RDD缓存学习
首先实现rdd缓存
准备了500M的数据 10份,每份 100万条,存在hdfs 中通过sc.textFile方法读取
val rdd1 = sc.textFile("hdfs://mini1:9000/spark/input/visitlog").cache
在启动spark集群模式时分配内存2g,第一次分配1g 只缓存了40% 当数据需要的内存大于实际的内存时spark会尽力的缓存
然后调用cache方法
rdd1.count
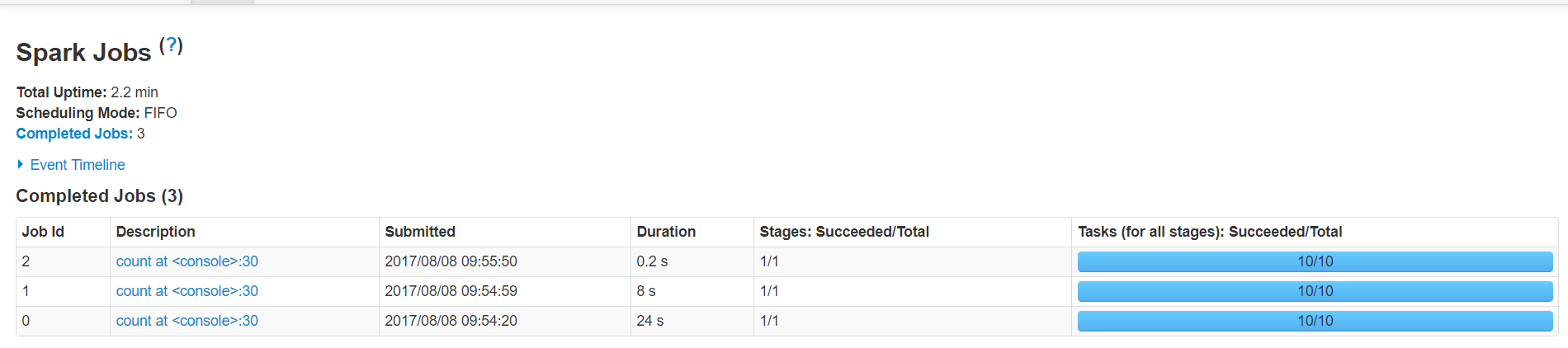
第二次调用rdd的count方法就显示出差距了
默认缓存策略是memory_only
/** Persist this RDD with the default storage level (`MEMORY_ONLY`). */
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
其他的缓存策略
object StorageLevel {
//不缓存
val NONE = new StorageLevel(false, false, false, false)
//只往磁盘中缓存
val DISK_ONLY = new StorageLevel(true, false, false, false)
//磁盘中缓存两份
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, )
//放在内存中
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
//内存中保存两份,多个机器报存
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, )
//报存一份到内存,并且把数据序列化,序列化之后数据占用内存变小,
//但是序列化时需要消耗时间,时间换空间
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
//
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, )
//内存和磁盘都保存
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, )
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
//内存和磁盘都保存 序列化两份
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, )
val OFF_HEAP = new StorageLevel(false, false, true, false)
RDD缓存学习的更多相关文章
- spring boot guava cache 缓存学习
http://blog.csdn.net/hy245120020/article/details/78065676 ****************************************** ...
- TimesTen 应用层数据库缓存学习:4. 仅仅读缓存
在运行本文样例前.首先先运行TimesTen 应用层数据库缓存学习:2. 环境准备中的操作. Read-only Cache Group的概念 仅仅读缓存组例如以下图: 仅仅读缓存组(Read-Onl ...
- RDD缓存
RDD的缓存 Spark速度非常快的原因之一,就是在不同操作中可以在内存中持久化或缓存数据集.当持久化某个RDD后,每一个节点都将把计算的分片结果保存在内存中,并在对此RDD或衍生出的RDD进行的其他 ...
- Spark RDD设计学习笔记
本文档是学习RDD经典论文<Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster ...
- Android缓存学习入门
本文主要包括以下内容 利用LruCache实现内存缓存 利用DiskLruCache实现磁盘缓存 LruCache与DiskLruCache结合实例 利用了缓存机制的瀑布流实例 内存缓存的实现 pub ...
- memcache/redis 缓存学习笔记
0.redis和memcache的区别 a.redis可以存储除了string之外的对象,如list,hash等 b.服务器宕机以后,redis会把内存的数据持久化到磁盘上,而memcache则不会 ...
- RDD缓存策略
Spark支持将数据集放置在集群的缓存中,以便于数据重用. Spark缓存策略对应的类: class StorageLevel private( private var useDisk_ : Bool ...
- C# 缓存学习第一天
缓存应用目的:缓存主要是为了提高数据的读取速度.因为服务器和应用客户端之间存在着流量的瓶颈,所以读取大容量数据时,使用缓存来直接为客户端服务,可以减少客户端与服务器端的数据交互,从而大大提高程序的性能 ...
- CPU缓存学习及C6678缓存使用总结(知识归纳)
作者注: 1.本篇博客内容是本人在学习cpu缓存原理时进行的学习总结,参考了多处相关资源(书籍,视频,知乎回答等),参考出处标注在内容最后. 2.由于本篇内容的编辑工作在印象笔记完成,输出的PDF文件 ...
随机推荐
- 转:Android应用开发性能优化完全分析
转自:http://blog.csdn.net/yanbober/article/details/48394201 1 背景 其实有点不想写这篇文章的,但是又想写,有些矛盾.不想写的原因是随便上网一搜 ...
- Eureka 的 Application Service client的注冊以及执行演示样例
Eureka 服务器架起来了(关于架设步骤參考博客<Linux 下 Eureka 服务器的部署>),如今怎样把我们要负载均衡的服务器(也就是从 Application Cl ...
- org.hibernate.MappingException: An association from the table order_intem_inf refers to a unmapped
执行一个HIbernate的演示样例时出现例如以下错误信息 Exception in thread "main" java.lang.ExceptionInInitializerE ...
- Cocos2d-x 2.x 升级为 3.x 常见变化纪录
1.去CC 之前2.0的CC**,把CC都去掉,主要的元素都是保留的 2.0 CCSprite CCCallFunc CCNode .. 3.0 Sprite CallFunc Node .. 2. ...
- 一次踩坑记录(使用rpc前后端分离服务总是注册不上)
问题简述: 项目架构使用了前后端分离,使用rpc进行服务调用与注册,这里没有用dubbo之类的,仅仅用zookeeper,每次在启动项目时总是报错rpcException异常跟NPE异常,后台查看zo ...
- KineticJS教程(4)
KineticJS教程(4) 作者: ysm 4.图形样式 4.1.填充 Kinetic中图形的填充属性可以在构造方法中的config参数中的fill属性进行设定,也可以用图形对象的setFill方 ...
- poj 2388 insert sorting
/** \brief poj 2388 insert sorting 2015 6 12 * * \param * \param * \return * */ #include <iostrea ...
- Java Executor 线程池
- linux下php添加cur/soapl扩展
注意:在不同的扩展路径下 ./configure --help 的帮助信息不尽相同 1.跟php一起安装 下载 http://curl.haxx.se/download/ curl 取较低的版本 wg ...
- resharper警告 :linq replace with single call to FirstOrDefault
使用resharper时对linq使用的FirstOrDefault 一直产生一个警告,