hadoop之 hadoop用途方向
- hadoop是什么?
Hadoop是一个开源的框架,可编写和运行分不是应用处理大规模数据,是专为离线和大规模数据分析而设计的,并不适合那种对几个记录随机读写的在线事务处理模式。Hadoop=HDFS(文件系统,数据存储技术相关)+ Mapreduce(数据处理),Hadoop的数据来源可以是任何形式,在处理半结构化和非结构化数据上与关系型数据库相比有更好的性能,具有更灵活的处理能力,不管任何数据形式最终会转化为key/value,key/value是基本数据单元。用函数式变成Mapreduce代替SQL,SQL是查询语句,而Mapreduce则是使用脚本和代码,而对于适用于关系型数据库,习惯SQL的Hadoop有开源工具hive代替。 - hadoop能做什么?
hadoop擅长日志分析,facebook就用Hive来进行日志分析,2009年时facebook就有非编程人员的30%的人使用HiveQL进行数据分析;淘宝搜索中的自定义筛选也使用的Hive;利用Pig还可以做高级的数据处理,包括Twitter、LinkedIn 上用于发现您可能认识的人,可以实现类似Amazon.com的协同过滤的推荐效果。淘宝的商品推荐也是!在Yahoo!的40%的Hadoop作业是用pig运行的,包括垃圾邮件的识别和过滤,还有用户特征建模。(2012年8月25新更新,天猫的推荐系统是hive,少量尝试mahout!) - hadoop能为我司做什么?
- 大数据量存储:分布式存储
- 日志处理: Hadoop擅长这个
- 海量计算: 并行计算
- ETL:数据抽取到oracle、mysql、DB2、mongdb及主流数据库
- 使用HBase做数据分析: 用扩展性应对大量的写操作—Facebook构建了基于HBase的实时数据分析系统
- 机器学习: 比如Apache Mahout项目
- 搜索引擎:hadoop + lucene实现
- 数据挖掘:目前比较流行的广告推荐
- 大量地从文件中顺序读。HDFS对顺序读进行了优化,代价是对于随机的访问负载较高。
- 数据支持一次写入,多次读取。对于已经形成的数据的更新不支持。
- 数据不进行本地缓存(文件很大,且顺序读没有局部性)
- 任何一台服务器都有可能失效,需要通过大量的数据复制使得性能不会受到大的影响。
- 用户细分特征建模
- 个性化广告推荐
- 智能仪器推荐
hadoop实际应用:
Hadoop+HBase建立NoSQL分布式数据库应用
Flume+Hadoop+Hive建立离线日志分析系统
Flume+Logstash+Kafka+Spark Streaming进行实时日志处理分析
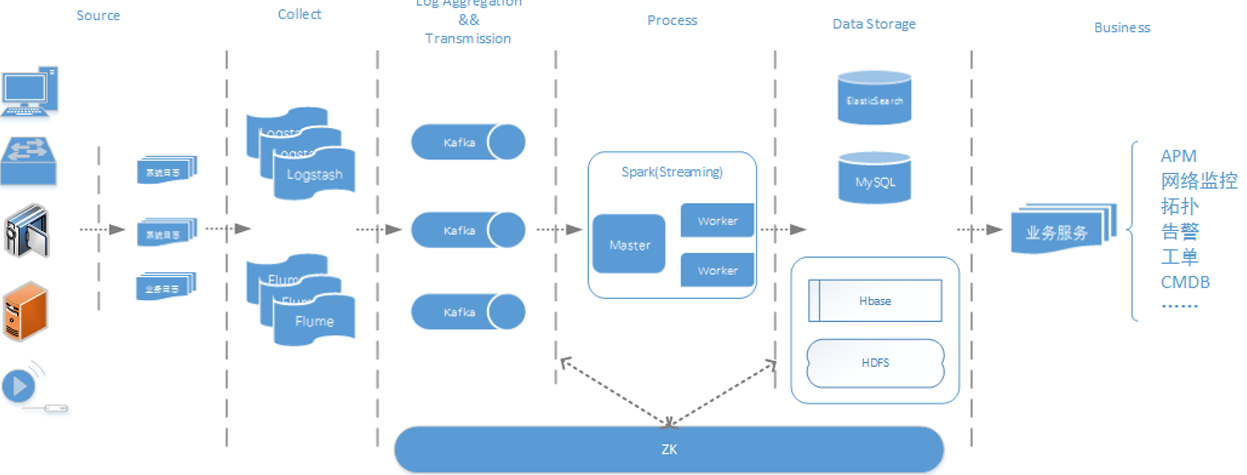
酷狗音乐的大数据平台
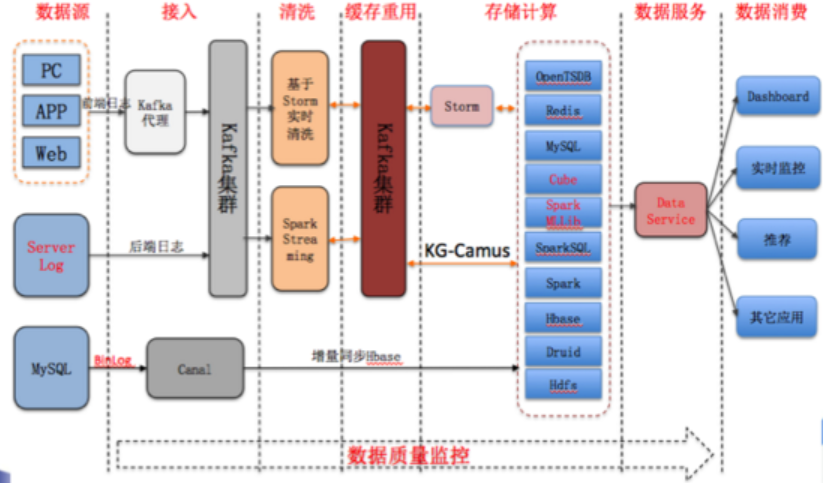
京东的智能供应链预测系统
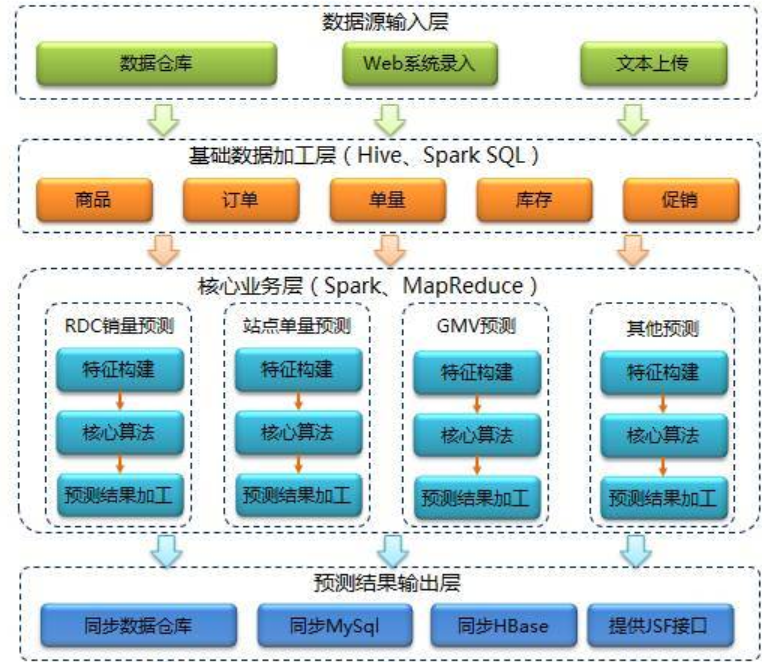
说明:整理于网络
http://www.cnblogs.com/zhangs1986/p/6528227.html
http://blog.sina.com.cn/s/blog_687194cd01017lgu.html
hadoop之 hadoop用途方向的更多相关文章
- Hadoop(初始Hadoop)
Hadoop核心组件 1.Hadoop生态系统 Hadoop具有以下特性: 方便:Hadoop运行在由一般商用机器构成的大型集群上,或者云计算服务上 健壮:Hadoop致力于在一般商用硬件上运行,其架 ...
- Hadoop: Hadoop Cluster配置文件
Hadoop配置文件 Hadoop的配置文件: 只读的默认配置文件:core-default.xml, hdfs-default.xml, yarn-default.xml 和 mapred-defa ...
- [Linux][Hadoop] 将hadoop跑起来
前面安装过程待补充,安装完成hadoop安装之后,开始执行相关命令,让hadoop跑起来 使用命令启动所有服务: hadoop@ubuntu:/usr/local/gz/hadoop-$ ./sb ...
- Hadoop:搭建hadoop集群
操作系统环境准备: 准备几台服务器(我这里是三台虚拟机): linux ubuntu 14.04 server x64(下载地址:http://releases.ubuntu.com/14.04.2/ ...
- [Hadoop 周边] Hadoop资料收集【转】
原文网址: http://www.iteblog.com/archives/851 最直接的学习参考网站当然是官网啦: http://hadoop.apache.org/ Hadoop http:// ...
- [Hadoop 周边] Hadoop和大数据:60款顶级大数据开源工具(2015-10-27)【转】
说到处理大数据的工具,普通的开源解决方案(尤其是Apache Hadoop)堪称中流砥柱.弗雷斯特调研公司的分析师Mike Gualtieri最近预测,在接下来几年,“100%的大公司”会采用Hado ...
- hadoop数据[Hadoop] 实际应用场景之 - 阿里
上班之余抽点时间出来写写博文,希望对新接触的朋友有帮助.明天在这里和大家一起学习一下hadoop数据 Hadoop在淘宝和支付宝的应用从09年开始,用于对海量数据的离线处置,例如对日志的分析,也涉及内 ...
- Hadoop:Hadoop单机伪分布式的安装和配置
http://blog.csdn.net/pipisorry/article/details/51623195 因为lz的linux系统已经安装好了很多开发环境,可能下面的步骤有遗漏. 之前是在doc ...
- Hadoop:hadoop fs、hadoop dfs与hdfs dfs命令的区别
http://blog.csdn.net/pipisorry/article/details/51340838 'Hadoop DFS'和'Hadoop FS'的区别 While exploring ...
- Hadoop:Hadoop基本命令
http://blog.csdn.net/pipisorry/article/details/51223877 常用命令 启用hadoop start-dfs.sh start-hbase.sh 停止 ...
随机推荐
- cJONS序列化工具解读三(使用案例)
cJSON使用案例 由了解了cJSON的数据结构,接口以及实现之后,那么我们来举例说明其使用. 本例子是一个简单的学生信息表格管理,我们通过键值对的方式向json中增加元素信息. 然后可以格式化输出结 ...
- idea中修改git提交代码的用户名
1.原因:刚进入这家公司,给同事交接完,直接使用他的电脑,每次提交代码都显示他的用户名,本以为是电脑系统名称呢,可是修改了之后没有效果 2.解决方案: 打开C盘里的 .gitconfig文件 看下gi ...
- 聊一聊Spring AOP
前两天,在给新入职的同事做技术介绍时,讲到spring的AOP.使我又一次认识到,对于AOP,特别是spring AOP的理解,虽然大家都能说上来几句,但是许多人认识并不太全面,甚至可以说是一知半解- ...
- 51nod-1574-排列转换
1574 排列转换 题目来源: CodeForces 基准时间限制:1 秒 空间限制:131072 KB 分值: 40 难度:4级算法题 收藏 关注 现在有两个长度为n的排列p和s.要求通过交换 ...
- yii控制布局方式
1:在控制器内成员变量设置 public $layout = false; //不使用布局 public $layout = “main”; //设置使用的布局文件 2:在控制器成员方法内设置 $th ...
- Python之路,Day9 - 线程、进程、协程和IO多路复用
参考博客: 线程.进程.协程: http://www.cnblogs.com/wupeiqi/articles/5040827.html http://www.cnblogs.com/alex3714 ...
- js自定义对象.属性 笔记
<一> js自定义对象 一,概述 在Java语言中,我们可以定义自己的类,并根据这些类创建对象来使用,在Javascript中,我们也可以定义自己的类,例如定义User类.Hashtabl ...
- c#批量上传图片到服务器示例分享
这篇文章主要介绍了c#批量上传图片到服务器示例,服务器端需要设置图片存储的虚拟目录,需要的朋友可以参考下 /// <summary> /// 批量上传图片 /// </summary ...
- New Concept English three (22)
34w 54 Some plays are so successful that they run for years on end. In many ways, this is unfortunat ...
- New Concept English three(10)
The great ship, Titanic, sailed for New York from Southampton on April 10th, 1912. She was carrying ...