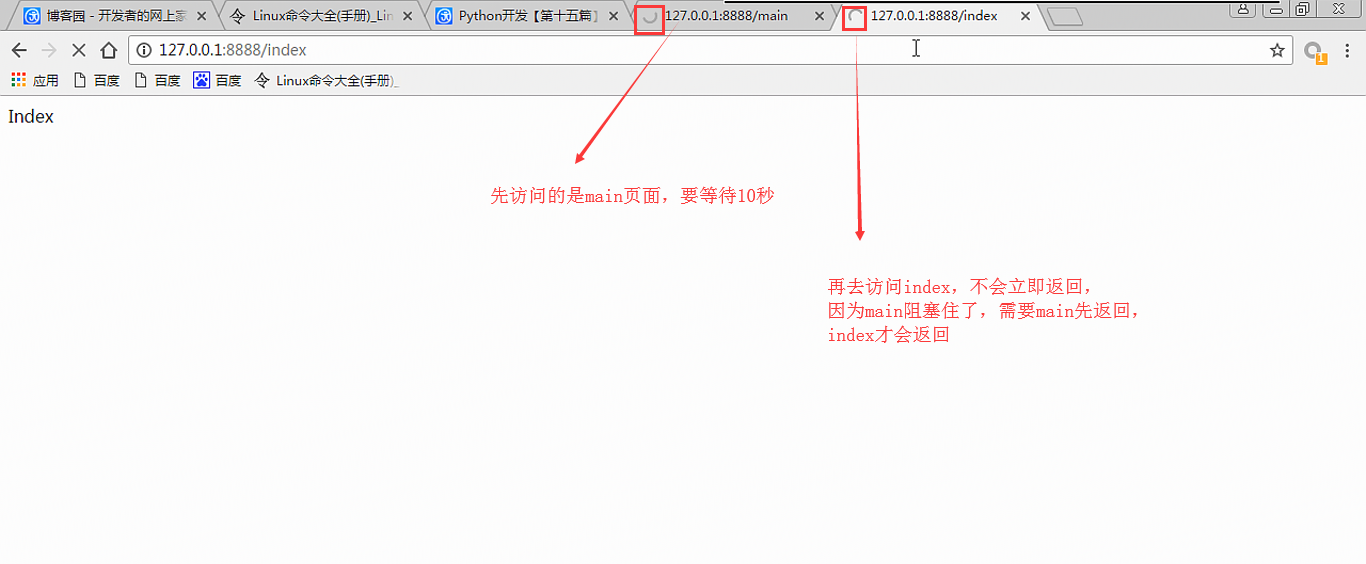
我们先访问index,再去访问main,查看情况
二:使用future模块,实现异步非阻塞
import tornado.ioloop
import tornado.web
import tornado.websocket
import time
from tornado.concurrent import Future class MainHandler(tornado.web.RequestHandler):
def get(self): self.write("main")class IndexHandler(tornado.web.RequestHandler):
def get(self):
future = Future()
tornado.ioloop.IOLoop.current().add_timeout(time.time()+5,self.done) #会在结束后为future中result赋值
yield future def done(self,*args,**kwargs):
self.write("index")
self.finish() #关闭请求连接,必须在回调中完成 st ={
"template_path": "template",#模板路径配置
"static_path":'static',
} #路由映射 匹配执行,否则404
application = tornado.web.Application([
("/main",MainHandler),
("/index",IndexHandler),
],**st) if __name__=="__main__":
application.listen() #io多路复用
tornado.ioloop.IOLoop.instance().start()


三:在tornado中使用异步IO请求模块
import tornado.ioloop
import tornado.web
import tornado.websocket
import time
from tornado.concurrent import Future
from tornado import httpclient
from tornado import gen class MainHandler(tornado.web.RequestHandler):
def get(self): self.write("main") def post(self, *args, **kwargs):
pass class IndexHandler(tornado.web.RequestHandler):
@gen.coroutine
def get(self):
http = httpclient.AsyncHTTPClient()
yield http.fetch("http://www.google.com",self.done) def done(self):
self.write("index")
self.finish() def post(self, *args, **kwargs):
pass st ={
"template_path": "template",#模板路径配置
"static_path":'static',
} #路由映射 匹配执行,否则404
application = tornado.web.Application([
("/main",MainHandler),
("/index",IndexHandler),
],**st) if __name__=="__main__":
application.listen() #io多路复用
tornado.ioloop.IOLoop.instance().start()
四:请求间交互,使用future
import tornado.ioloop
import tornado.web
import tornado.websocket
from tornado.concurrent import Future
from tornado import gen class MainHandler(tornado.web.RequestHandler):
def get(self):
self.write("main") class IndexHandler(tornado.web.RequestHandler):
@gen.coroutine
def get(self):
future = Future()
future.add_done_callback(self.done)
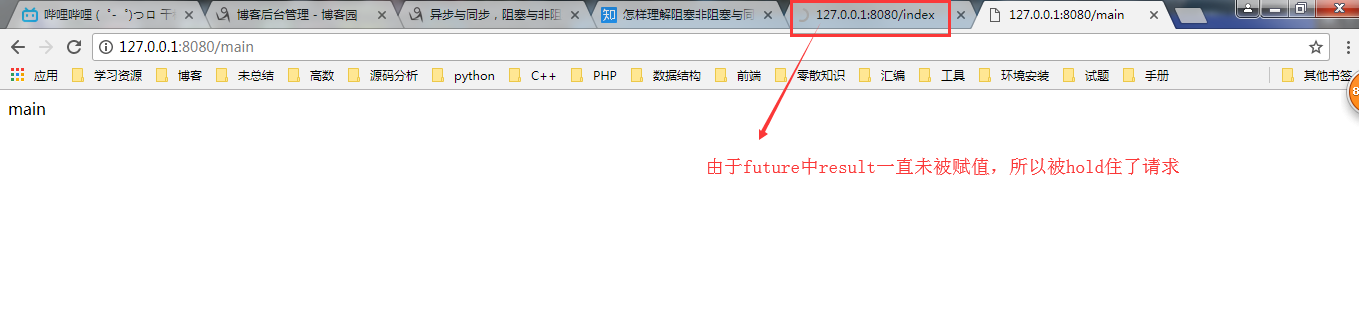
yield future #由于future中的result中值一直未被赋值,所有客户端一直等待
def done(self,*args,**kwargs):
self.write("index")
self.finish() st ={
"template_path": "template",#模板路径配置
"static_path":'static',
} #路由映射 匹配执行,否则404
application = tornado.web.Application([
("/main",MainHandler),
("/index",IndexHandler),
],**st) if __name__=="__main__":
application.listen() #io多路复用
tornado.ioloop.IOLoop.instance().start()
我们可以在另一个请求中去为这个future中result赋值,使当前请求返回

import tornado.ioloop
import tornado.web
import tornado.websocket
from tornado.concurrent import Future
from tornado import gen future = None class MainHandler(tornado.web.RequestHandler):
def get(self):
global future
future.set_result(None) #为Future中result赋值
self.write("main") class IndexHandler(tornado.web.RequestHandler):
@gen.coroutine
def get(self):
global future
future = Future()
future.add_done_callback(self.done)
yield future #由于future中的result中值一直未被赋值,所有客户端一直等待 def done(self,*args,**kwargs):
self.write("index")
self.finish() st ={
"template_path": "template",#模板路径配置
"static_path":'static',
} #路由映射 匹配执行,否则404
application = tornado.web.Application([
("/main",MainHandler),
("/index",IndexHandler),
],**st) if __name__=="__main__":
application.listen() #io多路复用
tornado.ioloop.IOLoop.instance().start()

五:自定义web框架(同步)
# coding:utf8
# __author: Administrator
# date: //
# /usr/bin/env python
import socket
from select import select
import re class HttpResponse(object):
"""
封装响应信息
"""
def __init__(self, content=''):
self.content = content
''' '''
self.status = "HTTP/1.1 200 OK"
self.headers = {}
self.cookies = {} self.initResponseHeader() def changeStatus(self,status_code,status_desc):
self.status = "HTTP/1.1 %s %s"%(status_code,status_desc) def initResponseHeader(self):
self.headers['Content-Type']='text/html; charset=utf-8'
self.headers['X-Frame-Options']='SAMEORIGIN'
self.headers['X-UA-Compatible']='IE=10'
self.headers['Cache-Control']='private, max-age=10'
self.headers['Vary']='Accept-Encoding'
self.headers['Connection']='keep-alive' def response(self):
resp_content = None
header_list = [self.status,]
for item in self.headers.items():
header_list.append("%s: %s"%(item[],item[])) header_str = "\r\n".join(header_list)
resp_content = "\r\n\r\n".join([header_str,self.content])
return bytes(resp_content, encoding='utf-8') class HttpRequest:
def __init__(self,content):
"""content:用户传递的请求头信息,字节型"""
self.content = content
self.header_bytes = bytes()
self.body_bytes = bytes() self.header_str = ""
self.body_str = "" self.header_dict = {} self.method = ""
self.url = ""
self.protocol = "" self.initialize()
self.initialize_headers() def initialize(self):
data = self.content.split(b"\r\n\r\n",)
if len(data) == : #全是请求头
self.header_bytes = self.content
else: #含有请求头和请求体
self.header_bytes,self.body_bytes = data
self.header_str = str(self.header_bytes,encoding="utf-8")
self.body_str = str(self.body_bytes,encoding="utf-8") def initialize_headers(self):
headers = self.header_str.split("\r\n")
first_line = headers[].split(" ")
if len(first_line) == :
self.method,self.url,self.protocol = first_line
for line in headers[:]:
k_v = line.split(":",)
if len(k_v) == :
k,v = k_v
self.header_dict[k] = v def main(request):
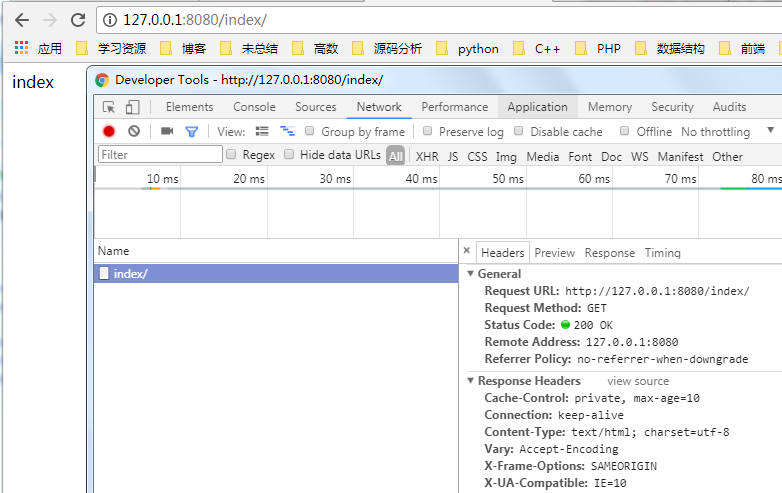
return "main" def index(request):
return "index" routers = [
("/main/",main),
('/index/',index),
] def run():
sock = socket.socket()
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, )
sock.bind(('127.0.0.1', ))
sock.listen()
sock.setblocking(False) inputs = []
inputs.append(sock)
while True:
rlist, wlist, elist = select(inputs, [], [], 0.05) # http是单向的,我们只获取请求即可
for r in rlist:
if r == sock: # 有新的请求到来
conn, addr = sock.accept()
conn.setblocking(False)
inputs.append(conn)
else: # 客户端请求数据
data = b""
# 开始获取请求头
while True:
try:
chunk = r.recv()
data += chunk
except BlockingIOError as e:
chunk = None
if not chunk:
break # 处理请求头,请求体
request = HttpRequest(data)
#.获取url
#.路由匹配
#.执行函数,获取返回值
#.将返回值发送
flag = False
func = None
for route in routers:
if re.match(route[],request.url):
flag = True
func = route[]
break
if flag:
result = func(request)
response = HttpResponse(result)
r.sendall(response.response())
else:
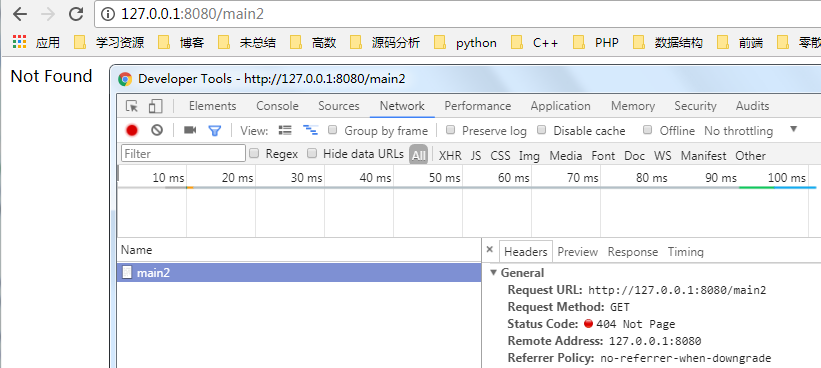
response = HttpResponse("Not Found")
response.changeStatus(,"Not Page")
r.sendall(response.response())
inputs.remove(r)
r.close() if __name__ == "__main__":
run()
未实现异步非阻塞
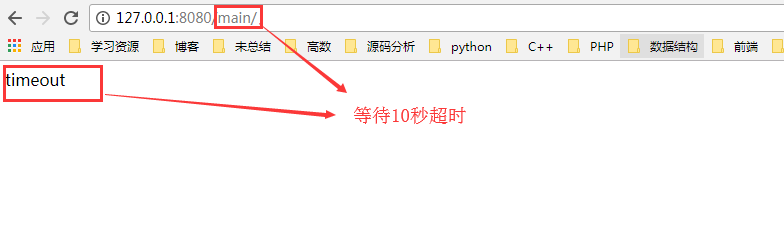
六:完善自定义web框架(异步)
import socket
from select import select
import re,time class HttpResponse(object):
"""
封装响应信息
"""
def __init__(self, content=''):
self.content = content
''' '''
self.status = "HTTP/1.1 200 OK"
self.headers = {}
self.cookies = {} self.initResponseHeader() def changeStatus(self,status_code,status_desc):
self.status = "HTTP/1.1 %s %s"%(status_code,status_desc) def initResponseHeader(self):
self.headers['Content-Type']='text/html; charset=utf-8'
self.headers['X-Frame-Options']='SAMEORIGIN'
self.headers['X-UA-Compatible']='IE=10'
self.headers['Cache-Control']='private, max-age=10'
self.headers['Vary']='Accept-Encoding'
self.headers['Connection']='keep-alive' def response(self):
resp_content = None
header_list = [self.status,]
for item in self.headers.items():
header_list.append("%s: %s"%(item[],item[])) header_str = "\r\n".join(header_list)
resp_content = "\r\n\r\n".join([header_str,self.content])
return bytes(resp_content, encoding='utf-8') class HttpRequest:
def __init__(self,content):
"""content:用户传递的请求头信息,字节型"""
self.content = content
self.header_bytes = bytes()
self.body_bytes = bytes() self.header_str = ""
self.body_str = "" self.header_dict = {} self.method = ""
self.url = ""
self.protocol = "" self.initialize()
self.initialize_headers() def initialize(self):
data = self.content.split(b"\r\n\r\n",)
if len(data) == : #全是请求头
self.header_bytes = self.content
else: #含有请求头和请求体
self.header_bytes,self.body_bytes = data
self.header_str = str(self.header_bytes,encoding="utf-8")
self.body_str = str(self.body_bytes,encoding="utf-8") def initialize_headers(self):
headers = self.header_str.split("\r\n")
first_line = headers[].split(" ")
if len(first_line) == :
self.method,self.url,self.protocol = first_line
for line in headers[:]:
k_v = line.split(":",)
if len(k_v) == :
k,v = k_v
self.header_dict[k] = v class Future:
def __init__(self,timeout):
self.result = None
self.timeout = timeout
self.start = time.time() def add_callback_done(self,callback,request):
self.callback = callback
self.request = request def call(self):
if self.result == "timeout": #超时就不要去获取页面数据,直接返回超时
return "timeout"
if self.result: #若是没有超时,去获取回调数据
return self.callback(self.request) def callback(request):
print(request)
return "async main" f = None def main(request):
global f
f = Future(10)
f.add_callback_done(callback,request) #设置回调
return f def index(request):
return "index" def stop(request):
if f:
f.result = True
return "stop" routers = [
("/main/",main),
('/index/',index),
('/stop/', stop), #用于向future的result赋值
] def run():
sock = socket.socket()
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, )
sock.bind(('127.0.0.1', ))
sock.listen()
sock.setblocking(False) inputs = []
async_request_dict = {}
inputs.append(sock)
while True:
rlist, wlist, elist = select(inputs, [], [], 0.05) # http是单向的,我们只获取请求即可
for r in rlist:
if r == sock: # 有新的请求到来
conn, addr = sock.accept()
conn.setblocking(False)
inputs.append(conn)
else: # 客户端请求数据
data = b""
# 开始获取请求头
while True:
try:
chunk = r.recv()
data += chunk
except BlockingIOError as e:
chunk = None
if not chunk:
break # 处理请求头,请求体
request = HttpRequest(data)
#.获取url
#.路由匹配
#.执行函数,获取返回值
#.将返回值发送
flag = False
func = None
for route in routers:
if re.match(route[],request.url):
flag = True
func = route[]
break
if flag:
result = func(request)
if isinstance(result,Future): #对于future对象,我们另外做异步处理,不阻塞当前操作
async_request_dict[r] = result
continue
response = HttpResponse(result)
r.sendall(response.response())
else:
response = HttpResponse("Not Found")
response.changeStatus(,"Not Page")
r.sendall(response.response())
inputs.remove(r)
r.close() for conn in list(async_request_dict.keys()): #另外对future对象处理
future = async_request_dict[conn]
start = future.start
timeout = future.timeout
if (start+timeout) <= time.time(): #超时检测
future.result = "timeout"
if future.result:
response = HttpResponse(future.call()) #获取回调数据
conn.sendall(response.response())
conn.close()
del async_request_dict[conn] #删除字典中这个链接,和下面inputs列表中链接
inputs.remove(conn) if __name__ == "__main__":
run()


python---tornado补充(异步非阻塞)的更多相关文章
- Tornado的异步非阻塞
阻塞和非阻塞Web框架 只有Tornado和Node.js是异步非阻塞的,其他所有的web框架都是阻塞式的. Tornado阻塞和非阻塞两种模式都支持. 阻塞式: 代表:Django.Flask.To ...
- tornado 之 异步非阻塞
异步非阻塞 1.基本使用 装饰器 + Future 从而实现Tornado的异步非阻塞 import tornado.web import tornado.ioloop from tornado im ...
- Tornado之异步非阻塞
同步模式:同步模式下,只有处理完前一个任务下一个才会执行 class MainHandler(tornado.web.RequestHandler): def get(self): time.slee ...
- Python web框架 Tornado(二)异步非阻塞
异步非阻塞 阻塞式:(适用于所有框架,Django,Flask,Tornado,Bottle) 一个请求到来未处理完成,后续一直等待 解决方案:多线程,多进程 异步非阻塞(存在IO请求): Torna ...
- Python web框架 Tornado异步非阻塞
Python web框架 Tornado异步非阻塞 异步非阻塞 阻塞式:(适用于所有框架,Django,Flask,Tornado,Bottle) 一个请求到来未处理完成,后续一直等待 解决方案: ...
- Tornado异步非阻塞的使用以及原理
Tornado 和现在的主流 Web 服务器框架(包括大多数 Python 的框架)有着明显的区别:它是非阻塞式服务器,而且速度相当快.得利于其 非阻塞的方式和对 epoll 的运用,Tornado ...
- 03: 自定义异步非阻塞tornado框架
目录:Tornado其他篇 01: tornado基础篇 02: tornado进阶篇 03: 自定义异步非阻塞tornado框架 04: 打开tornado源码剖析处理过程 目录: 1.1 源码 1 ...
- Tornado 异步非阻塞
1 装饰器 + Future 从而实现Tornado的异步非阻塞 class AsyncHandler(tornado.web.RequestHandler): @gen.coroutine def ...
- 利用tornado使请求实现异步非阻塞
基本IO模型 网上搜了很多关于同步异步,阻塞非阻塞的说法,理解还是不能很透彻,有必要买书看下. 参考:使用异步 I/O 大大提高应用程序的性能 怎样理解阻塞非阻塞与同步异步的区别? 同步和异步:主要关 ...
- 200行自定义异步非阻塞Web框架
Python的Web框架中Tornado以异步非阻塞而闻名.本篇将使用200行代码完成一个微型异步非阻塞Web框架:Snow. 一.源码 本文基于非阻塞的Socket以及IO多路复用从而实现异步非阻塞 ...
随机推荐
- jQuery之元素查找
在已经匹配出的元素集合中根据选择器查找孩子/父母/兄弟标签1. children(): 子标签中找2. find() : 后代标签中找3. parent() : 父标签4. prevAll() : 前 ...
- Java实现的词频统计——功能改进
本次改进是在原有功能需求及代码基础上额外做的修改,保证了原有的基础需求之外添加了新需求的功能. 功能: 1. 小文件输入——从控制台由用户输入到文件中,再对文件进行统计: 2.支持命令行输入英文作品的 ...
- [翻译]Android官方文档 - 通知(Notifications)
翻译的好辛苦,有些地方也不太理解什么意思,如果有误,还请大神指正. 官方文档地址:http://developer.android.com/guide/topics/ui/notifiers/noti ...
- Java 面试前的基础准备 - 01
使用这个在线网页编辑真的是不习惯,还是 windows live writer 好. 下面列一个清单用于最近的面试:( 清单是网上down的 ) static,final,transient 等关键字 ...
- this.$http & vue
this.$http & vue https://github.com/pagekit/vue-resource Alias axios to Vue.prototype.$http http ...
- Shell Script的默认变量
$? #上一个命令执行后所回传的值,当我们执行某些命令时,这些命令都会回传一个执行后的代码.一般来说,如果成功执行该命令则会回传一个0值.如果执行过程发生错误,就会回传“错误代码” $$ #代表目前这 ...
- Shell逐行读取文件的3种方法
方法1:while循环中执行效率最高,最常用的方法. while read linedoecho $linedone < filename 注释:这种方式在结束的时候需要执行文件,就好像是执行 ...
- 第88天:HTML5中使用classList操作css类
在HTML5 API里,页面DOM里的每个节点上都有一个classList对象,程序员可以使用里面的方法新增.删除.修改节点上的CSS类.使用classList,程序员还可以用它来判断某个节点是否被赋 ...
- Linux进入单用户模式(passwd root修改密码)
进入单用户模式——passwd root修改密码 1.在grub 页面输入a,进入修改内核模式 2.在内核的结尾“/”,输入空格,在输入single,回车 3.启动系统,进入单用户模式 4.Passw ...
- [三]SpringBoot 之 热部署
如下配置 <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring ...