RDD缓存学习
首先实现rdd缓存
准备了500M的数据 10份,每份 100万条,存在hdfs 中通过sc.textFile方法读取
val rdd1 = sc.textFile("hdfs://mini1:9000/spark/input/visitlog").cache
在启动spark集群模式时分配内存2g,第一次分配1g 只缓存了40% 当数据需要的内存大于实际的内存时spark会尽力的缓存
然后调用cache方法
rdd1.count
第二次调用rdd的count方法就显示出差距了
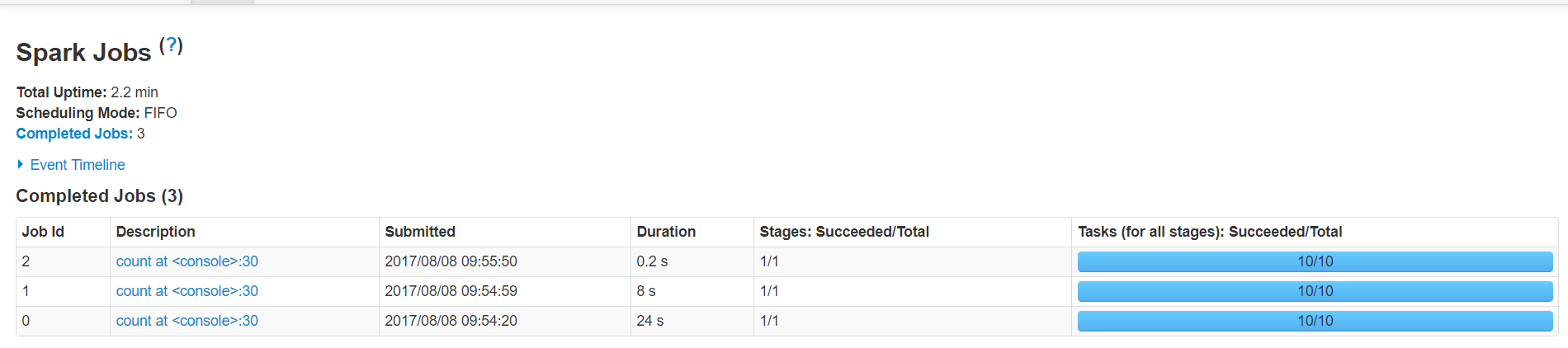
默认缓存策略是memory_only
/** Persist this RDD with the default storage level (`MEMORY_ONLY`). */
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
其他的缓存策略
object StorageLevel {
//不缓存
val NONE = new StorageLevel(false, false, false, false)
//只往磁盘中缓存
val DISK_ONLY = new StorageLevel(true, false, false, false)
//磁盘中缓存两份
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, )
//放在内存中
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
//内存中保存两份,多个机器报存
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, )
//报存一份到内存,并且把数据序列化,序列化之后数据占用内存变小,
//但是序列化时需要消耗时间,时间换空间
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
//
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, )
//内存和磁盘都保存
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, )
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
//内存和磁盘都保存 序列化两份
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, )
val OFF_HEAP = new StorageLevel(false, false, true, false)
RDD缓存学习的更多相关文章
- spring boot guava cache 缓存学习
http://blog.csdn.net/hy245120020/article/details/78065676 ****************************************** ...
- TimesTen 应用层数据库缓存学习:4. 仅仅读缓存
在运行本文样例前.首先先运行TimesTen 应用层数据库缓存学习:2. 环境准备中的操作. Read-only Cache Group的概念 仅仅读缓存组例如以下图: 仅仅读缓存组(Read-Onl ...
- RDD缓存
RDD的缓存 Spark速度非常快的原因之一,就是在不同操作中可以在内存中持久化或缓存数据集.当持久化某个RDD后,每一个节点都将把计算的分片结果保存在内存中,并在对此RDD或衍生出的RDD进行的其他 ...
- Spark RDD设计学习笔记
本文档是学习RDD经典论文<Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster ...
- Android缓存学习入门
本文主要包括以下内容 利用LruCache实现内存缓存 利用DiskLruCache实现磁盘缓存 LruCache与DiskLruCache结合实例 利用了缓存机制的瀑布流实例 内存缓存的实现 pub ...
- memcache/redis 缓存学习笔记
0.redis和memcache的区别 a.redis可以存储除了string之外的对象,如list,hash等 b.服务器宕机以后,redis会把内存的数据持久化到磁盘上,而memcache则不会 ...
- RDD缓存策略
Spark支持将数据集放置在集群的缓存中,以便于数据重用. Spark缓存策略对应的类: class StorageLevel private( private var useDisk_ : Bool ...
- C# 缓存学习第一天
缓存应用目的:缓存主要是为了提高数据的读取速度.因为服务器和应用客户端之间存在着流量的瓶颈,所以读取大容量数据时,使用缓存来直接为客户端服务,可以减少客户端与服务器端的数据交互,从而大大提高程序的性能 ...
- CPU缓存学习及C6678缓存使用总结(知识归纳)
作者注: 1.本篇博客内容是本人在学习cpu缓存原理时进行的学习总结,参考了多处相关资源(书籍,视频,知乎回答等),参考出处标注在内容最后. 2.由于本篇内容的编辑工作在印象笔记完成,输出的PDF文件 ...
随机推荐
- java设计模式2--抽象工厂模式(Abstract Factory)
本文地址:http://www.cnblogs.com/archimedes/p/java-abstract-factory-pattern.html,转载请注明源地址. 抽象工厂模式(别名:配套) ...
- 设计模式实例(Lua)笔记之四(Builder 模式)
1.描写叙述: 又是一个周三,快要下班了,老大突然又拉住我,喜滋滋的告诉我"牛叉公司非常惬意我们做的模型,又签订了一个合同,把奔驰.宝马的车辆模型都交给我我们公司制作了,只是这次又 ...
- Thinkphp学习笔记1-URL模式
PATHINFO模式 PATHINFO模式是系统的默认URL模式,提供了最好的SEO支持,系统内部已经做了环境的兼容处理,所以能够支持大多数的主机环境.对应上面的URL模式,PATHINFO模式下面的 ...
- ASPX导入JS,JavaScript乱码怎么办
不管你把JS改成UTF-8还是ASCII格式,弹出都是乱码. 你只要在ASPX文件顶部加上"ResponseEncoding="gb2312" ContentType=& ...
- 《iOS用户体验》总结与思考-改动版
假设转载此文.请注明出处:http://blog.csdn.net/paulery2012/article/details/25157347,谢谢. 前言: 本文是在阅读<ios用户体验> ...
- 判断IE浏览器版本的精简脚本
IE浏览器不管是什么版本,总是跟Web标准有些不太兼容.对于代码工作者来说,自然是苦不堪言,为了考虑IE的兼容问题,不管是写 CSS 还是 JS,往往都要对 IE 特别对待,这就少不了做些判断.本文不 ...
- UML回想-通信图
我们对软件project这一大块的学习事实上開始的还是挺早的,而且在后来的学习过程中也不断的涉及到了这些知识. 可是,经过软考的检验来看我对软工这一块的内容掌握的实在是慘不忍睹.基本上就是一出 ...
- android基础-Apk打包过程(了解)
此文来源于<Android软件安全与逆向分析> 一.打包资料文件,生成R.java文件. 二.处理aidl文件,生成相应的Java文件. 三.编译工程源代码,生成相应的class文件. 四 ...
- Java之字节码(1) - 深入解析
转载地址 一:Java字节代码的组织形式 类文件{ OxCAFEBABE,小版本号,大版本号,常量池大小,常量池数组,访问控制标记,当前类信息,父类信息,实现的接口个数,实现的接口信息数组,域个数,域 ...
- 我的项目7 js 实现歌词同步(额,小小的效果)
在项目中须要做一个播放器,还要实现歌词同步的效果,就跟如今搜狗音乐的歌词同步差点儿相同,在网上查了一些关于这方面的.整理了一下,在这里,其有用这种方法能够吗? <!DOCTYPE html> ...