Storm-源码分析- Disruptor在storm中的使用
Disruptor 2.0, (http://ifeve.com/disruptor-2-change/)
Disruptor为了更便于使用, 在2.0做了比较大的调整, 比较突出的是更换了几乎所有的概念名
老版本,

新版本,

从左到右的变化如下,
1. Producer –> Publisher
2. ProducerBarrier被integrate到RingBuffer里面, 叫做PublishPort, 提供publish接口
3. Entry –> Event
4, Cursor封装成Sequence, 其实Sequence就是将cursor+pading封装一下
5. Consumer –> EventProcesser
6. ConsumerBarrier 变为DependencyBarrier, 或SequenceBarrier
并且对于publisher和EventProcesser, 存在ClaimStrategy和WaitStrategy
对于publisher的ClaimStrategy, 由于publisher需要先claim到sequencer才能publish: SingleThreadedClaimStrategy, MultiThreadedClaimStrategy, 应该是对于singlethread不需要使用CAS更为高效
对于EventProcesser的WaitStrategy, 当取不到数据的时候采用什么样的策略进行等待: BlockingWaitStrategy, BusySpinWaitStrategy, SleepingWaitStrategy, YieldingWaitStrategy
Blocking就是同步加锁, BusySpin就是忙等耗CPU, 都比较低效
Yielding就是调用thread.yeild(), 把线程的从可执行状态调整成就绪装, 意思我先息下, 你们忙你们先来, 就是把CPU让给其他的线程, 但是yeild并不保证过多久线程被执行, 如果没有其他线程, 可能会被立即执行
而sleep, 会强制线程休眠指定时间, 然后再重新调度
DisruptorQueue.java
static final Object FLUSH_CACHE = new Object(); //特殊对象, 当consumer取到时, 触发cache queue的flush
static final Object INTERRUPT = new Object(); //特殊对象, 当consumer取到时, 触发InterruptedException RingBuffer<MutableObject> _buffer; //Disruptor的主要的数据结构RingBuffer
Sequence _consumer; //consumer读取序号
SequenceBarrier _barrier; //用于consumer监听RingBuffer的序号情况 // TODO: consider having a threadlocal cache of this variable to speed up reads?
volatile boolean consumerStartedFlag = false; //标志consumer是否start, 由于需要在change后其他线程可以马上知道, 所以使用volatile
ConcurrentLinkedQueue<Object> _cache = new ConcurrentLinkedQueue(); //当consumer没有start的时候, cache event的queue
ConcurrentLinkedQueue, 使用CAS而非lock来实现的线程安全队列, 具体参考(http://blog.sina.com.cn/s/blog_5efa3473010129pj.html)
首先声明一组变量, 部分会在构造函数中被初始化
最重要的结构就是RingBuffer, 这是个模板类, 这里从ObjectEventFactory()的实现也可以看出来, 初始化的时候在ringbuffer的每个entry上都创建一个MutableObject对象
MutableObject的实现很简单, 这是封装了object o, 为什么要做这层封装?
为了避免Java GC, 对于RingBuffer一旦初始化好, 上面的所有的MutableObject都不会被释放, 你只是去对object o, set不同的值
_buffer = new RingBuffer<MutableObject>(new ObjectEventFactory(), claim, wait);
public static class ObjectEventFactory implements EventFactory<MutableObject> {
@Override
public MutableObject newInstance() {
return new MutableObject();
}
}
public class MutableObject {
Object o = null;
}
Publish
Publish过程, 可见当前ProducerBarrier已经被集成到RingBuffer里面, 所以直接调用_buffer的接口
首先调用next, claim序号
取出序号上的MutableObject, 并将输入obj set
最后, publish当前序号, 表示consumer可以读取
当consumer没有start时, 会将obj cache在_cache中, 而不会放到ringbuffer中 (我没有想明白why? 为何要使用低效的链表queue来cache, 而不直接放到ringbuffer里面)
public void publish(Object obj, boolean block) throws InsufficientCapacityException {
if(consumerStartedFlag) {
final long id;
if(block) {
id = _buffer.next();
} else {
id = _buffer.tryNext(1);
}
final MutableObject m = _buffer.get(id);
m.setObject(obj);
_buffer.publish(id);
} else {
_cache.add(obj);
if(consumerStartedFlag) flushCache();
}
}
Consume
consume的过程, 这里实现的时Batch consume, 即给定Cursor, 会一直consume到该cursor为止
_consumer代表当前已经被consume的序号, 所以从_consumer.get() + 1开始读
取出MutableObject中的o, 并将MutableObject 清空
根据o的情况, 3种情况,
1. 如果是FLUSH_CACHE对象, 将cache中的event读出调用handler.onEvent
2. 如果是INTERRUPT对象, 触发InterruptedException
3. 正常情况, 直接调用handler.onEvent处理该o, curr == cursor判断表示batch是否结束, 当读到cursor的时候结束
最终将_consumer置为cursor, 表示已经读到cursor位置
private void consumeBatchToCursor(long cursor, EventHandler<Object> handler) {
for(long curr = _consumer.get() + 1; curr <= cursor; curr++) {
try {
MutableObject mo = _buffer.get(curr);
Object o = mo.o;
mo.setObject(null);
if(o==FLUSH_CACHE) {
Object c = null;
while(true) {
c = _cache.poll();
if(c==null) break;
else handler.onEvent(c, curr, true);
}
} else if(o==INTERRUPT) {
throw new InterruptedException("Disruptor processing interrupted");
} else {
handler.onEvent(o, curr, curr == cursor);
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
//TODO: only set this if the consumer cursor has changed?
_consumer.set(cursor);
}
backtype.storm.disruptor.clj
创建DisruptorQueue, 选用MultiThreadedClaimStrategy和BlockingWaitStrategy
(defnk disruptor-queue [buffer-size :claim-strategy :multi-threaded :wait-strategy :block]
(DisruptorQueue. ((CLAIM-STRATEGY claim-strategy) buffer-size)
(mk-wait-strategy wait-strategy)
))
并封装一系列Java接口
最重要的工作是, 启动consume-loop
这里ret是closeover了一个间隔为0的不停执行(consume-batch-when-available queue handler) 的线程, 而consumeBatchWhenAvailable的实现就是不停的sleep并调用consumeBatchToCursor
并且通过consumer-started!通知其他线程consumer已经start
(defnk consume-loop* [^DisruptorQueue queue handler :kill-fn (fn [error] (halt-process! 1 "Async loop died!"))
:thread-name nil]
(let [ret (async-loop
(fn []
(consume-batch-when-available queue handler)
0 )
:kill-fn kill-fn
:thread-name thread-name
)]
(consumer-started! queue)
ret
)) (defmacro consume-loop [queue & handler-args]
`(let [handler# (handler ~@handler-args)]
(consume-loop* ~queue handler#)
))
看看async-loop实现什么功能?
返回reify实现的record, 其中closeover了thread
这个thread主要就是死循环的执行传入的afn, 并且以afn的返回值作为执行间隔
主要功能, 异步的loop, 开启新的线程来执行loop, 而不是在当前主线程, 并且提供了sleep设置
;; afn returns amount of time to sleep
(defnk async-loop [afn
:daemon false
:kill-fn (fn [error] (halt-process! 1 "Async loop died!"))
:priority Thread/NORM_PRIORITY
:factory? false
:start true
:thread-name nil]
(let [thread (Thread.
(fn []
(try-cause
(let [afn (if factory? (afn) afn)]
(loop []
(let [sleep-time (afn)]
(when-not (nil? sleep-time)
(sleep-secs sleep-time)
(recur))
)))
(catch InterruptedException e
(log-message "Async loop interrupted!")
)
(catch Throwable t
(log-error t "Async loop died!")
(kill-fn t)
))
))]
(.setDaemon thread daemon)
(.setPriority thread priority)
(when thread-name
(.setName thread (str (.getName thread) "-" thread-name)))
(when start
(.start thread))
;; should return object that supports stop, interrupt, join, and waiting?
(reify SmartThread
(start [this]
(.start thread))
(join [this]
(.join thread))
(interrupt [this]
(.interrupt thread))
(sleeping? [this]
(Time/isThreadWaiting thread)
))
))
Storm在Worker中executors线程间通信, 如何使用Disruptor的?
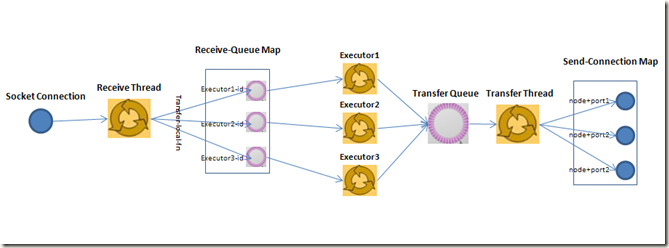
Understanding the Internal Message Buffers of Storm, 可以参考
Storm-源码分析- Disruptor在storm中的使用的更多相关文章
- Storm源码分析--Nimbus-data
nimbus-datastorm-core/backtype/storm/nimbus.clj (defn nimbus-data [conf inimbus] (let [forced-schedu ...
- JStorm与Storm源码分析(四)--均衡调度器,EvenScheduler
EvenScheduler同DefaultScheduler一样,同样实现了IScheduler接口, 由下面代码可以看出: (ns backtype.storm.scheduler.EvenSche ...
- JStorm与Storm源码分析(一)--nimbus-data
Nimbus里定义了一些共享数据结构,比如nimbus-data. nimbus-data结构里定义了很多公用的数据,请看下面代码: (defn nimbus-data [conf inimbus] ...
- JStorm与Storm源码分析(三)--Scheduler,调度器
Scheduler作为Storm的调度器,负责为Topology分配可用资源. Storm提供了IScheduler接口,用户可以通过实现该接口来自定义Scheduler. 其定义如下: public ...
- JStorm与Storm源码分析(二)--任务分配,assignment
mk-assignments主要功能就是产生Executor与节点+端口的对应关系,将Executor分配到某个节点的某个端口上,以及进行相应的调度处理.代码注释如下: ;;参数nimbus为nimb ...
- storm源码分析之任务分配--task assignment
在"storm源码分析之topology提交过程"一文最后,submitTopologyWithOpts函数调用了mk-assignments函数.该函数的主要功能就是进行topo ...
- Hbase源码分析:Hbase UI中Requests Per Second的具体含义
Hbase源码分析:Hbase UI中Requests Per Second的具体含义 让运维加监控,被问到Requests Per Second(见下图)的具体含义是什么?我一时竟回答不上来,虽然大 ...
- Android多线程之(一)View.post()源码分析——在子线程中更新UI
提起View.post(),相信不少童鞋一点都不陌生,它用得最多的有两个功能,使用简便而且实用: 1)在子线程中更新UI.从子线程中切换到主线程更新UI,不需要额外new一个Handler实例来实现. ...
- ABP源码分析二:ABP中配置的注册和初始化
一般来说,ASP.NET Web应用程序的第一个执行的方法是Global.asax下定义的Start方法.执行这个方法前HttpApplication 实例必须存在,也就是说其构造函数的执行必然是完成 ...
- 【源码分析】- 在SpringBoot中你会使用REST风格处理请求吗?
目录 前言 1.什么是 REST 风格 1.1 资源(Resources) 1.2 表现层(Representation) 1.3 状态转化(State Transfer) 1.4 综述 ...
随机推荐
- iTunes历史各个版本下载地址
地址:http://www.oldapps.com/itunes.php
- FreeRTOS 任务计数信号量,任务二值信号量,任务事件标志组,任务消息邮箱
以下基础内容转载自安富莱电子: http://forum.armfly.com/forum.php 本章节为大家讲解 FreeRTOS 计数信号量的另一种实现方式----基于任务通知(Task Not ...
- Excel关闭事件
记录一下,弄VBA曾经遇到一个需求,遇到用到这个事件,找了很久,最后还是问别人才知道的. Sub Auto_Close() ThisWorkbook.Saved = True End Sub
- am335x 内核频率 ddr3频率 电压调整
由Makefile可知,SPL的入口在u-boot-2011.09-psp04.06.00.08\arch\arm\cpu\armv7\start.S中 SPL的功能无非是设置MPU的Clock.PL ...
- python的zipfile实现文件目录解压缩
主要是 解决了压缩目录下 空文件夹 的压缩 和 解压缩问题 压缩文件夹的函数: # coding:utf- import os import zipfile def zipdir(dirToZip,s ...
- sql 追踪 神器
http://www.thinkphp.cn/download/690.html 一个中国人开发的php工具箱此工具能几秒钟追踪出sql 数据库操作, 能分析出 Thinkphp3.2 的任意sql ...
- 关于对象序列化json 说说
下面一个json格式图(说一下,json 其实就是js 数组和对象的一种字符串表现形式 var obj=[] 或者var obj={} ) var json= {} 如下 从图中看 json中有两个 ...
- Deep learning for Human Strategic Behaviour
没看,但是论文UI和视频做的很好. 论文地址:https://papers.nips.cc/paper/6509-deep-learning-for-predicting-human-strategi ...
- imx6 uboot logo 更改
最近需要更改im6 uboot的开机logo,使用10.1inch, 1024x600,18bit的LCD,期间遇到了很多的问题,记录于此. 参考链接 https://community.nxp.co ...
- Unity基于DFGUI的TreeView设计
using UnityEngine; using System.Collections; public class Item { public string Id; public string Nam ...