python---tornado补充(异步非阻塞)
一:正常访问(同一线程中多个请求是同步阻塞状态)
import tornado.ioloop
import tornado.web
import tornado.websocket
import datetime,time class MainHandler(tornado.web.RequestHandler):
def get(self):
self.write("main")class IndexHandler(tornado.web.RequestHandler):
def get(self):
time.sleep()
self.write("index") st ={
"template_path": "template",#模板路径配置
"static_path":'static',
} #路由映射 匹配执行,否则404
application = tornado.web.Application([
("/main",MainHandler),
("/index",IndexHandler),
],**st) if __name__=="__main__":
application.listen() #io多路复用
tornado.ioloop.IOLoop.instance().start()
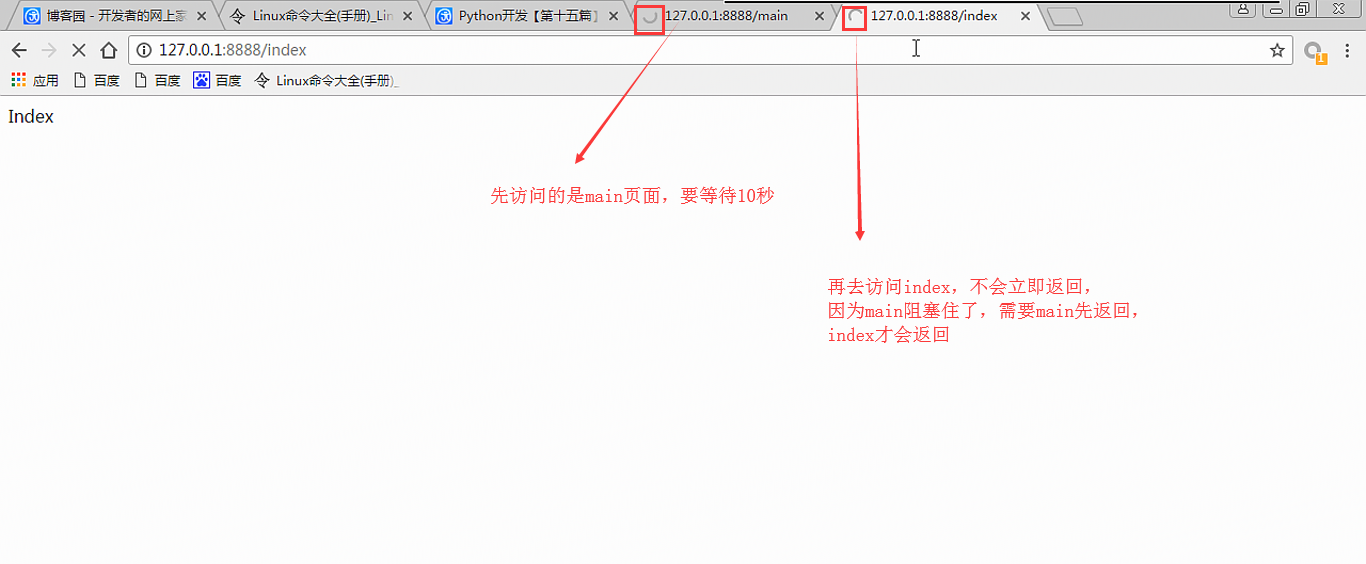
我们先访问index,再去访问main,查看情况
二:使用future模块,实现异步非阻塞
import tornado.ioloop
import tornado.web
import tornado.websocket
import time
from tornado.concurrent import Future class MainHandler(tornado.web.RequestHandler):
def get(self): self.write("main")class IndexHandler(tornado.web.RequestHandler):
def get(self):
future = Future()
tornado.ioloop.IOLoop.current().add_timeout(time.time()+5,self.done) #会在结束后为future中result赋值
yield future def done(self,*args,**kwargs):
self.write("index")
self.finish() #关闭请求连接,必须在回调中完成 st ={
"template_path": "template",#模板路径配置
"static_path":'static',
} #路由映射 匹配执行,否则404
application = tornado.web.Application([
("/main",MainHandler),
("/index",IndexHandler),
],**st) if __name__=="__main__":
application.listen() #io多路复用
tornado.ioloop.IOLoop.instance().start()


三:在tornado中使用异步IO请求模块
import tornado.ioloop
import tornado.web
import tornado.websocket
import time
from tornado.concurrent import Future
from tornado import httpclient
from tornado import gen class MainHandler(tornado.web.RequestHandler):
def get(self): self.write("main") def post(self, *args, **kwargs):
pass class IndexHandler(tornado.web.RequestHandler):
@gen.coroutine
def get(self):
http = httpclient.AsyncHTTPClient()
yield http.fetch("http://www.google.com",self.done) def done(self):
self.write("index")
self.finish() def post(self, *args, **kwargs):
pass st ={
"template_path": "template",#模板路径配置
"static_path":'static',
} #路由映射 匹配执行,否则404
application = tornado.web.Application([
("/main",MainHandler),
("/index",IndexHandler),
],**st) if __name__=="__main__":
application.listen() #io多路复用
tornado.ioloop.IOLoop.instance().start()
四:请求间交互,使用future
import tornado.ioloop
import tornado.web
import tornado.websocket
from tornado.concurrent import Future
from tornado import gen class MainHandler(tornado.web.RequestHandler):
def get(self):
self.write("main") class IndexHandler(tornado.web.RequestHandler):
@gen.coroutine
def get(self):
future = Future()
future.add_done_callback(self.done)
yield future #由于future中的result中值一直未被赋值,所有客户端一直等待
def done(self,*args,**kwargs):
self.write("index")
self.finish() st ={
"template_path": "template",#模板路径配置
"static_path":'static',
} #路由映射 匹配执行,否则404
application = tornado.web.Application([
("/main",MainHandler),
("/index",IndexHandler),
],**st) if __name__=="__main__":
application.listen() #io多路复用
tornado.ioloop.IOLoop.instance().start()
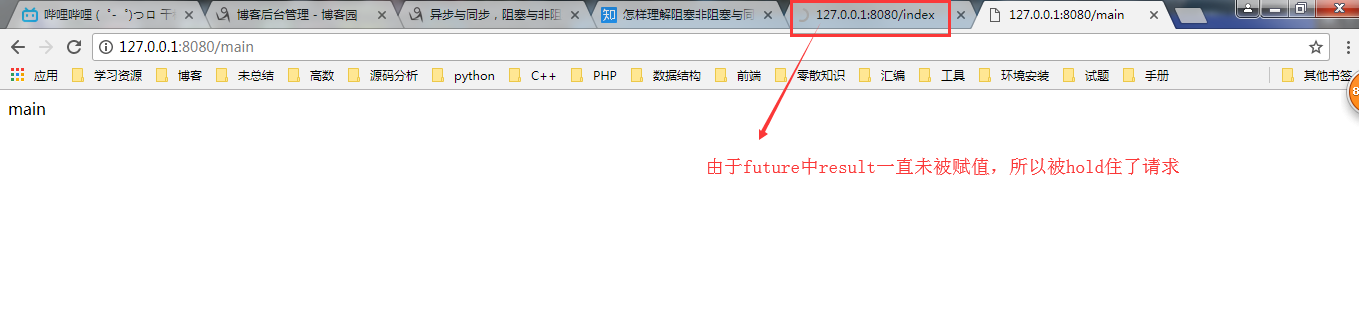
我们可以在另一个请求中去为这个future中result赋值,使当前请求返回

import tornado.ioloop
import tornado.web
import tornado.websocket
from tornado.concurrent import Future
from tornado import gen future = None class MainHandler(tornado.web.RequestHandler):
def get(self):
global future
future.set_result(None) #为Future中result赋值
self.write("main") class IndexHandler(tornado.web.RequestHandler):
@gen.coroutine
def get(self):
global future
future = Future()
future.add_done_callback(self.done)
yield future #由于future中的result中值一直未被赋值,所有客户端一直等待 def done(self,*args,**kwargs):
self.write("index")
self.finish() st ={
"template_path": "template",#模板路径配置
"static_path":'static',
} #路由映射 匹配执行,否则404
application = tornado.web.Application([
("/main",MainHandler),
("/index",IndexHandler),
],**st) if __name__=="__main__":
application.listen() #io多路复用
tornado.ioloop.IOLoop.instance().start()

五:自定义web框架(同步)
# coding:utf8
# __author: Administrator
# date: //
# /usr/bin/env python
import socket
from select import select
import re class HttpResponse(object):
"""
封装响应信息
"""
def __init__(self, content=''):
self.content = content
''' '''
self.status = "HTTP/1.1 200 OK"
self.headers = {}
self.cookies = {} self.initResponseHeader() def changeStatus(self,status_code,status_desc):
self.status = "HTTP/1.1 %s %s"%(status_code,status_desc) def initResponseHeader(self):
self.headers['Content-Type']='text/html; charset=utf-8'
self.headers['X-Frame-Options']='SAMEORIGIN'
self.headers['X-UA-Compatible']='IE=10'
self.headers['Cache-Control']='private, max-age=10'
self.headers['Vary']='Accept-Encoding'
self.headers['Connection']='keep-alive' def response(self):
resp_content = None
header_list = [self.status,]
for item in self.headers.items():
header_list.append("%s: %s"%(item[],item[])) header_str = "\r\n".join(header_list)
resp_content = "\r\n\r\n".join([header_str,self.content])
return bytes(resp_content, encoding='utf-8') class HttpRequest:
def __init__(self,content):
"""content:用户传递的请求头信息,字节型"""
self.content = content
self.header_bytes = bytes()
self.body_bytes = bytes() self.header_str = ""
self.body_str = "" self.header_dict = {} self.method = ""
self.url = ""
self.protocol = "" self.initialize()
self.initialize_headers() def initialize(self):
data = self.content.split(b"\r\n\r\n",)
if len(data) == : #全是请求头
self.header_bytes = self.content
else: #含有请求头和请求体
self.header_bytes,self.body_bytes = data
self.header_str = str(self.header_bytes,encoding="utf-8")
self.body_str = str(self.body_bytes,encoding="utf-8") def initialize_headers(self):
headers = self.header_str.split("\r\n")
first_line = headers[].split(" ")
if len(first_line) == :
self.method,self.url,self.protocol = first_line
for line in headers[:]:
k_v = line.split(":",)
if len(k_v) == :
k,v = k_v
self.header_dict[k] = v def main(request):
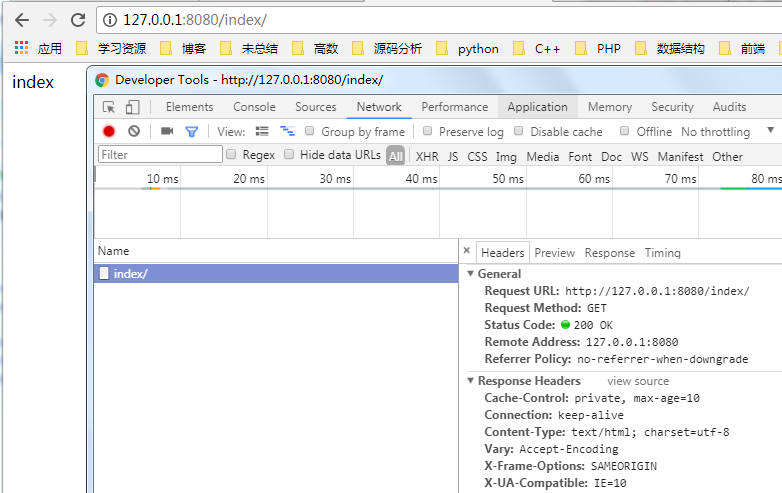
return "main" def index(request):
return "index" routers = [
("/main/",main),
('/index/',index),
] def run():
sock = socket.socket()
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, )
sock.bind(('127.0.0.1', ))
sock.listen()
sock.setblocking(False) inputs = []
inputs.append(sock)
while True:
rlist, wlist, elist = select(inputs, [], [], 0.05) # http是单向的,我们只获取请求即可
for r in rlist:
if r == sock: # 有新的请求到来
conn, addr = sock.accept()
conn.setblocking(False)
inputs.append(conn)
else: # 客户端请求数据
data = b""
# 开始获取请求头
while True:
try:
chunk = r.recv()
data += chunk
except BlockingIOError as e:
chunk = None
if not chunk:
break # 处理请求头,请求体
request = HttpRequest(data)
#.获取url
#.路由匹配
#.执行函数,获取返回值
#.将返回值发送
flag = False
func = None
for route in routers:
if re.match(route[],request.url):
flag = True
func = route[]
break
if flag:
result = func(request)
response = HttpResponse(result)
r.sendall(response.response())
else:
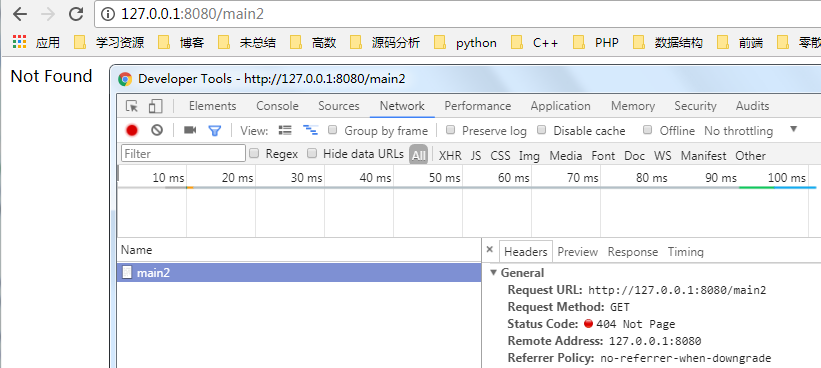
response = HttpResponse("Not Found")
response.changeStatus(,"Not Page")
r.sendall(response.response())
inputs.remove(r)
r.close() if __name__ == "__main__":
run()
未实现异步非阻塞
六:完善自定义web框架(异步)
import socket
from select import select
import re,time class HttpResponse(object):
"""
封装响应信息
"""
def __init__(self, content=''):
self.content = content
''' '''
self.status = "HTTP/1.1 200 OK"
self.headers = {}
self.cookies = {} self.initResponseHeader() def changeStatus(self,status_code,status_desc):
self.status = "HTTP/1.1 %s %s"%(status_code,status_desc) def initResponseHeader(self):
self.headers['Content-Type']='text/html; charset=utf-8'
self.headers['X-Frame-Options']='SAMEORIGIN'
self.headers['X-UA-Compatible']='IE=10'
self.headers['Cache-Control']='private, max-age=10'
self.headers['Vary']='Accept-Encoding'
self.headers['Connection']='keep-alive' def response(self):
resp_content = None
header_list = [self.status,]
for item in self.headers.items():
header_list.append("%s: %s"%(item[],item[])) header_str = "\r\n".join(header_list)
resp_content = "\r\n\r\n".join([header_str,self.content])
return bytes(resp_content, encoding='utf-8') class HttpRequest:
def __init__(self,content):
"""content:用户传递的请求头信息,字节型"""
self.content = content
self.header_bytes = bytes()
self.body_bytes = bytes() self.header_str = ""
self.body_str = "" self.header_dict = {} self.method = ""
self.url = ""
self.protocol = "" self.initialize()
self.initialize_headers() def initialize(self):
data = self.content.split(b"\r\n\r\n",)
if len(data) == : #全是请求头
self.header_bytes = self.content
else: #含有请求头和请求体
self.header_bytes,self.body_bytes = data
self.header_str = str(self.header_bytes,encoding="utf-8")
self.body_str = str(self.body_bytes,encoding="utf-8") def initialize_headers(self):
headers = self.header_str.split("\r\n")
first_line = headers[].split(" ")
if len(first_line) == :
self.method,self.url,self.protocol = first_line
for line in headers[:]:
k_v = line.split(":",)
if len(k_v) == :
k,v = k_v
self.header_dict[k] = v class Future:
def __init__(self,timeout):
self.result = None
self.timeout = timeout
self.start = time.time() def add_callback_done(self,callback,request):
self.callback = callback
self.request = request def call(self):
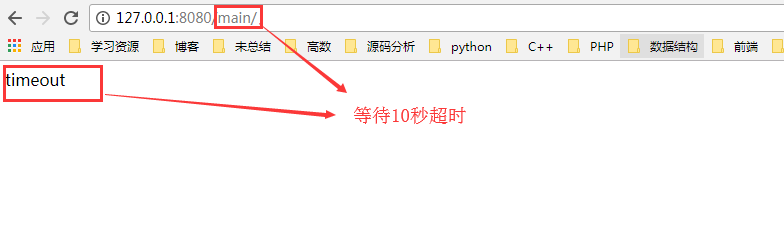
if self.result == "timeout": #超时就不要去获取页面数据,直接返回超时
return "timeout"
if self.result: #若是没有超时,去获取回调数据
return self.callback(self.request) def callback(request):
print(request)
return "async main" f = None def main(request):
global f
f = Future(10)
f.add_callback_done(callback,request) #设置回调
return f def index(request):
return "index" def stop(request):
if f:
f.result = True
return "stop" routers = [
("/main/",main),
('/index/',index),
('/stop/', stop), #用于向future的result赋值
] def run():
sock = socket.socket()
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, )
sock.bind(('127.0.0.1', ))
sock.listen()
sock.setblocking(False) inputs = []
async_request_dict = {}
inputs.append(sock)
while True:
rlist, wlist, elist = select(inputs, [], [], 0.05) # http是单向的,我们只获取请求即可
for r in rlist:
if r == sock: # 有新的请求到来
conn, addr = sock.accept()
conn.setblocking(False)
inputs.append(conn)
else: # 客户端请求数据
data = b""
# 开始获取请求头
while True:
try:
chunk = r.recv()
data += chunk
except BlockingIOError as e:
chunk = None
if not chunk:
break # 处理请求头,请求体
request = HttpRequest(data)
#.获取url
#.路由匹配
#.执行函数,获取返回值
#.将返回值发送
flag = False
func = None
for route in routers:
if re.match(route[],request.url):
flag = True
func = route[]
break
if flag:
result = func(request)
if isinstance(result,Future): #对于future对象,我们另外做异步处理,不阻塞当前操作
async_request_dict[r] = result
continue
response = HttpResponse(result)
r.sendall(response.response())
else:
response = HttpResponse("Not Found")
response.changeStatus(,"Not Page")
r.sendall(response.response())
inputs.remove(r)
r.close() for conn in list(async_request_dict.keys()): #另外对future对象处理
future = async_request_dict[conn]
start = future.start
timeout = future.timeout
if (start+timeout) <= time.time(): #超时检测
future.result = "timeout"
if future.result:
response = HttpResponse(future.call()) #获取回调数据
conn.sendall(response.response())
conn.close()
del async_request_dict[conn] #删除字典中这个链接,和下面inputs列表中链接
inputs.remove(conn) if __name__ == "__main__":
run()


python---tornado补充(异步非阻塞)的更多相关文章
- Tornado的异步非阻塞
阻塞和非阻塞Web框架 只有Tornado和Node.js是异步非阻塞的,其他所有的web框架都是阻塞式的. Tornado阻塞和非阻塞两种模式都支持. 阻塞式: 代表:Django.Flask.To ...
- tornado 之 异步非阻塞
异步非阻塞 1.基本使用 装饰器 + Future 从而实现Tornado的异步非阻塞 import tornado.web import tornado.ioloop from tornado im ...
- Tornado之异步非阻塞
同步模式:同步模式下,只有处理完前一个任务下一个才会执行 class MainHandler(tornado.web.RequestHandler): def get(self): time.slee ...
- Python web框架 Tornado(二)异步非阻塞
异步非阻塞 阻塞式:(适用于所有框架,Django,Flask,Tornado,Bottle) 一个请求到来未处理完成,后续一直等待 解决方案:多线程,多进程 异步非阻塞(存在IO请求): Torna ...
- Python web框架 Tornado异步非阻塞
Python web框架 Tornado异步非阻塞 异步非阻塞 阻塞式:(适用于所有框架,Django,Flask,Tornado,Bottle) 一个请求到来未处理完成,后续一直等待 解决方案: ...
- Tornado异步非阻塞的使用以及原理
Tornado 和现在的主流 Web 服务器框架(包括大多数 Python 的框架)有着明显的区别:它是非阻塞式服务器,而且速度相当快.得利于其 非阻塞的方式和对 epoll 的运用,Tornado ...
- 03: 自定义异步非阻塞tornado框架
目录:Tornado其他篇 01: tornado基础篇 02: tornado进阶篇 03: 自定义异步非阻塞tornado框架 04: 打开tornado源码剖析处理过程 目录: 1.1 源码 1 ...
- Tornado 异步非阻塞
1 装饰器 + Future 从而实现Tornado的异步非阻塞 class AsyncHandler(tornado.web.RequestHandler): @gen.coroutine def ...
- 利用tornado使请求实现异步非阻塞
基本IO模型 网上搜了很多关于同步异步,阻塞非阻塞的说法,理解还是不能很透彻,有必要买书看下. 参考:使用异步 I/O 大大提高应用程序的性能 怎样理解阻塞非阻塞与同步异步的区别? 同步和异步:主要关 ...
- 200行自定义异步非阻塞Web框架
Python的Web框架中Tornado以异步非阻塞而闻名.本篇将使用200行代码完成一个微型异步非阻塞Web框架:Snow. 一.源码 本文基于非阻塞的Socket以及IO多路复用从而实现异步非阻塞 ...
随机推荐
- mysql 多查询临时表的运用
SELECT * from (select count(*) imgCount1 from imagetable where SeriesID = '1201061992020630292018092 ...
- 【转】nodeJs学习之项目结构
新建的项目结构应该是这样 bin:项目的启动文件,也可以放其他脚本. node_modules:用来存放项目的依赖库. public:用来存放静态文件(css,js,img). routes:路由控制 ...
- ext4.1入门
ExtJS简介 Ext是一个Ajax框架,用于在客户端创建丰富多彩的web应用程序界面,是在Yahoo!UI的基础上发展而来的.官方网址:www.sencha.com ExtJS是一个用来开发前端应用 ...
- 第5题 查找字符串中的最长回文字符串---Manacher算法
转载:https://www.felix021.com/blog/read.php?2040 首先用一个非常巧妙的方式,将所有可能的奇数/偶数长度的回文子串都转换成了奇数长度:在每个字符的两边都插入一 ...
- 第八章 Mysql运算符
算术运算符 符号 表达式形式 作用 + x1+x2 加法 - x1-x2 减法 * x1*x2 乘法 / x1/x2 除法 div x1 div x2 同上 % x1%x2 取余 mod mod(x1 ...
- 软工网络15团队作业4——Alpha阶段敏捷冲刺-8
一.当天站立式会议照片: 二.项目进展 昨天已完成的工作: 服务器的完善,后端配置的修改. 明天计划完成的工作: 完善各个功能以及修改bug. 工作中遇到的困难: 服务器的语言编程困难,后端调试中不断 ...
- 【前端学习笔记04】JavaScript数据通信Ajax方法封装
//Ajax 方法封装 //设置数据格式 function setData(data){ if(!data){ return ''; } else{ var arr = []; for(k in da ...
- 第179天:javascript中replace使用总结
ECMAScript提供了replace()方法.这个方法接收两个参数,第一个参数可以是一个RegExp对象或者一个字符串,第二个参数可以是一个字符串或者一个函数.现在我们来详细讲解可能出现的几种情况 ...
- 25个Java机器学习工具&库--转载
本列表总结了25个Java机器学习工具&库: 1. Weka集成了数据挖掘工作的机器学习算法.这些算法可以直接应用于一个数据集上或者你可以自己编写代码来调用.Weka包括一系列的工具,如数据预 ...
- Impala:新一代开源大数据分析引擎--转载
原文地址:http://www.parallellabs.com/2013/08/25/impala-big-data-analytics/ 文 / 耿益锋 陈冠诚 大数据处理是云计算中非常重要的问题 ...