HashMap实现原理及常见问题
1.简介
HashMap是基于哈希表的Map接口的实现,用来存放键值对(Entry<Key,Value>),并提供可选的映射操作。使用put(Key,Value)存储对象到HashMap中,使用get(Key)从hashMap中获取对象。
2.底层结构
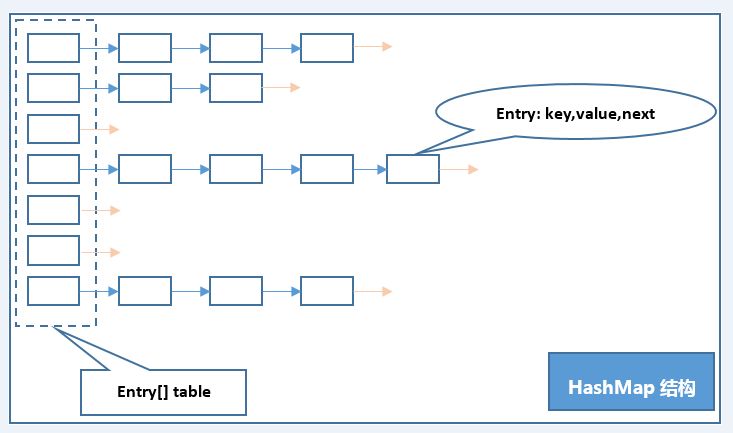
HashMap的底层是由数组加链表实现的,是一个哈希桶,因为对链表头部进行增删操作,所以也称为栈式链结构。链表由 Entry<Key,Value>对象作为结点,我们把存储该链表的数组位置称之为桶,那么桶数量就等于数组的长度。存放数据时时通过key的hashCode来计算hash,得到的hash作为数组的索引(也就是桶位置)存放对象,当hashCode相同时,则称之为哈希冲突,也可称为“碰撞”。此时通过“拉链法”解决冲突。
//Entry源码
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next; Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
} public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
补充:在jdk1.8版本之后,在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
3.原理分析
下面由存取数据的过程进行原理分析:
(1) put(key,value)
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
从这里我们可以看出hash方法对Key调用HashCode()方法,将得到的哈希值高16位不变,高16位与低16位进行异或运算。这样的目的是通过对哈希值的扰动,尽可能减少碰撞的发生。
此时的哈希值还不能作为数组的索引来存放数据,最后还会对扰动后的hash与(数组长度-1)进行取模运算,即(n - 1) & hash 这里n为数组长度,假设n为16 那么(n-1)的二进制为1111,将之与hash进行与位运算,1111截取hash后四位,并保证只是截取操作,截取后的hash与截取前的hash后四位相同,这就保证最后得到的hash能作为索引使数据在数组长度内尽可能均匀分布,减少碰撞,这种方式和hash%n取余的结果差不多又不太一样,通俗点将,取模操作要求n-1的二进制是111...都是1这种形式,也就必须要求n的值必须为2的次幂,这也解释了为什么HashMap规定数组的长度必须是2的次幂的原因。
重复上述:使用put方法传递 Entry<Key,Value>时,会对Key计算hash索引,先判断数组table[hash]是否为null,若为null 则入 Entry<Key,Value>,若不为空,就说明发生了碰撞,此时要存入的Entry对象的Key和桶中的Entry对象的Key的hash相同,但是它们可能并不相等,所以会调用equals方法将要存入的Key与桶中的Key一一比对,若均不相等,则存入 Entry(头插入法),如果相等,会覆盖原来的Entry.这种解决碰撞的方式就是前面所说的“拉链法”。
通过对存储过程的原理分析,那获取数据就简单了,在调用get(Key)方法时,同样计算Key的hash,通过计算好的hash找到桶位置,然后遍历链表通过key.equals方法直到找到Value值。
常见问题
(1)关于扩容:
loadfactor: 默认0.75f,代表桶填充程度,loadFactor越趋近于1,那么数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,导致查找元素效率低,loadFactor越趋近于0,数组的利用率越低,存放的数据会很分散。loadFactor的默认值为0.75f是官方给出的一个比较好的临界值。
capacity: 数组长度,必须为2的次幂,默认为16。hashMap构造中可指定初始长度,会通过一个算法转化成2的次幂
threshold: threshold = capacity * loadFactor,当entry的数量>=threshold的时候,那么就要考虑对数组的扩容了,这个的意思就是 衡量数组是否需要扩增的一个标准,扩容后,会重新对所有数据进行重新计算,重新存放,这个过程叫做rehash。
//HashMap保证数组长度为2的次幂的算法
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
(2)HashMap与HashTable主要区别为不支持同步和允许null作为key和value,所以如果你想要保证线程安全,可以使用ConcurrentHashMap代替而不是线程安全的HashTable,因为HashTable基本已经被淘汰。
(3)如果两个线程都发现HashMap需要调整大小,它们会同时尝试调整大小,在这个过程中,存储在链表中的元素次序会反过来,因为移动到新的桶位置的时候,hashMap并不会将元素放在尾部,而是放在头部,这是为了避免尾部遍历,如果条件竞争发生,会发生死循环.(注:jdk1.8已经解决了死循环的问题。)
HashMap实现原理及常见问题的更多相关文章
- HashMap实现原理及源码分析
哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常出 ...
- 【JDK源码分析】浅谈HashMap的原理
这篇文章给出了这样的一道面试题: 在 HashMap 中存放的一系列键值对,其中键为某个我们自定义的类型.放入 HashMap 后,我们在外部把某一个 key 的属性进行更改,然后我们再用这个 key ...
- HashMap的原理与实 无锁队列的实现Java HashMap的死循环 red black tree
http://www.cnblogs.com/fornever/archive/2011/12/02/2270692.html https://zh.wikipedia.org/wiki/%E7%BA ...
- JVM里面hashtable和hashmap实现原理
JVM里面hashtable和hashmap实现原理 文章分类:Java编程 转载 在hashtable和hashmap是java里面常见的容器类, 是Java.uitl包下面的类, 那么Hash ...
- 基础进阶(一)之HashMap实现原理分析
HashMap实现原理分析 1. HashMap的数据结构 数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端. 数组 数组存储区间是连续的,占用内存严重,故空间复杂的很大.但数组的二 ...
- Java HashMap工作原理及实现
Java HashMap工作原理及实现 2016/03/20 | 分类: 基础技术 | 0 条评论 | 标签: HASHMAP 分享到:3 原文出处: Yikun 1. 概述 从本文你可以学习到: 什 ...
- 再谈angularJS数据绑定机制及背后原理—angularJS常见问题总结
这篇是对angularJS的一些疑点回顾,是对目前angularJS开发的各种常见问题的整理汇总.如果对文中的题目全部了然于胸,觉得对整个angular框架应该掌握的七七八八了.希望志同道合的通知补充 ...
- HashMap实现原理和源码解析
哈希表(hash table)也叫散列表,是一种非常重要的数据结构.许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,本文会对java集合框架中的对应实现HashMap的 ...
- HashMap实现原理及源码分析(JDK1.7)
转载:https://www.cnblogs.com/chengxiao/p/6059914.html 哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技 ...
随机推荐
- bzoj 1430: 小猴打架
1430: 小猴打架 Time Limit: 5 Sec Memory Limit: 162 MBSubmit: 634 Solved: 461[Submit][Status][Discuss] ...
- STL在算法比赛中简单应用
STL基础 和 简单的贪心问题 STL(Standard Template Library) 即 标准模板库. 它包含了诸多在计算机科学领域里所常用的基本数据结构和算法.这些数据结构可以与标准算法一起 ...
- Python学习笔记(四十一)— 内置模块(10)urllib
摘抄自:https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/001432688314 ...
- 几种不同程序语言的HMM版本
几种不同程序语言的HMM版本 “纸上得来终觉浅,绝知此事要躬行”,在继续翻译<HMM学习最佳范例>之前,这里先补充几个不同程序语言实现的HMM版本,主要参考了维基百科.读者有兴趣的话可以研 ...
- 重构改善既有代码设计--重构手法16:Introduce Foreign Method (引入外加函数)&& 重构手法17:Introduce Local Extension (引入本地扩展)
重构手法16:Introduce Foreign Method (引入外加函数)你需要为提供服务的类增加一个函数,但你无法修改这个类.在客户类中建立一个函数,并以第一参数形式传入一个服务类实例. 动机 ...
- spring bean初始化及销毁你必须要掌握的回调方法
spring bean在初始化和销毁的时候我们可以触发一些自定义的回调操作. 初始化的时候实现的方法 1.通过java提供的@PostConstruct注解: 2.通过实现spring提供的Initi ...
- ASP.NET站点Web部署(一键发布的实现)
在开发过程中经常需要发布到开发环境.测试环境或者预发布环境上给其他同事进行测试验证效果等等,每次发布都要备份,拷贝,修改配置文件等等重复操作非常的麻烦,效率大打折扣,而web部署提供了这样的解决方案: ...
- [php]手动搭建php开发环境(排错)
前提:针对自己的系统下载相应的php.apache.mysql,安装完毕后按照以下去配置httpd.conf和php.ini 本人用的是php5.6.4和apache2.4.4 一.Apache : ...
- 【51nod】1238 最小公倍数之和 V3 杜教筛
[题意]给定n,求Σi=1~nΣj=1~n lcm(i,j),n<=10^10. [算法]杜教筛 [题解]就因为写了这个非常规写法,我折腾了3天…… $$ans=\sum_{i=1}^{n}\s ...
- Masquerade strikes back Gym - 101911D(补题) 数学
https://vjudge.net/problem/Gym-101911D 具体思路: 对于每一个数,假设当前的数是10 分解 4次,首先 1 10 这是一对,然后下一次就记录 10 1,这样的话直 ...