《深入理解Spark-核心思想与源码分析》(六)第六章计算引擎
RDD是Spark对各类数据计算模型的统一抽象,被用于迭代计算过程以及任务输出结果的缓存读写。
在所有MapReduce框架中,shuffle是连接map任务和reduce任务的桥梁。shuffle性能优劣直接决定了
整个计算引擎的性能和吞吐量。
6.1 迭代计算
MappedRDD的iterator方法
6.2 什么是shuffle
shuffle是所有MapReduce计算框架所必须经过的阶段,shuffle用于打通map任务的输出与reduce任务的输入,
map任务的中间输出结果按照key值哈希后分配给某一个reduce任务。
目前Spark的shuffle已经做了多种性能优化,主要解决方案包括:
1>将map任务输出的bucket(给每个partition的reduce)合并到同一个文件中,这解决了bucket数量很对多,但是本身数据体积不大
时,造成shuffle很频繁,磁盘I/O成为性能瓶颈的问题。
2>map任务逐条输出计算结果,而不是一次性输出到内存中,并使用缓存及其聚合算法对中间结果进行聚合,大大减小了中间结果所占的内存大小。
3>缓存溢出判断,超过大小时,将数据写入磁盘,防止内存溢出
4>reduce任务对拉取到的map任务中间结果逐条读取,而不是一次性读入内存,并在内存中使用聚合和排序,大大减少了数据占用内存
5>reduce任务将要拉取的Block按照BlockManager地址划分,然后将同一BlockManager地址中的Block累计为少量网络请求,减少网络I/O
6.3 map端计算结果缓存处理
首先理解两个概念:
bypassMergeThreshold:传递到reduce端再做merge操作的阈值。默认200
bypassMergeSort:标记是否传递到reduce端再做合并和排序
map端计算结果缓存有三种处理方式:
1.map端对计算结果在缓存中执行聚合和排序。
2.map不适用缓存,也不执行聚合和排序,直接调用spillToPartitionFiles将各个partition直接写到自己存储文件,
最后由reduce端对计算结果执行合并和排序。
3.map端对计算结果简单缓存。
6.3.1 map端结算结果缓存聚合
在一个任务的分区数量通常很多,如果只是简单地将数据存储到Executor上。在执行reduce任务时会存在大量的网络I/O操作。
这时网络I/O将成为系统性能的瓶颈,reduce任务读取map任务的计算结果变慢,导致其他任务不得不选择分配到更远的节点。
通过在map端对计算结果在缓存中执行聚合和排序,能够节省I/O操作,进而提升系统性能。
6.3.2 map端计算结果简单缓存
6.3.3 容量限制
AppendOnlyMap和SizeTrackingPairBuffer的容量都可以增长,那么数据量不大的时候不会有问题。
由于大数据处理的数据量往往都比较大,全部都放入内存内会将系统内存撑爆,Spark为了防止这个问题,
提供函数maybeSpillConllection。
6.4 map端计算结果持久化
wirtePartitionFile用于持久化计算结果。
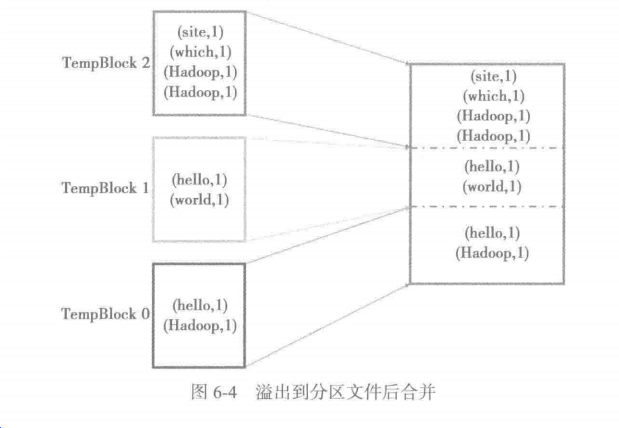
1.溢出到分区文件后合并:将内存中缓存的多个partition的计算结果分别写入临时Block文件,再将这些Block文件的内容全部写入到Block输出文件中。
2.内存中排序合并:将缓存的中间计算结果按照partition分组后写入Block输出文件。
6.4.1 溢出分区文件
每个map任务实际最后只会生成一个磁盘文件。
6.4.2 排序与分区分组
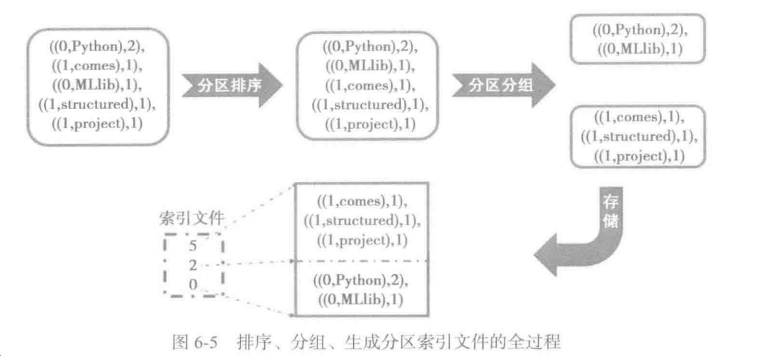
partitionedIterator 通过对集合按照指定的比较器进行比较,按照partition id分组,生成迭代器。
6.4.3 分区索引文件
6.5 reduce端读取中间计算结果
6.5.1 获取map任务状态
6.5.2 划分本地与远程Block
6.5.3 获取远程Block
sendRequest方法用于远程请求中间结果。
sendRequest利用FetchRequest里封装的BlockId、size、address等信息。
调用shuffleClient的fetchBlocks方法获取其他节点上的中间结果。
6.5.4 获取本地Block
fetchLocalBlock用于对本地中间计算结果的获取。
6.6 reduce端计算
6.6.1 如何同时处理多个map任务的中间结果
6.6.2 reduce端在缓存中对中间计算结果执行聚合和排序
6.7 map端和reduce端组合分析
6.7.1 在map端溢出分区文件,在reduce端合并组合

6.7.2 在map端简单缓存、排序分组,在reduce端合并组合

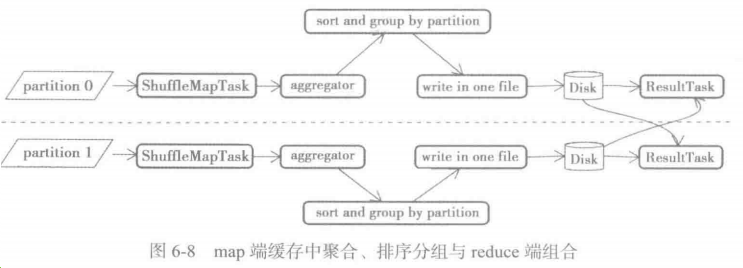
6.7.3 在map端缓存中聚合、排序分组,在reduce端组合
6.8 小结
本章从迭代计算的层层剥离开始,分析了map和reduce任务的处理逻辑。
《深入理解Spark-核心思想与源码分析》(六)第六章计算引擎的更多相关文章
- 《深入理解Spark:核心思想与源码分析》——SparkContext的初始化(叔篇)——TaskScheduler的启动
<深入理解Spark:核心思想与源码分析>一书前言的内容请看链接<深入理解SPARK:核心思想与源码分析>一书正式出版上市 <深入理解Spark:核心思想与源码分析> ...
- 《深入理解Spark:核心思想与源码分析》(前言及第1章)
自己牺牲了7个月的周末和下班空闲时间,通过研究Spark源码和原理,总结整理的<深入理解Spark:核心思想与源码分析>一书现在已经正式出版上市,目前亚马逊.京东.当当.天猫等网站均有销售 ...
- 《深入理解Spark:核心思想与源码分析》(第2章)
<深入理解Spark:核心思想与源码分析>一书前言的内容请看链接<深入理解SPARK:核心思想与源码分析>一书正式出版上市 <深入理解Spark:核心思想与源码分析> ...
- 《深入理解Spark:核心思想与源码分析》一书正式出版上市
自己牺牲了7个月的周末和下班空闲时间,通过研究Spark源码和原理,总结整理的<深入理解Spark:核心思想与源码分析>一书现在已经正式出版上市,目前亚马逊.京东.当当.天猫等网站均有销售 ...
- 《深入理解Spark:核心思想与源码分析》正式出版上市
自己牺牲了7个月的周末和下班空闲时间,通过研究Spark源码和原理,总结整理的<深入理解Spark:核心思想与源码分析>一书现在已经正式出版上市,目前亚马逊.京东.当当.天猫等网站均有销售 ...
- 《深入理解Spark-核心思想与源码分析》(一)总体规划和第一章环境准备
<深入理解Spark 核心思想与源码分析> 耿嘉安著 本书共计486页,计划每天读书20页,计划25天完成. 2018-12-20 1-20页 凡事豫则立,不豫则废:言前定,则不跲:事 ...
- spark的存储系统--BlockManager源码分析
spark的存储系统--BlockManager源码分析 根据之前的一系列分析,我们对spark作业从创建到调度分发,到执行,最后结果回传driver的过程有了一个大概的了解.但是在分析源码的过程中也 ...
- Android源码分析(十六)----adb shell 命令进行OTA升级
一: 进入shell命令界面 adb shell 二:创建目录/cache/recovery mkdir /cache/recovery 如果系统中已有此目录,则会提示已存在. 三: 修改文件夹权限 ...
- 手机自动化测试:appium源码分析之bootstrap六
手机自动化测试:appium源码分析之bootstrap六 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.poptest测试 ...
随机推荐
- WAMP允许外部访问的修改方法
apache配置文件httpd.conf里的 "Require local"改" Require all granted"
- android ViewPager之OnPageChangeListener接口
项目中在使用ViewPager的时候,一般都要在界面滑动的时候做一些事情,android中有个专门的状态回调接口OnPageChangeListener. /** * Callback interfa ...
- Callback2.0
Callback定义? a callback is a piece of executable code that is passed as an argument to other code, wh ...
- 安装Docker-ce
Docker Engine改为Docker CE(社区版) 它包含了CLI客户端.后台进程/服务以及API.用户像以前以同样的方式获取.Docker Data Center改为Docker EE(企业 ...
- [Leetcode] Sum 系列
Sum 系列题解 Two Sum题解 题目来源:https://leetcode.com/problems/two-sum/description/ Description Given an arra ...
- linux 内核信号量
Linux内核的信号量在概念和原理上和用户态的System V的IPC机制信号量是相同的,不过他绝不可能在内核之外使用,因此他和System V的IPC机制信号量毫不相干. 信号量在创建时需要设置一个 ...
- 15个你不得不知道的Chrome dev tools的小技巧
转载自:https://www.imooc.com/article/2559 谷歌浏览器如今是Web开发者们所使用的最流行的网页浏览器.伴随每六个星期一次的发布周期和不断扩大的强大的开发功能,Chro ...
- SPOJ DQUERY D-query (在线主席树/ 离线树状数组)
版权声明:本文为博主原创文章,未经博主允许不得转载. SPOJ DQUERY 题意: 给出一串数,询问[L,R]区间中有多少个不同的数 . 解法: 关键是查询到某个右端点时,使其左边出现过的数都记录在 ...
- Nginx源码分析--epoll模块
Nginx采用epoll模块实现高并发的网络编程,现在对Nginx的epoll模块进行分析. 定义在src/event/modules/ngx_epoll_module.c中 1. epoll_cre ...
- ireport报表制作, 当一个字段显示的数据太多时(数据过长),则需要自动换行
1.当一个字段显示的数据太长,一个表格放不下,则需要自动换行,选中要更改的表格(要显示动态内容的字段),设置属性Stretch with overflow 为钩选状态. 未勾选之前: 勾选之后: 2. ...