【AR实验室】mulberryAR:并行提取ORB特征
本文转载请注明出处 —— polobymulberry-博客园
0x00 - 前言
在【AR实验室】mulberryAR : ORBSLAM2+VVSION末尾提及了iPhone5s真机测试结果,其中ExtractORB函数,也就是提取图像的ORB特征这一块耗时很可观。所以这也是目前需要优化的重中之重。此处,我使用【AR实验室】mulberryAR :添加连续图像作为输入中添加的连续图像作为输入。这样的好处有两个,一个就是保证输入一致,那么单线程提取特征和并行提取特征两种方法优化对比就比较有可信度,另一个是可以使用iOS模拟器来跑程序了,因为不需要打开摄像头的,测试起来相当方便,更有多种机型任你选。
目前对特征提取这部分优化就只有两个想法:
- 将特征提取的过程并行化。
- 减少提取的特征点数量。
第二种方法很容易,只需要在配置文件中更改提取特征点的数目即可,此处不赘述。本文主要集中第一种方法,初步尝试将特征提取并行化。
0x01 - ORB-SLAM2特征提取过程耗时分析
ORB-SLAM2中特征提取函数叫做ExtractORB,是Frame类的一个成员函数。用来提取当前Frame的ORB特征点。
// flag是给双目相机用的,单目相机默认flag为0
// 提取im上的ORB特征点
void Frame::ExtractORB(int flag, const cv::Mat &im)
{
if(flag==)
// mpORBextractorLeft是ORBextractor对象,因为ORBextractor重载了()
// 所以才会有下面这种用法
(*mpORBextractorLeft)(im,cv::Mat(),mvKeys,mDescriptors);
else
(*mpORBextractorRight)(im,cv::Mat(),mvKeysRight,mDescriptorsRight);
}
从上面代码可以看出ORB-SLAM2特征提取主要调用的是ORBextractor重载的()函数。我们给该函数重要的几个部分打点,测试每个部分的耗时。
重要提示-测试代码执行时间:
测试某段代码执行的时间有很多种方法,比如:
clock_t begin = clock();
//...
clock_t end = clock();
cout << "execute time = " << (end - begin) / CLOCKS_PER_SEC << "s" << endl;
不过我之前在多线程求和【原】C++11并行计算 — 数组求和中使用上述方法计时,发现这个方法对于多线程计算存在bug。因为目前我是基于iOS平台,所以此处我使用了iOS中计算时间的方式。另外又因为在C++文件中不能直接使用Foundation组件,所以采用对应的CoreFoundation。
CFAbsoluteTime beginTime = CFAbsoluteTimeGetCurrent();
CFDateRef beginDate = CFDateCreate(kCFAllocatorDefault, beginTime);
// ...
CFAbsoluteTime endime = CFAbsoluteTimeGetCurrent();
CFDateRef endDate = CFDateCreate(kCFAllocatorDefault, endTime);
CFTimeInterval timeInterval = CFDateGetTimeIntervalSinceDate(endDate, beginDate);
cout << "execure time = " << (double)(timeInterval) * 1000.0 << "ms" << endl;
将上述计时代码插入到operator()函数中,目前函数整体看起来如下,主要是对三个部分进行计时,分别为ComputePyramid、ComputeKeyPointsOctTree和ComputeDescriptors:
void ORBextractor::operator()( InputArray _image, InputArray _mask, vector<KeyPoint>& _keypoints,
OutputArray _descriptors)
{
if(_image.empty())
return; Mat image = _image.getMat();
assert(image.type() == CV_8UC1 ); // 1.计算图像金字塔的时间
CFAbsoluteTime beginComputePyramidTime = CFAbsoluteTimeGetCurrent();
CFDateRef computePyramidBeginDate = CFDateCreate(kCFAllocatorDefault, beginComputePyramidTime);
// Pre-compute the scale pyramid
ComputePyramid(image);
CFAbsoluteTime endComputePyramidTime = CFAbsoluteTimeGetCurrent();
CFDateRef computePyramidEndDate = CFDateCreate(kCFAllocatorDefault, endComputePyramidTime);
CFTimeInterval computePyramidTimeInterval = CFDateGetTimeIntervalSinceDate(computePyramidEndDate, computePyramidBeginDate);
cout << "ComputePyramid time = " << (double)(computePyramidTimeInterval) * 1000.0 << endl; vector < vector<KeyPoint> > allKeypoints; // 2.计算关键点KeyPoint的时间
CFAbsoluteTime beginComputeKeyPointsTime = CFAbsoluteTimeGetCurrent();
CFDateRef computeKeyPointsBeginDate = CFDateCreate(kCFAllocatorDefault, beginComputeKeyPointsTime); ComputeKeyPointsOctTree(allKeypoints);
//ComputeKeyPointsOld(allKeypoints);
CFAbsoluteTime endComputeKeyPointsTime = CFAbsoluteTimeGetCurrent();
CFDateRef computeKeyPointsEndDate = CFDateCreate(kCFAllocatorDefault, endComputeKeyPointsTime);
CFTimeInterval computeKeyPointsTimeInterval = CFDateGetTimeIntervalSinceDate(computeKeyPointsEndDate, computeKeyPointsBeginDate);
cout << "ComputeKeyPointsOctTree time = " << (double)(computeKeyPointsTimeInterval) * 1000.0 << endl; Mat descriptors; int nkeypoints = ;
for (int level = ; level < nlevels; ++level)
nkeypoints += (int)allKeypoints[level].size();
if( nkeypoints == )
_descriptors.release();
else
{
_descriptors.create(nkeypoints, , CV_8U);
descriptors = _descriptors.getMat();
} _keypoints.clear();
_keypoints.reserve(nkeypoints); int offset = ; // 3.计算描述子的时间
CFAbsoluteTime beginComputeDescriptorsTime = CFAbsoluteTimeGetCurrent();
CFDateRef computeDescriptorsBeginDate = CFDateCreate(kCFAllocatorDefault, beginComputeDescriptorsTime);
for (int level = ; level < nlevels; ++level)
{
vector<KeyPoint>& keypoints = allKeypoints[level];
int nkeypointsLevel = (int)keypoints.size(); if(nkeypointsLevel==)
continue; // preprocess the resized image
Mat workingMat = mvImagePyramid[level].clone();
GaussianBlur(workingMat, workingMat, cv::Size(, ), , , BORDER_REFLECT_101); // Compute the descriptors
Mat desc = descriptors.rowRange(offset, offset + nkeypointsLevel);
computeDescriptors(workingMat, keypoints, desc, pattern); offset += nkeypointsLevel; // Scale keypoint coordinates
if (level != )
{
float scale = mvScaleFactor[level]; //getScale(level, firstLevel, scaleFactor);
for (vector<KeyPoint>::iterator keypoint = keypoints.begin(),
keypointEnd = keypoints.end(); keypoint != keypointEnd; ++keypoint)
keypoint->pt *= scale;
}
// And add the keypoints to the output
_keypoints.insert(_keypoints.end(), keypoints.begin(), keypoints.end());
}
CFAbsoluteTime endComputeDescriptorsTime = CFAbsoluteTimeGetCurrent();
CFDateRef computeDescriptorsEndDate = CFDateCreate(kCFAllocatorDefault, endComputeDescriptorsTime);
CFTimeInterval computeDescriptorsTimeInterval = CFDateGetTimeIntervalSinceDate(computeDescriptorsEndDate, computeDescriptorsBeginDate);
cout << "ComputeDescriptors time = " << (double)(computeDescriptorsTimeInterval) * 1000.0 << endl;
}
此时,使用iPhone7模拟器运行mulberryAR,并且运行我之前录制的一段连续图像帧,得到结果如下(此处我只截取前三帧的结果):


可以看出优化的重点在于ComputeKeyPointsOctTree、ComputeDescriptiors。
0x02 - ORB-SLAM2特征提取优化思路
ComputePyramid、ComputeKeyPointsOctTree和ComputeDescriptors函数中都会根据图像金字塔的不同层级做同样的操作,所以此处可以将图像金字塔不同层级的操作并行化。按照这个思路,对三个部分的代码进行了修改。
1.ComputePyramid函数并行化
该函数暂时无法进行并行化处理,因为里面在计算图像金字塔中第n层图像的时候,依赖第n-1层的图像,另外此函数在整个特征提取的部分占比不是很大,相对来说并行化意义不是很大。
2.ComputeKeyPointsOctTree函数并行化
该函数的并行化过程很容易,只需要将其中的for(int i = 0; i < nlevels; ++i)里面的函数做成单独函数,并添加到各自的thread中即可。不废话,直接上代码:
void ORBextractor::ComputeKeyPointsOctTree(vector<vector<KeyPoint> >& allKeypoints)
{
allKeypoints.resize(nlevels); vector<thread> computeKeyPointsThreads; for (int i = ; i < nlevels; ++i) {
computeKeyPointsThreads.push_back(thread(&ORBextractor::ComputeKeyPointsOctTreeEveryLevel, this, i, std::ref(allKeypoints)));
} for (int i = ; i < nlevels; ++i) {
computeKeyPointsThreads[i].join();
} // compute orientations
vector<thread> computeOriThreads;
for (int level = ; level < nlevels; ++level) {
computeOriThreads.push_back(thread(computeOrientation, mvImagePyramid[level], std::ref(allKeypoints[level]), umax));
} for (int level = ; level < nlevels; ++level) {
computeOriThreads[level].join();
}
}
其中ComputeKeyPointsOctTreeEveryLevel函数如下:
void ORBextractor::ComputeKeyPointsOctTreeEveryLevel(int level, vector<vector<KeyPoint> >& allKeypoints)
{
const float W = ; const int minBorderX = EDGE_THRESHOLD-;
const int minBorderY = minBorderX;
const int maxBorderX = mvImagePyramid[level].cols-EDGE_THRESHOLD+;
const int maxBorderY = mvImagePyramid[level].rows-EDGE_THRESHOLD+; vector<cv::KeyPoint> vToDistributeKeys;
vToDistributeKeys.reserve(nfeatures*); const float width = (maxBorderX-minBorderX);
const float height = (maxBorderY-minBorderY); const int nCols = width/W;
const int nRows = height/W;
const int wCell = ceil(width/nCols);
const int hCell = ceil(height/nRows); for(int i=; i<nRows; i++)
{
const float iniY =minBorderY+i*hCell;
float maxY = iniY+hCell+; if(iniY>=maxBorderY-)
continue;
if(maxY>maxBorderY)
maxY = maxBorderY; for(int j=; j<nCols; j++)
{
const float iniX =minBorderX+j*wCell;
float maxX = iniX+wCell+;
if(iniX>=maxBorderX-)
continue;
if(maxX>maxBorderX)
maxX = maxBorderX; vector<cv::KeyPoint> vKeysCell;
FAST(mvImagePyramid[level].rowRange(iniY,maxY).colRange(iniX,maxX),
vKeysCell,iniThFAST,true); if(vKeysCell.empty())
{
FAST(mvImagePyramid[level].rowRange(iniY,maxY).colRange(iniX,maxX),
vKeysCell,minThFAST,true);
} if(!vKeysCell.empty())
{
for(vector<cv::KeyPoint>::iterator vit=vKeysCell.begin(); vit!=vKeysCell.end();vit++)
{
(*vit).pt.x+=j*wCell;
(*vit).pt.y+=i*hCell;
vToDistributeKeys.push_back(*vit);
}
} }
} vector<KeyPoint> & keypoints = allKeypoints[level];
keypoints.reserve(nfeatures); keypoints = DistributeOctTree(vToDistributeKeys, minBorderX, maxBorderX,
minBorderY, maxBorderY,mnFeaturesPerLevel[level], level); const int scaledPatchSize = PATCH_SIZE*mvScaleFactor[level]; // Add border to coordinates and scale information
const int nkps = keypoints.size();
for(int i=; i<nkps ; i++)
{
keypoints[i].pt.x+=minBorderX;
keypoints[i].pt.y+=minBorderY;
keypoints[i].octave=level;
keypoints[i].size = scaledPatchSize;
}
}
在iPhone7模拟器上测试,得到如下结果(取前5帧图像测试):
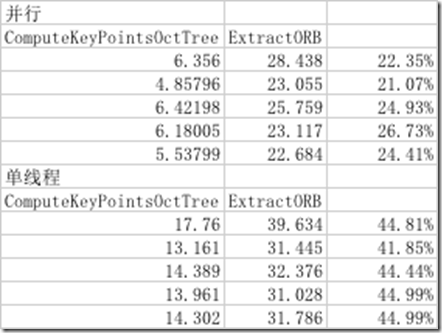
可以看到通过并行处理,ComputeKeyPointsOctTree获得了2~3倍的提速。
3.ComputeDescriptors部分并行化
之所以这一部分叫做“部分”,而非“函数”是因为这部分涉及的函数相对于ComputeKeyPointsOctTree比较复杂,涉及的变量比较多。只有理清之间的关系才能安全地并行化。
此处也不赘述,直接贴出修改后的并行化代码:
vector<thread> computeDescThreads;
vector<vector<KeyPoint> > keypointsEveryLevel;
keypointsEveryLevel.resize(nlevels);
// 图像金字塔每层的offset与前面每层的offset有关,所以不能直接放在ComputeDescriptorsEveryLevel计算
for (int level = ; level < nlevels; ++level) {
computeDescThreads.push_back(thread(&ORBextractor::ComputeDescriptorsEveryLevel, this, level, std::ref(allKeypoints), descriptors, offset, std::ref(keypointsEveryLevel[level])));
int keypointsNum = (int)allKeypoints[level].size();
offset += keypointsNum;
} for (int level = ; level < nlevels; ++level) {
computeDescThreads[level].join();
}
// _keypoints要按照顺序进行插入,所以不能直接放在ComputeDescriptorsEveryLevel计算
for (int level = ; level < nlevels; ++level) {
_keypoints.insert(_keypoints.end(), keypointsEveryLevel[level].begin(), keypointsEveryLevel[level].end());
} // 其中ComputeDescriptorsEveryLevel函数如下
void ORBextractor::ComputeDescriptorsEveryLevel(int level, std::vector<std::vector<KeyPoint> > &allKeypoints, const Mat& descriptors, int offset, vector<KeyPoint>& _keypoints)
{
vector<KeyPoint>& keypoints = allKeypoints[level];
int nkeypointsLevel = (int)keypoints.size(); if(nkeypointsLevel==)
return; // preprocess the resized image
Mat workingMat = mvImagePyramid[level].clone();
GaussianBlur(workingMat, workingMat, cv::Size(, ), , , BORDER_REFLECT_101); // Compute the descriptors
Mat desc = descriptors.rowRange(offset, offset + nkeypointsLevel);
computeDescriptors(workingMat, keypoints, desc, pattern); // offset += nkeypointsLevel; // Scale keypoint coordinates
if (level != )
{
float scale = mvScaleFactor[level]; //getScale(level, firstLevel, scaleFactor);
for (vector<KeyPoint>::iterator keypoint = keypoints.begin(),
keypointEnd = keypoints.end(); keypoint != keypointEnd; ++keypoint)
keypoint->pt *= scale;
}
// And add the keypoints to the output
// _keypoints.insert(_keypoints.end(), keypoints.begin(), keypoints.end());
_keypoints = keypoints;
}
在iPhone7模拟器上测试,得到如下结果(取前5帧图像测试):
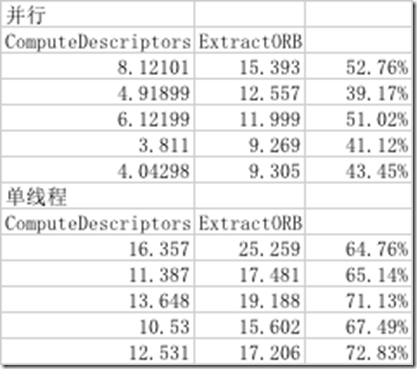
可以看到通过并行处理,ComputeDescriptors获得了2~3倍的提速。
0x03 - 并行化结果分析
0x02小节已经对比了每步优化的结果。此处从整体的角度对结果进行简单的分析。使用iPhone7模拟器跑了前5帧的对比结果:
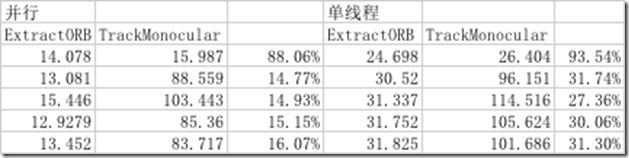
从结果中可以看出,ORB特征提取速度有了2~3倍的提升,在TrackMonocular部分占比也下降了不少,暂时ORB特征提取不用作为性能优化的重点。后面将会从其他方面对ORB-SLAM2进行优化。
【AR实验室】mulberryAR:并行提取ORB特征的更多相关文章
- 【AR实验室】mulberryAR : ORBSLAM2+VVSION
本文转载请注明出处 —— polobymulberry-博客园 0x00 - 前言 mulberryAR是我业余时间弄的一个AR引擎,目前主要支持单目视觉SLAM+3D渲染,并且支持iOS端,但是该引 ...
- 【AR实验室】ARToolKit之制作自己的Marker/NFT
0x00 - 前言 看过example后,就会想自己动动手,这里改改那里修修.我们先试着添加自己喜欢的marker/nft进行识别. 比如我做了一个法拉利的marker: 还有网上找了一个法拉利log ...
- OpenCV特征点检测------ORB特征
OpenCV特征点检测------ORB特征 ORB是是ORiented Brief的简称.ORB的描述在下面文章中: Ethan Rublee and Vincent Rabaud and Kurt ...
- ORB特征点检测
Oriented FAST and Rotated BRIEF www.cnblogs.com/ronny 这篇文章我们将介绍一种新的具有局部不变性的特征 -- ORB特征,从它的名字中可以看出它 ...
- python实现gabor滤波器提取纹理特征 提取指静脉纹理特征 指静脉切割代码
参考博客:https://blog.csdn.net/xue_wenyuan/article/details/51533953 https://blog.csdn.net/jinshengtao/ar ...
- SLAM: Orb_SLAM中的ORB特征
原文链接:什么是ORB 关于Orb特征的获取:参考 最新版的OpenCV中新增加的ORB特征的使用 ORB是是ORiented Brief 的简称,对Brief的特定性质进行了改进. ORB的描述在下 ...
- OpenCV特征点检测——ORB特征
ORB算法 目录(?)[+] 什么是ORB 如何解决旋转不变性 如何解决对噪声敏感的问题 关于尺度不变性 关于计算速度 关于性能 Related posts 什么是ORB 七 4 Ye ...
- OpenCV开发笔记(六十五):红胖子8分钟带你深入了解ORB特征点(图文并茂+浅显易懂+程序源码)
若该文为原创文章,未经允许不得转载原博主博客地址:https://blog.csdn.net/qq21497936原博主博客导航:https://blog.csdn.net/qq21497936/ar ...
- (三)ORB特征匹配
ORBSLAM2匹配方法流程 在基于特征点的视觉SLAM系统中,特征匹配是数据关联最重要的方法.特征匹配为后端优化提供初值信息,也为前端提供较好的里程计信息,可见,若特征匹配出现问题,则整个视觉SLA ...
随机推荐
- flume 启动,停止,重启脚本
#!/bin/bash #echo "begin start flume..." #flume的安装根目录(根据自己情况,修改为自己的安装目录) path=/sysware/apa ...
- L155
Wireless Festival has been given permission to remain in London's Finsbury Park, provided performers ...
- inet_pton函数和inet_ntop函数的用法及简单实现
http://blog.csdn.net/eagle51/article/details/53157643?utm_source=itdadao&utm_medium=referral 这两个 ...
- SDP协议简述
SDP协议也是文本协议,只需要按照协议本身的格式填充.SDP协议格式即详细信息如下: 会话描述 格式及举例 v=(protocol version) v=0 o=(owner/creator and ...
- 将海康大华等网络摄像机RTSP流进行网页Flash rtmp和H5 hls直播的技术方案
前言 再小的技术点也会有他的市场! 一直以来,都有一些不被看好,认为是成本太高,无法大规模展开的软件和产品形态,就好比每一座城市都会有他的著名小吃一样,即使是慕名而来的人源源不断,受众群体也总是有限, ...
- javascript 小代码
if(!("a" in window)){ var a =1; } alert(a); //undefined var a = 1,b=function a (x){ x & ...
- HDU - 1142:A Walk Through the Forest (拓扑排序)
Jimmy experiences a lot of stress at work these days, especially since his accident made working dif ...
- linux自学(六)之开始centos学习,更换yum源
上一篇:linux自学(五)之开始centos学习,Xshell远程连接 1. 备份原来的yum源 cp /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repo ...
- AngularX 路由总结
路由是 Angular 应用程序的核心,它加载与所请求路由相关联的组件,以及获取特定路由的相关数据.这允许我们通过控制不同的路由,获取不同的数据,从而渲染不同的页面. Installing the r ...
- BZOJ4557 JLoi2016 侦察守卫 【树形DP】*
BZOJ4557 JLoi2016 侦察守卫 Description 小R和B神正在玩一款游戏.这款游戏的地图由N个点和N-1条无向边组成,每条无向边连接两个点,且地图是连通的.换句话说,游戏的地图是 ...